This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Brandwatch builds upon proprietary algorithms integrated with advanced language models, creating a system that processes social media conversations with depth. This system processes vast datasets of creator content and engagement metrics, utilizing AI to match brands with relevant influencers based on pattern recognition algorithms.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
AI can forecast demands and usage to notice potential clients through historical data and customer demographic information. It employs algorithms like usage patterns, historical data and peak hour surges to improve bandwidth by analyzing demands and optimizing services.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. But what if we could predict a student’s engagement level before they begin?
Akeneo is the product experience (PX) company and global leader in Product Information Management (PIM). How is AI transforming product information management (PIM) beyond just centralizing data? Akeneo is described as the “worlds first intelligent product cloud”what sets it apart from traditional PIM solutions?
AI-powered note-taking tools have revolutionized how we manage, structure, and access information. With AI-powered features like text recognition, content categorization, and smart search, Evernote ensures that users can quickly locate notes, even within images or scanned documents.
In the age of information overload, managing emails can be a daunting task. Based on this, it makes an educated guess about the importance of incoming emails, and categorizes them into specific folders. Its powerful AI capabilities allow it to understand and categorize emails, draft responses, and manage follow-ups efficiently.
This step involves cleaning your data, handling missing values, normalizing or scaling your data and encoding categorical variables into a format your algorithm can understand. Clean, well-prepped data is more manageable for algorithms to read and learn from, leading to more accurate predictions and better performance.
At its core, machine learning algorithms seek to identify patterns within data, enabling computers to learn and adapt to new information. Classification: Categorizing data into discrete classes (e.g., 2) Logistic regression Logistic regression is a classification algorithm used to model the probability of a binary outcome.
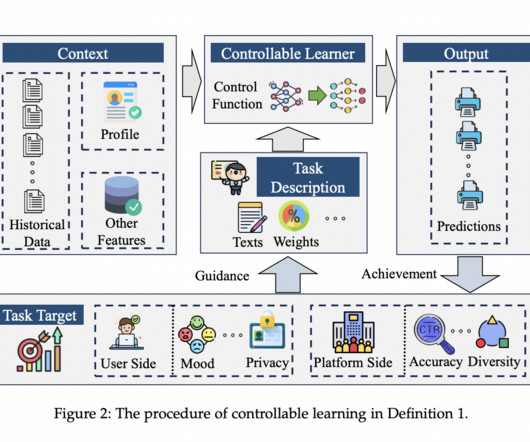
Let’s delve into the methods and applications of CL, particularly focusing on its implementation within Information Retrieval (IR) systems presented by researchers from Renmin University of China. Platform-Mediated Control Platform-mediated control involves algorithmic adjustments and policy-based constraints imposed by the platform.
Large language models (LLMs) have unlocked new possibilities for extracting information from unstructured text data. SageMaker JumpStart is a machine learning (ML) hub with foundation models (FMs), built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks.
Sentiment analysis to categorize mentions as positive, negative, or neutral. It uses natural language processing (NLP) algorithms to understand the context of conversations, meaning it's not just picking up random mentions! Clean and intuitive user interface that's easy to navigate. Easy reporting functionality. Is Brand24 free to use?
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies. Ethereum is a decentralized blockchain platform that upholds a shared ledger of information collaboratively using multiple nodes.
Leverage Action Module to carry out the task by using knowledge and tools to complete it, whether by delivering information or triggering an action. Source: UC Berkeley Types of AI Agents World Economic Forum has categorized AI agents into the following types: 1.
From chatbots that handle customer requests around the clock to predictive algorithms that preempt system failures, AI is not just an add-on; it is becoming a necessity in tech. Types of AI in ITSM AI in ITSM can be categorized into three types: automation, chatbots, and predictive analysis. ” That is really golden information.
Its Python domain offers simple, medium, and hard challenges that are categorized for gradual learning. By focussing on topics like algorithms, regex, string manipulation, and maths, each challenge enhances fundamental Python abilities.
This data is created algorithmically to mimic the characteristics of real-world data and can serve as an alternative or supplement to it. “A lot of research is going into developing more computationally efficient algorithms,” Smolinksi adds. But when you have constraints, you become more creative.”
These fingerprints can then be analyzed by a neural network, unveiling previously inaccessible information about material behavior. ” This scattering data provides a wealth of information about the material's structure and behavior, but the resulting patterns are incredibly complex. The AI is a pattern recognition expert.”
