This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its because the foundational principle of data-centric AI is straightforward: a model is only as good as the data it learns from. No matter how advanced an algorithm is, noisy, biased, or insufficient data can bottleneck its potential. Why is this the case?
Two of the most important concepts underlying this area of study are concept drift vs datadrift. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy. An example of how datadrift may occur is in the context of changing mobile usage patterns over time.
tweaktown.com Research Researchers unveil time series deep learning technique for optimal performance in AI models A team of researchers has unveiled a time series machine learning technique designed to address datadrift challenges. techxplore.com Are deepfakes illegal?
Like any large tech company, data is the backbone of the Uber platform. Not surprisingly, data quality and drifting is incredibly important. Many datadrift error translates into poor performance of ML models which are not detected until the models have ran. TheSequence is a reader-supported publication.
In this process, the AI system's training data, model parameters, and algorithms are updated and improved based on input generated from within the system. Model Drift: The model’s predictive capabilities and efficiency decrease over time due to changing real-world environments. Let’s discuss this in more detail.
Primary activities AIOps relies on big data-driven analytics , ML algorithms and other AI-driven techniques to continuously track and analyze ITOps data. Based on those metrics, MLOps technologies continuously update ML models to correct performance issues and incorporate changes in data patterns.
Baseline job datadrift: If the trained model passes the validation steps, baseline stats are generated for this trained model version to enable monitoring and the parallel branch steps are run to generate the baseline for the model quality check. Monitoring (datadrift) – The datadrift branch runs whenever there is a payload present.
This is the reason why data scientists need to be actively involved in this stage as they need to try out different algorithms and parameter combinations. This is not ideal because data distribution is prone to change in the real world which results in degradation in the model’s predictive power, this is what you call datadrift.
DataRobot DataDrift and Accuracy Monitoring detects when reality differs from the situation when the training dataset was created and the model trained. Meanwhile, DataRobot can continuously train Challenger models based on more up-to-date data. Autoscaling Deployments with MLOps.
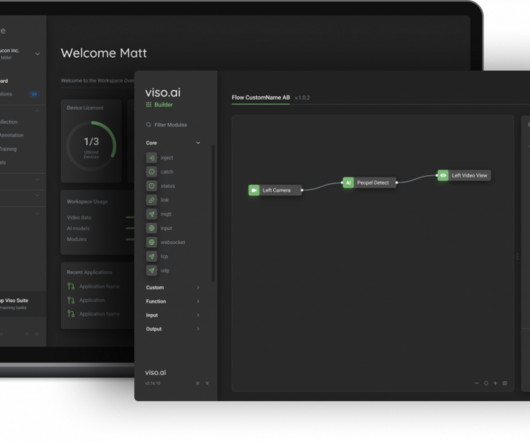
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
On the other hand, you might be building a click-through rate prediction model like Google and training that model on every single data point as it streams into the system, which is extremely complicated from an infrastructure and algorithmic perspective. That’s the datadrift problem, aka the performance drift problem.
No Free Lunch Theorem: Any two algorithms are equivalent when their performance is averaged across all possible problems. Monitoring Models in Production There are several types of problems that Machine Learning applications can encounter over time [4]: Datadrift: sudden changes in the features values or changes in data distribution.
However, the data in the real world is constantly changing, and this can affect the accuracy of the model. This is known as datadrift, and it can lead to incorrect predictions and poor performance. In this blog post, we will discuss how to detect datadrift using the Python library TorchDrift.
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
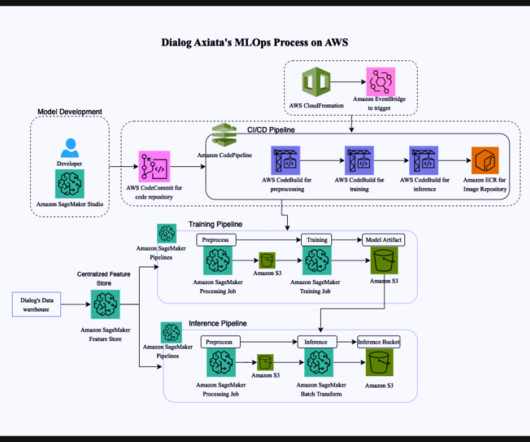
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Concurrently, the ensemble model strategically combines the strengths of various algorithms. The incorporation of an experiment tracking system facilitates the monitoring of performance metrics, enabling a data-driven approach to decision-making. Datadrift and model drift are also monitored.
