This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction: Clustering is an unsupervised learning method whose task is to. The post KModes Clustering Algorithm for Categorical data appeared first on Analytics Vidhya.
Introduction In the bustling world of machinelearning, categorical data is like the DNA of our datasets – essential yet complex. But how do we make this data comprehensible to our algorithms? Enter One Hot Encoding, the transformative process that turns categorical variables into a language that machines understand.
Introduction “Data is the fuel for MachineLearningalgorithms” Real-world. The post How to Handle Missing Values of Categorical Variables? ArticleVideo Book This article was published as a part of the Data Science Blogathon. appeared first on Analytics Vidhya.
Introduction If enthusiastic learners want to learn data science and machinelearning, they should learn the boosted family. There are a lot of algorithms that come from the family of Boosted, such as AdaBoost, Gradient Boosting, XGBoost, and many more.
One of the biggest challenges is handling categorical attributes while dealing with datasets. In this article, we will delve into the world of auditing data, anomaly detection, and the impact of encoding categorical attributes on models. Introduction The world of auditing data can be complex, with many challenges to overcome.
Introduction Support vector machine is one of the most famous and decorated machinelearningalgorithms in classification problems. The heart and soul of this algorithm is the concept of Hyperplanes where these planes help to categorize the high dimensional data which are either […].
Brandwatch builds upon proprietary algorithms integrated with advanced language models, creating a system that processes social media conversations with depth. This system processes vast datasets of creator content and engagement metrics, utilizing AI to match brands with relevant influencers based on pattern recognition algorithms.
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning? temperature, salary).
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machinelearning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
This crucial step involves cleaning and organizing your data and preparing it for your machine-learning models. Data preprocessing prepares your data before feeding it into your machine-learning models.” Think of it as prepping ingredients before cooking. The process is fundamental to the machinelearning pipeline.
One often encounters datasets with categorical variables in data analysis and machinelearning. However, many machinelearningalgorithms require numerical input. These variables represent qualitative attributes rather than numerical values. This is where label encoding comes into play.
This story explores CatBoost, a powerful machine-learningalgorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. But what if we could predict a student’s engagement level before they begin?
In today’s world, you’ve probably heard the term “MachineLearning” more than once. MachineLearning, a subset of Artificial Intelligence, has emerged as a transformative force, empowering machines to learn from data and make intelligent decisions without explicit programming. housing prices, stock prices).
In case you’re not interested in the Python articles, go to settings and turn off notifications for “AI & Python” (leave the rest the same to keep receiving my other emails) Machinelearning (ML) is the field behind all the magic in AI products. Here’s a brief explanation in plain English. Subscribe now 1.
As data scientists and machinelearning engineers, we spend the majority of our time working with data. In machinelearning, the path from raw data to a well-tuned model is paved with preprocessing techniques that set the way for success. It is important that we master it! The header image was created by the author.
Machinelearning (ML)—the artificial intelligence (AI) subfield in which machineslearn from datasets and past experiences by recognizing patterns and generating predictions—is a $21 billion global industry projected to become a $209 billion industry by 2029.
Based on this, it makes an educated guess about the importance of incoming emails, and categorizes them into specific folders. In addition to the smart categorization of emails, SaneBox also comes with a feature named SaneBlackHole, designed to banish unwanted emails.
Created by the author with DALL E-3 R has become very ideal for GIS, especially for GIS machinelearning as it has topnotch libraries that can perform geospatial computation. R has simplified the most complex task of geospatial machinelearning. Advantages of Using R for MachineLearning 1.
Photo by Helena Lopes on Unsplash Before getting into MachineLearning Project Series — Part II, Click Here to see MachineLearning Project Series — Part I. Data Pre-Processing Handling Missing Values Encoding Categorical Variables Feature Scaling Data Splitting (Training and Validation) 4. Table of Contents 1.
Data scientists and engineers frequently collaborate on machinelearning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To minimize the possibility of mistakes, the user must repeat and check each step of the machine-learning workflow.
One of the major focuses over the years of AutoML is the hyperparameter search problem, where the model implements an array of optimization methods to determine the best performing hyperparameters in a large hyperparameter space for a particular machinelearning model. ai, IBM Watson AI, Microsoft AzureML, and a lot more.
Photo by Markus Winkler on Unsplash Let’s get started: MachineLearning has become the most demanding and powerful tool in different domains of several industries in this digital era to solve many complex problems by revolutionizing the way of approaching those problems.
techspot.com Applied use cases Study employs deep learning to explain extreme events Identifying the underlying cause of extreme events such as floods, heavy downpours or tornados is immensely difficult and can take a concerted effort by scientists over several decades to arrive at feasible physical explanations. "I'll get more," he added.
Recent studies have addressed this gap by introducing benchmarks that evaluate AI agents on various software engineering and machinelearning tasks. Furthermore, these frameworks often lack flexibility in assessing diverse research outputs, such as novel algorithms, model architectures, or predictions.
Beginner’s Guide to ML-001: Introducing the Wonderful World of MachineLearning: An Introduction Everyone is using mobile or web applications which are based on one or other machinelearningalgorithms. You might be using machinelearningalgorithms from everything you see on OTT or everything you shop online.
From chatbots that handle customer requests around the clock to predictive algorithms that preempt system failures, AI is not just an add-on; it is becoming a necessity in tech. Types of AI in ITSM AI in ITSM can be categorized into three types: automation, chatbots, and predictive analysis. Nightmare, right?
