This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests.
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computer vision object detection algorithms. The recent deep learning algorithms provide robust person detection results. Detecting people in video streams is an important task in modern video surveillance systems.
Users can review different types of events such as security, connectivity, system, and management, each categorized by specific criteria like threat protection, LAN monitoring, and firmware updates. You are only allowed to output text in JSON format. Presently, his main area of focus is state-of-the-art natural language processing.
This distinction is essential for a variety of uses, such as building playlists for particular objectives, concentration, or relaxation, and even as a first step in language categorization for singing, which is crucial in marketplaces with numerous languages. Check out the Paper.
These variables often involve complex sequences of events, combinations of occurrences and non-occurrences, as well as detailed numeric calculations or categorizations that accurately reflect the diverse nature of patient experiences and medical histories.
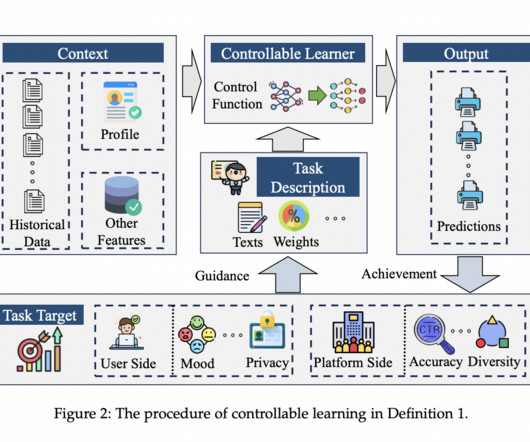
Definition and Importance of Controllable Learning Controllable Learning is formally defined as the ability of a learning system to adapt to various task requirements without requiring retraining. Platform-Mediated Control Platform-mediated control involves algorithmic adjustments and policy-based constraints imposed by the platform.
Pattern recognition is the ability of machines to identify patterns in data, and then use those patterns to make decisions or predictions using computer algorithms. The identification of regularities in data can then be used to make predictions, categorize information, and improve decision-making processes.
The AI Act takes a risk-based approach, meaning that it categorizes applications according to their potential risk to fundamental rights and safety. “The AI Act defines different rules and definitions for deployers, providers, importers. The European Union (EU) is the first major market to define new rules around AI.
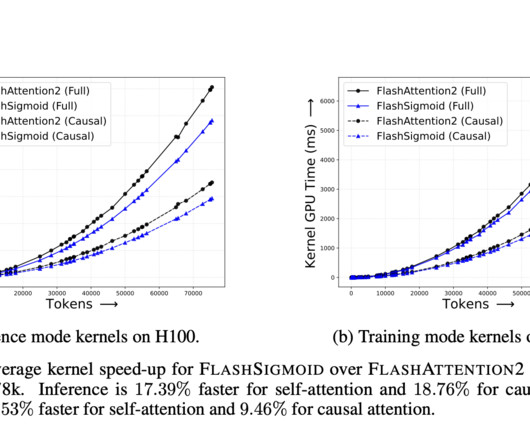
In supervised image classification and self-supervised learning, there’s a trend towards using richer pointwise Bernoulli conditionals parameterized by sigmoid functions, moving away from output conditional categorical distributions typically parameterized by softmax. Key observations from the empirical studies include: 1.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
Computer Vision Application for mango plant disease classification in Agriculture The need for AI to understand image data Since the vast amount of image data we obtain from cameras and sensors is unstructured, we depend on advanced techniques such as machine learning algorithms to analyze the images efficiently.
In ML, there are a variety of algorithms that can help solve problems. In graduate school, a course in AI will usually have a quick review of the core ML concepts (covered in a previous course) and then cover searching algorithms, game theory, Bayesian Networks, Markov Decision Processes (MDP), reinforcement learning, and more.
We can apply a data-centric approach by using AutoML or coding a custom test harness to evaluate many algorithms (say 20–30) on the dataset and then choose the top performers (perhaps top 3) for further study, being sure to give preference to simpler algorithms (Occam’s Razor).
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. They can search within specific categories to narrow down results.