Long-term ML project involves developing and sustaining applications or systems that leverage machine learning models, algorithms, and techniques. An example of a long-term ML project will be a bank fraud detection system powered by ML models and algorithms for pattern recognition. 2 Ensuring and maintaining high-quality data.
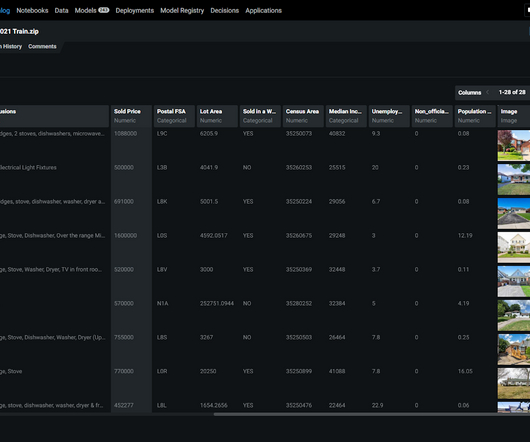
Describing the data As mentioned before, we will be using the data provided by Corporación Favorita in Kaggle. After deployment, we will monitor the model performance with the current best model and check for datadrift and model drift. Apart from that, we must constantly monitor the data as well.
Conduct exploratory analysis and data preparation. Determine the ML algorithm, if known or possible. Improve model accuracy: In-depth feature engineering (example, PCA) Hyperparameter optimization (HPO) Quality assurance and validation with test data. Monitoring setup (model, datadrift).
The ML platform can utilize historic customer engagement data, also called “clickstream data”, and transform it into features essential for the success of the search platform. From an algorithmic perspective, Learning To Rank (LeToR) and Elastic Search are some of the most popular algorithms used to build a Seach system.
Machine learning models are only as good as the data they are trained on. Even with the most advanced neural network architectures, if the training data is flawed, the model will suffer. Data issues like label errors, outliers, duplicates, datadrift, and low-quality examples significantly hamper model performance.
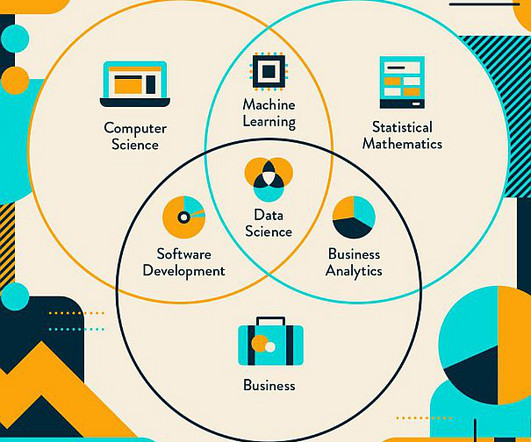
Data science is a multidisciplinary field that relies on scientific methods, statistics, and Artificial Intelligence (AI) algorithms to extract knowledgable and meaningful insights from data. At its core, data science is all about discovering useful patterns in data and presenting them to tell a story or make informed decisions.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
These tools provide valuable information on the relationships between features and predictions, enabling data scientists to make informed decisions when fine-tuning and improving their models. The algorithm blueprint, including all steps taken, can be viewed for each item on the leaderboard.
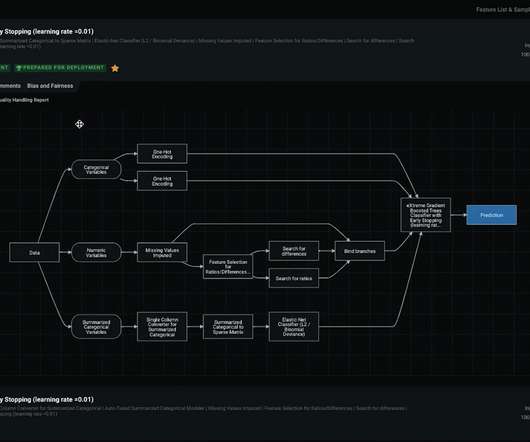
You can see the entire process from data to predictions with all of the different steps—as well as the supportive documentation on every stage and an automated compliance report, which is very important for highly regulated industries. DataRobot Blueprint—from data to predictions. Generate Model Compliance Documentation.