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests. A temperature of 0.0
Because its segmentation process is run only by data, we can then learn about customer segments that we hadn’t thought about, and this uncovers unique information about our customers. For example, in the US, mortgage companies have been under fire for alleged racial profiling of their AI algorithms.
Text mining —also called text data mining—is an advanced discipline within data science that uses natural language processing (NLP) , artificial intelligence (AI) and machine learning models, and data mining techniques to derive pertinent qualitative information from unstructured text data. positive, negative or neutral).
These limitations include: Reactive approaches, predominantly relying on human moderation and static algorithms, struggle to keep pace with the rapid dissemination of hate speech. It involves generating persuasive and informative content to promote empathy, understanding, and tolerance.
ML algorithms understand language in the NLU subprocesses and generate human language within the NLG subprocesses. Well-known examples of virtual assistants include Apple’s Siri, Amazon Alexa and Google Assistant, primarily used for personal assistance, home automation, and delivering user-specific information or services.
AI-powered research paper summarizers have emerged as powerful tools, leveraging advanced algorithms to condense lengthy documents into concise and readable summaries. By simply entering keywords, phrases, or questions, users can leverage Elicit's AI algorithms to search through its extensive database and retrieve the most pertinent papers.
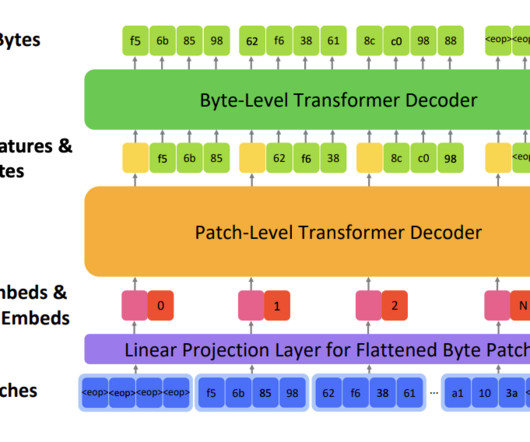
However, a vast portion of the digital world comprises binary data, the fundamental building block of all digital information, which still needs to be explored by current deep-learning models. bGPT’s training objectives span generative modeling, focusing on next-byte prediction and classification tasks that categorize byte sequences.
In the early days of online shopping, ecommerce brands were categorized as online stores or “multichannel” businesses operating both ecommerce sites and brick-and-mortar locations. But in a channel-less world, data should be used to inform more than FAQ pages, content marketing tactics and email campaigns.
In doing so, they equip stakeholders with the insights needed to remain abreast of regulatory changes and make well-informed decisions amidst the dynamic regulatory landscape. By leveraging historical data and machine learning algorithms, companies can forecast regulatory trends and proactively adapt their compliance processes accordingly.
They can provide valuable insights and forecasts to inform organizational decision-making in omnichannel commerce, enabling businesses to make more informed and data-driven decisions. Meanwhile, 43% are using the technology to inform strategic decisions. AI models analyze vast amounts of data quickly and accurately.
But, unlike humans, AGIs don’t experience fatigue or have biological needs and can constantly learn and process information at unimaginable speeds. Achieving these feats is accomplished through a combination of sophisticated algorithms, natural language processing (NLP) and computer science principles.
In just about any organization, the state of information quality is at the same low level – Olson, Data Quality Data is everywhere! Each topic is critical in transforming messy, real-world datasets into something your machine learning algorithms can genuinely learn from. Upgrade to access all of Medium.
The KGW Family modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary into a green list and a red list based on the preceding token. These watermarking techniques are mainly divided into two categories: the KGW Family and the Christ Family.
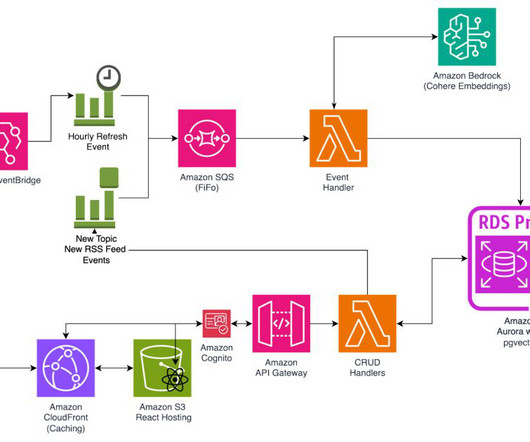
On our website, users can subscribe to an RSS feed and have an aggregated, categorized list of the new articles. However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions.
