This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categoricaldata effectively. But what if we could predict a student’s engagement level before they begin?
One of the most practical use cases of AI today is its ability to automate data standardization, enrichment, and validation processes to ensure accuracy and consistency across multiple channels. Leveraging customer data in this way allows AI algorithms to make broader connections across customer order history, preferences, etc.,
Consider these questions: Do you have a platform that combines statistical analyses, prescriptive analytics and optimization algorithms? Do you have purpose-built algorithms to improve intermittent and variable demand forecasting? Master data enrichment to enhance categorization and materials attributes.
” For example, synthetic data represents a promising way to address the data crisis. This data is created algorithmically to mimic the characteristics of real-world data and can serve as an alternative or supplement to it. In this context, dataquality often outweighs quantity.
In the past, the business relied on a conventional approach to segmentation, categorizing customers by geographic location, based on the underlying assumption that farmers from the same region would have similar needs. In those cases, a traditional approach run by humans can work better, especially if you mainly have qualitative data.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
A Comprehensive Data Science Guide to Preprocessing for Success: From Missing Data to Imbalanced Datasets This member-only story is on us. In just about any organization, the state of information quality is at the same low level – Olson, DataQualityData is everywhere! Upgrade to access all of Medium.
In the early days of online shopping, ecommerce brands were categorized as online stores or “multichannel” businesses operating both ecommerce sites and brick-and-mortar locations. To ensure the success of this approach, it is crucial to maintain a strong focus on dataquality, security and ethical considerations.
The Evolution of AI Agents Transition from Rule-Based Systems Early software systems relied on rule-based algorithms that worked well in controlled, predictable environments. Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches.
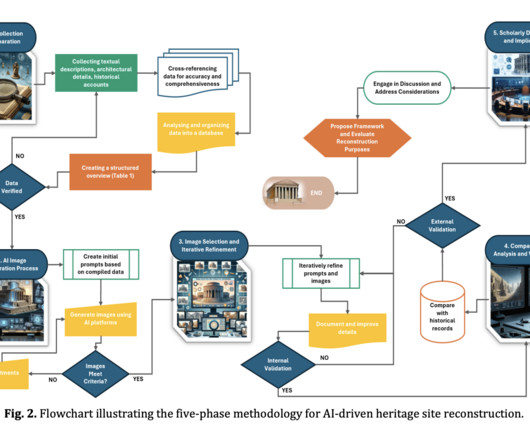
ArchiCAD, AutoCAD), generative adversarial networks (GANs) for image super-resolution, and machine learning algorithms are transforming the preservation and reconstruction of cultural heritage. Addressing dataquality and algorithm refinement challenges is crucial for enhancing AI’s precision in heritage conservation.
While effective in creating a base for model training, this foundational approach confronts substantial challenges, notably in ensuring dataquality, mitigating biases, and adequately representing lesser-known languages and dialects. A recent survey by researchers from South China University of Technology, INTSIG Information Co.,
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. They can search within specific categories to narrow down results.
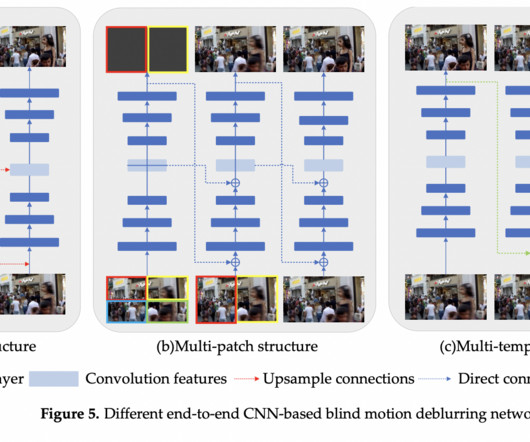
The researchers present a categorization system that uses backbone networks to organize these methods. Deblurring algorithms based on convolutional neural networks (CNNs) have great efficiency and generalizability when trained with large-scale datasets. There has been a lot of development in end-to-end algorithms for deblurring images.
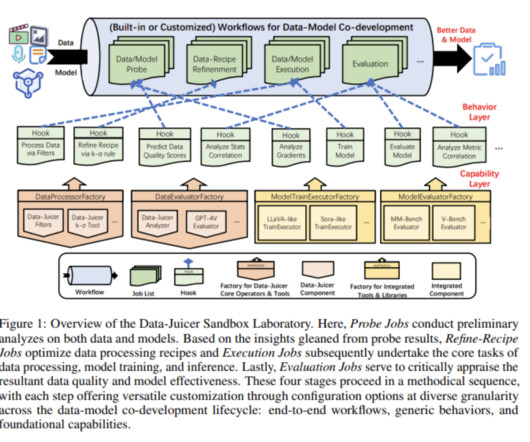
This separation hampers the ability to enhance data and models simultaneously, which is essential for improving AI capabilities. Current methods for developing multi-modal generative models typically focus either on refining algorithms and model architectures or enhancing data processing techniques.
Machine learning practitioners tend to do more than just create algorithms all day. First, there’s a need for preparing the data, aka data engineering basics. Some of the issues make perfect sense as they relate to dataquality, with common issues being bad/unclean data and data bias.