Recently, we spoke with Pedro Domingos, Professor of computer science at the University of Washington, AI researcher, and author of “The Master Algorithm” book. In the interview, we talked about the quest for the “ultimate machine learning algorithm.” How close are we to a “Holy Grail,” aka the Ultimate Machine Learning Algorithm?
Traditionally, mathematical theorem proving has relied on tools like Lean , which train models on datasets such as Mathlib to solve problems using specific definitions and strategies. These properties were categorized by difficulty: easy (medley), medium (termination), and hard (sorting). success rate on medley properties.
This article offers a measured exploration of AI agents, examining their definition, evolution, types, real-world applications, and technical architecture. The Evolution of AI Agents Transition from Rule-Based Systems Early software systems relied on rule-based algorithms that worked well in controlled, predictable environments.
Generated with Bing and edited with Photoshop Predictive AI has been driving companies’ ROI for decades through advanced recommendation algorithms, risk assessment models, and fraud detection tools. The predictive AI algorithms can be used to predict a wide range of variables, including continuous variables (e.g.,
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. For more details, refer to the GitHub repo.
If you’re a grad student or a researcher, you should definitely have a look! Abhishek Thakur: A new ML algorithm came out? Think of if this channel as not only keeping up-to-date with new ML algorithms but also learning how to implement those and build projects! I like to think of Yannic’s channel as the BBC News of AI.
One of the most popular deep learning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al. Since then, the R-CNN algorithm has gone through numerous iterations, improving the algorithm with each new publication and outperforming traditional object detection algorithms (e.g.,
The most common techniques used for extractive summarization are term frequency-inverse document frequency (TF-IDF), sentence scoring, text rank algorithm, and supervised machine learning (ML). Use the evaluation algorithm with either built-in or custom datasets to evaluate your LLM model.
In this post, you will see how the TensorFlow image classification algorithm of Amazon SageMaker JumpStart can simplify the implementations required to address these questions. First, we introduce JumpStart and the built-in TensorFlow image classification algorithms. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
Text Classification : Categorizing text into predefined categories based on its content. It is used to automatically detect and categorize posts or comments into various groups such as ‘offensive’, ‘non-offensive’, ‘spam’, ‘promotional’, and others. Machine Translation : Translating text from one language to another. Still confused?
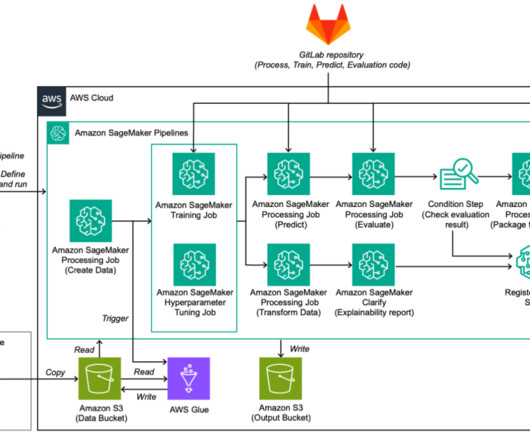
The Ranking team at Booking.com plays a pivotal role in ensuring that the search and recommendation algorithms are optimized to deliver the best results for their users. Explain – SageMaker Clarify generates an explainability report. Two distinct repositories are used.
Data annotation allows machine learning algorithms to understand and interpret information. AI algorithms use them as ground truths to adjust their weights accordingly. The labels are task-dependent and can be further categorized as an image or text annotation.
SageMaker JumpStart is a machine learning (ML) hub with foundation models (FMs), built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks. Intents are categorized into two levels: main intent and sub intent. The initial step involves identifying the intent or class of the user’s request or the document.
Python, R, SQL) Understand Machine Learning: Learn: Begin to dive a bit deeper by learning how to explore data with courses covering mathematics, statistics, probability, algorithms, and coding. Learn Machine Learning And Algorithms (Maths, Stats, Probability) Machine learning is based on data processing and exploration.
Summary: Entropy in Machine Learning quantifies uncertainty, driving better decision-making in algorithms. This blog aims to explore entropys theoretical foundations, practical applications, and impact on Machine Learning algorithms , guiding readers through its versatile applications in solving complex problems effectively.