Advances in artificial intelligence and machine learning have led to the development of increasingly complex object detection algorithms, which allow us to efficiently and precisely interpret large volumes of geographical data. Another method for figuring out which category a detected object belongs to is object categorization.
For more information, see AWS managed policy: AmazonSageMakerCanvasAIServicesAccess. For more information, see Model access. Linear categorical to categorical correlation is not supported. Features that are not either numeric or categorical are ignored.
A study demonstrated that quantum algorithms could accelerate the discovery of new materials by up to 100 times compared to classical methods. Enhanced Machine Learning algorithms can uncover complex patterns in vast datasets. Unlike classical computers that use bits (0s and 1s) to process information, quantum computers use qubits.
Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. Let us look at how the K Nearest Neighbor algorithm can be applied to geospatial analysis. In other words, neighbors play a major part in our life.
There are major worries about data traceability and reproducibility because, unlike code, data modifications do not always provide enough information about the exact source data used to create the published data and the transformations made to each source. This information will then be indexed as part of a data catalog.
Similarly, involving AI in categorizing user actions, anticipating future behaviors, and distilling insights from vast amounts of user data allows designers to focus more of their attention and time on other aspects of the design process. identifying trends, mapping and optimizing user journeys and so on will become significantly easier.
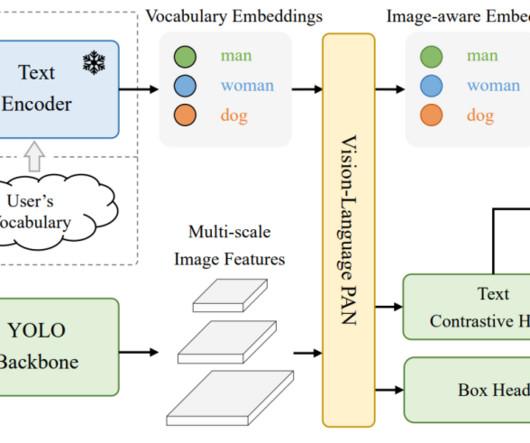
Specifically, YOLO-World employs a Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) and region-text contrastive loss to foster interaction between linguistic and visual information. These phrases are then fed to the text encoder.
Predicts Learning Outcomes An LMS can collect valuable information about the process, but you may need help picking up on the more complex patterns in the resulting data set. Algorithms are incredibly good at recognizing trends in data, meaning they typically come to accurate conclusions. It can even help with tedious daily duties.
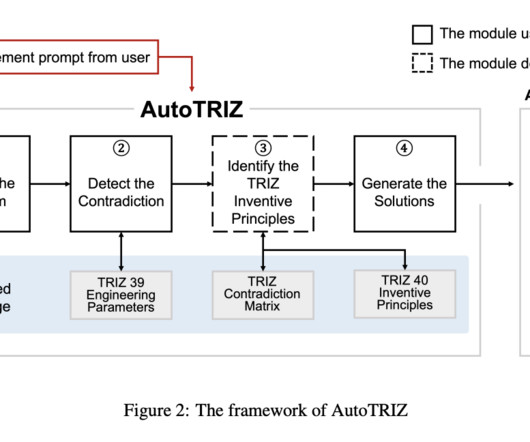
Systems like PAT-ANALYZER and PaTRIZ automatically extract contradictory information from patent texts. However, most of these works utilize algorithms to improve specific steps of the TRIZ process. Some other methods employ text-mining techniques for inventive problem formulation or map TRIZ principles to patents using topic modeling.
Currently chat bots are relying on rule-based systems or traditional machine learning algorithms (or models) to automate tasks and provide predefined responses to customer inquiries. While traditional AI approaches provide customers with quick service, they have their limitations.
Error tracking – Setting up alerts for critical errors and performing advanced error categorization and trend analysis helps us integrate seamlessly with our development workflow and maintain system integrity. This information is then seamlessly integrated into our Grafana dashboard for real-time visualization and analysis.
Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data. A foundation model is built on a neural network model architecture to process information much like the human brain does.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content