This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI emotion recognition is a very active current field of computer vision research that involves facial emotion detection and the automatic assessment of sentiment from visual data and text analysis. This solution enables leading companies to build, deploy, and scale their AI vision applications, including AI emotion analysis.
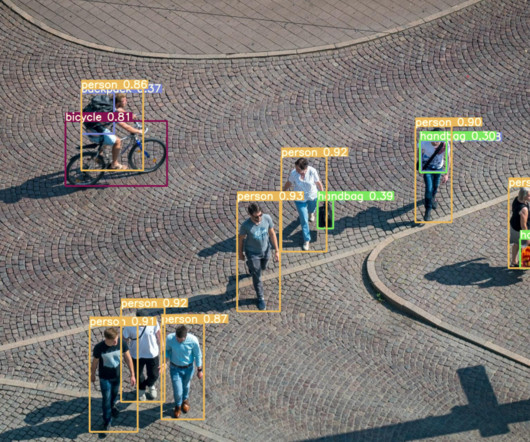
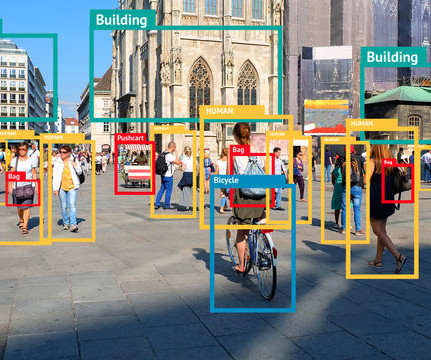
The YOLOv7 algorithm is making big waves in the computer vision and machine learning communities. In this article, we will provide the basics of how YOLOv7 works and what makes it the best object detector algorithm available today. The original YOLO object detector was first released in 2016. higher AP (average precision).
YOLO (You Only Look Once) is a family of real-time object detection machine-learning algorithms. Object detection is a computer vision task that uses neuralnetworks to localize and classify objects in images. The YOLO approach is to apply a single convolutionalneuralnetwork (CNN) to the full image.
It gives the computer the ability to observe and learn from visual data just like humans. Modeling representations of facial expressions by detecting facial landmarks [ Source ] A model is trained to first identify regions of interest from visual images. and applies this learning tosolving problems.
We’ll explore the key AI technologies that enable them, examine real-world applications, and a hands-on tutorial for obstacle detection. About us : Viso Suite is the end-to-end platform for building, deploying, and scaling visualAI. Following are some of those algorithms.
Discriminative The story of Generative AI is not only about its applications but fundamentally about its inner workings. These algorithms take input data, such as a text or an image, and pair it with a target output, like a word translation or medical diagnosis. Discriminative models are what most people encounter in daily life.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content