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, K Nearest Neighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? You just want to create and analyze simple maps not to learn algebra all over again.
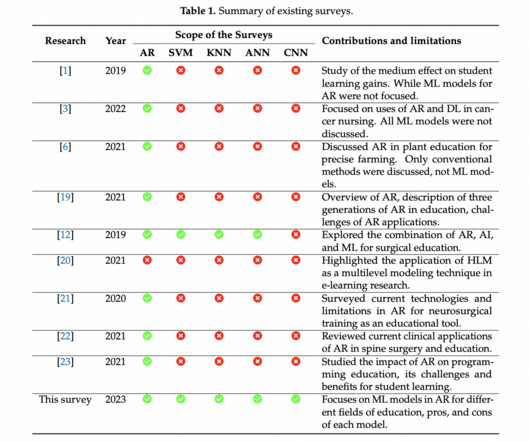
Survey on MachineLearning-Powered Augmented Reality in Education: ML advances augmented reality (AR) across various educational fields, enhancing object visualizations and interaction capabilities. It explores ML models like support vector machines, CNNs, and ANNs in AR education.
Recently, we posted the first article recapping our recent machinelearning survey. There, we talked about some of the results, such as what programming languages machinelearning practitioners use, what frameworks they use, and what areas of the field they’re interested in. As the chart shows, two major themes emerged.
As machinelearning advances, we see a big increase in their use for predicting time series data. The following article is an experimental study that uses both statistical forecasts and machinelearning-based forecasts to predict the future for a practical use case. This is why they’re top choices for future predictions.
Computer vision, machinelearning, and data analysis across many fields have all seen a surge in the usage of synthetic data in the past few years. Concerning tabular data, one of the biggest obstacles is maintaining consistency when dealing with fluctuating percentages of numerical and categorical data. Check out the Paper.
Summary: This comprehensive guide covers the basics of classification algorithms, key techniques like Logistic Regression and SVM, and advanced topics such as handling imbalanced datasets. It also includes practical implementation steps and discusses the future of classification in MachineLearning. What is Classification?
Automated MachineLearning has become essential in data-driven decision-making, allowing domain experts to use machinelearning without requiring considerable statistical knowledge. This innovative approach holds promise for revolutionizing the field of Automated MachineLearning.
The framework, enhanced with explore-exploit techniques, delivers results comparable to state-of-the-art Gaussian Process-based optimization algorithms. The algorithm was evaluated on various problems, including synthetic, combinatorial, and hyperparameter optimization tasks, with performance averaged over multiple runs.
Researchers investigating LLM security vulnerabilities have explored various jailbreak attack methodologies, categorized into Human-Design, Long-tail Encoding, and Prompt Optimization. Human design involves manually crafting prompts to exploit model weaknesses, such as role-playing or scenario crafting.
Ready Tensor conducted an extensive benchmarking study to evaluate the performance of 25 machinelearning models on five distinct datasets to improve time series step classification accuracy in their latest publication on Time Step Classification Benchmarking.
Numerous domains, such as web development, data research, machinelearning, automation, and scientific computing, heavily rely on Python. Its Python domain offers simple, medium, and hard challenges that are categorized for gradual learning.
By adopting technologies like artificial intelligence (AI) and machinelearning (ML), companies can give a boost to their customer segmentation efforts. For example, in the US, mortgage companies have been under fire for alleged racial profiling of their AI algorithms. Here’s a guide to help you accomplish that.
Artificial intelligence and machinelearning are two innovative leaders as the world benefits from technology’s draw to sectors globally. You choose your future when you select a machinelearning tool. We’ll look at some well-known machine-learning tools in this article.
This new technique leverages X-ray photon correlation spectroscopy (XPCS), artificial intelligence, and machinelearning to create “fingerprints” of different materials. Unsupervised machinelearningalgorithm A key component of this new approach is the use of an unsupervised machinelearningalgorithm.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests. This method takes a parameter, which we set to 3.
Are you overwhelmed by the recent progress in machinelearning and computer vision as a practitioner in academia or in the industry? Motivation Recent updates in machinelearning (ML) and computer vision (CV) are a mouthful, from Stable Diffusion for generative artificial intelligence (AI) to Segment Anything as foundation models.
A study demonstrated that quantum algorithms could accelerate the discovery of new materials by up to 100 times compared to classical methods. Enhanced MachineLearningalgorithms can uncover complex patterns in vast datasets. Quantum AI holds promise for breakthroughs in drug discovery and materials science.
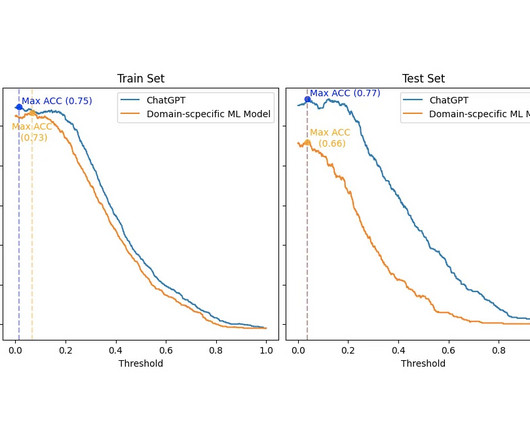
ChatGPT is a GPT ( G enerative P re-trained T ransformer) machinelearning (ML) tool that has surprised the world. So, to make a viable comparison, I had to: Categorize the dataset scores into Positive , Neutral , or Negative labels. GloVe) for usage in domain-specific tasks. First, I must be honest. The plots are below.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content