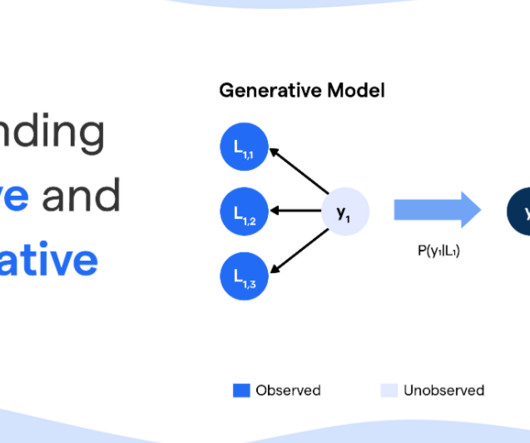
In this article, we will delve into the concepts of generative and discriminative models, exploring their definitions, working principles, and applications. Examples of Generative Models Generative models encompass various algorithms that capture patterns in data to generate realistic new examples.
They allow fast lookup to check if a word is spelled correctly or to retrieve its definition from a dictionary. Categorization and grouping Hash Tables can be used to categorize or group items based on certain attributes. Graph algorithms Hash Tables are often used in graph algorithms to store adjacency lists.
Key steps involve problem definition, data preparation, and algorithm selection. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data. Types of Machine Learning Machine Learning algorithms can be categorised based on how they learn and the data type they use.
EU AI Act: Definition of AI To begin with a neutral definition of AI is established with an aim to cover all AI (symbolic AI, Machine Learning, and Hybrid systems) and include techniques that are not yet known or developed. “ 2022 : Launch of first AI Regulatory Sandbox.
Developing predictive models using Machine Learning Algorithms will be a crucial part of your role, enabling you to forecast trends and outcomes. This might involve normalising data, scaling features, or encoding categorical variables. This phase entails meticulously selecting and training algorithms to ensure optimal performance.
The technology of AI has been categorized as narrow ai vs general, and super artificial intelligence. Narrow Artificial Intelligence algorithms can process a large amount of data and analyze it so fast. Ability to predict and adopt These three categories of AI detect patterns in the data by using algorithms.
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Some examples include scaling numeric values and one hot encoding categorical features. Our categorical pipeline also has two steps.
For example, you’ll be able to use the information that certain spans of text are definitely not PERSON entities, without having to provide the complete gold-standard annotations for the given example. spacy-dbpedia-spotlight Use DBpedia Spotlight to link entities ✍️ contextualSpellCheck Contextual spell correction using BERT ?
The Actor-Critic algorithm updates the policy using the TD (Temporal Difference) error. It is important because it provides a formal representation of the environment in terms of states, actions, transitions between states, and a reward function definition.
Parallel computing Parallel computing refers to carrying out multiple processes simultaneously, and can be categorized according to the granularity at which parallelism is supported by the hardware. In summary, the Neuron SDK allows developers to easily parallelize ML algorithms, such as those commonly found in FSI.
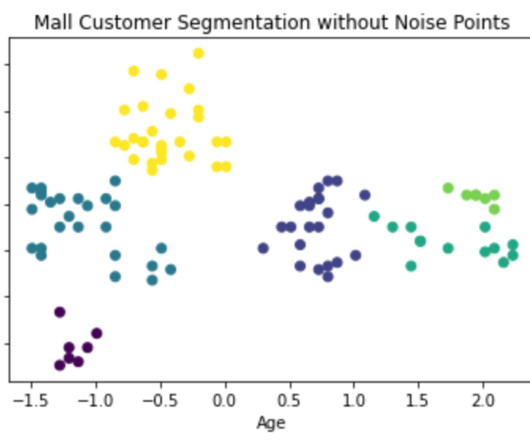
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Some examples include scaling numeric values and one hot encoding categorical features. Our categorical pipeline also has two steps.
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Some examples include scaling numeric values and one hot encoding categorical features. Our categorical pipeline also has two steps.
These reference guides condense complex concepts, algorithms, and commands into easy-to-understand formats. Expertise in mathematics and statistical fields is essential for deciding algorithms, drawing conclusions, and making predictions. Let’s delve into the world of cheat sheets and understand their importance.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content