The model learns from the input data and adjusts its internal parameters to make predictions or classifications based on the provided training examples. This may involve monitoring datadrift, retraining the model periodically, and updating the model as new data becomes available or business requirements change.
Therefore, to do face recognition, the algorithm often runs face verification. For ECG data they applied a mapping algorithm from activities to effort levels and a lightweight CNN architecture. 2022) published their research Lightweight Vehicle-Pedestrian Detection Algorithm Based on Attention Mechanism in Traffic Scenarios.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. Advanced algorithms recognize patterns in temporal data effectively. Key Takeaways AI automates complex forecasting processes for improved efficiency.
This means building hundreds of features for hundreds of machine learning algorithms—this approach to feature engineering is neither scalable nor cost-effective. In contrast, DataRobot simplifies the feature engineering process by automating the discovery and extraction of relevant explanatory variables from multiple related data sources.
To address this problem, an automated fraud detection and alerting system was developed using insurance claims data. The system used advanced analytics and mostly classic machine learning algorithms to identify patterns and anomalies in claims data that may indicate fraudulent activity.
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deep learning algorithms to forecast sales, predict customer churn and fraud detection, etc., Data science practitioners experiment with algorithms, data, and hyperparameters to develop a model that generates business insights.
Before manipulating the data, we also need to clean the data, which requires eliminating any duplicate entries, dropping irrelevant data, and identifying erroneous data. This helps to improve data accuracy and reliability for ML algorithms. Maintain version control of your ETL code base.
Artificial Intelligence (AI) models assist across various domains, from regression-based forecasting models to complex object detection algorithms in deep learning. Continuous Improvement: Data scientists face many issues after model deployment like performance degradation, datadrift, etc.
Due to this, businesses are now focusing on an ML-based approach, where different ML algorithms are trained on a large dataset of prelabeled text. These algorithms not only focus on the word but also its context in different scenarios and relation with other words. are used to classify the text sentiment.
Monitoring Monitor model performance for datadrift and model degradation, often using automated monitoring tools. Optimization: Use database optimizations like approximate nearest neighbor ( ANN ) search algorithms to balance speed and accuracy in retrieval tasks.
When AI algorithms, pre-trained models, and data sets are available for public use and experimentation, creative AI applications emerge as a community of volunteer enthusiasts builds upon existing work and accelerates the development of practical AI solutions. Morgan and Spotify.
I wasn’t surprised by these responses as they are commonly cited, and also of course because the data challenge is our organization’s reason for being. When it comes to data challenges, LXT can both source data and label it so that machine learning algorithms can make sense of it.
This would enable developers worldwide to thoroughly examine, analyze, and improve AI, particularly focusing on training data and processes. To successfully bring transparency to AI, we must understand the decision-making algorithms that underpin it, thereby unraveling AI’s “black box” approach.
So we had what was called “algorithms”, I could say beverage minute, where essentially you could get up for a couple of minutes and kind of talk about things. Piotr: Sounds like something with data, right? Datadrift. Stefan: Yeah, datadrift, something upstream, et cetera.
A lot of the assumptions that you make that these algorithms are based on, when they go to the real world, they don't hold, and then you have to figure out how to deal with that. I think that a lot of the difference is that, one, engineering, safety and so on, and maybe the other one of course is that your assumptions don't hold.
Elements of a machine learning pipeline Some pipelines will provide high-level abstractions for these components through three elements: Transformer : an algorithm able to transform one dataset into another. Estimator : an algorithm trained on a dataset to produce a transformer. Data preprocessing. Model deployment.
This vision is embraced by conversational interfaces which allow humans to interact with data using language, our most intuitive and universal channel of communication. After parsing a question, an algorithm encodes it into a structured logical form in the query language of choice, such as SQL. in the data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content