Challenges of building custom LLMs Building custom Large Language Models (LLMs) presents an array of challenges to organizations that can be broadly categorized under data, technical, ethical, and resource-related issues. Ensuring dataquality during collection is also important.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
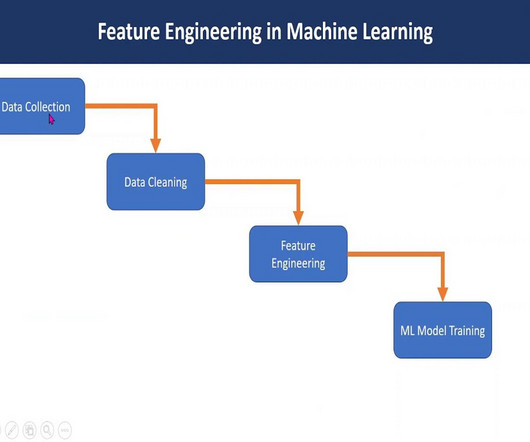
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through Exploratory Data Analysis , imputation, and outlier handling, robust models are crafted. Employ methods like mean, median, or advanced algorithms to impute missing values intelligently.
Photo by Bruno Nascimento on Unsplash Introduction Data is the lifeblood of Machine Learning Models. The dataquality is critical to the performance of the model. The better the data, the greater the results will be. Before we feed data into a learning algorithm, we need to make sure that we pre-process the data.
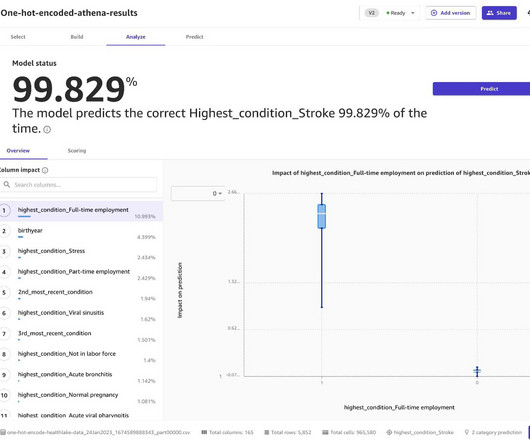
Perform one-hot encoding To unlock the full potential of the data, we use a technique called one-hot encoding to convert categorical columns, like the condition column, into numerical data. One of the challenges of working with categoricaldata is that it is not as amenable to being used in many machine learning algorithms.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher dataquality as per business requirements. Determine the range of values for categorical columns.
For more information about this process, refer to New — Introducing Support for Real-Time and Batch Inference in Amazon SageMaker Data Wrangler. Although we use a specific algorithm to train the model in our example, you can use any algorithm that you find appropriate for your use case.
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, data preparation, and algorithm selection. Dataquality significantly impacts model performance.
Scalability : A data pipeline is designed to handle large volumes of data, making it possible to process and analyze data in real-time, even as the data grows. Dataquality : A data pipeline can help improve the quality of data by automating the process of cleaning and transforming the data.
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform Exploratory Data Analysis to uncover patterns and insights hidden within the data. This crucial stage involves data cleaning, normalisation, transformation, and integration.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. Aggregation : Combining multiple data points into a single summary (e.g.,
Consider a scenario where legal practitioners are armed with clever algorithms capable of analyzing, comprehending, and extracting key insights from massive collections of legal papers. Carefully examining and categorizing these materials can be time-consuming and laborious. Algorithms can automatically detect and extract key items.
The solution for data quantity challenges in the retail industry lies in enhanced storage and management. Integrating software that can automatically categorize or process could solve the issue of being overwhelmed by information. For example, retailers could analyze and reveal trends much faster with a big data platform.
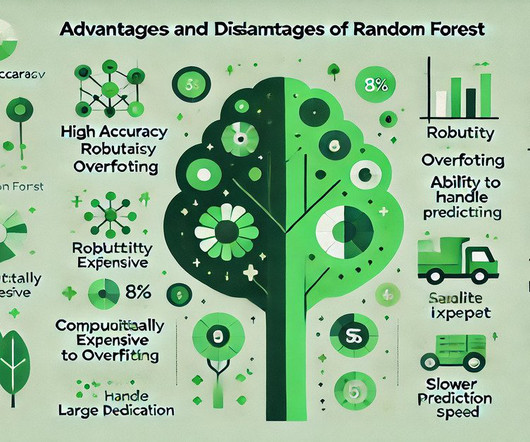
Summary: Random Forest is an effective Machine Learning algorithm known for its high accuracy and robustness. Introduction Random Forest is a powerful ensemble learning algorithm widely used in Machine Learning for classification and regression tasks. This allows trees to be fully grown, capturing intricate patterns in the data.
It provides high-quality, curated data, often with associated tasks and domain-specific challenges, which helps bridge the gap between theoretical ML algorithms and real-world problem-solving. The data can then be explored, cleaned, and processed to be used in Machine Learning models.
This is enabled by setting aside a portion of the historical training data so it can be compared with what the model predicts for those values. In the example of customer churn (which is a categorical classification problem), you start with a historical dataset that describes customers with many attributes (one in each record).
Preference optimization was then employed using Direct Preference Optimization (DPO) and other algorithms to align the models with human preferences. Steps were taken to de-identify sensitive data and ensure that all datasets met strict ethical and legal standards. Benchmark Evaluations: Unparalleled Performance of EXAONE 3.5
Here are the primary types: Logistic Regression Models: These models use historical data to predict the probability of default. Decision Trees and Random Forests: These models categorize borrowers based on various risk factors. Only complete or updated data can lead to reliable predictions and informed decision-making.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field.
Automated Triage and Prioritization In emergency departments (EDs), a fast interpretation of clinical data is critical to categorize the severity of patients’ conditions and prioritize cases for responsive care. Medical data is complex, requiring deep domain knowledge for accurate labeling and interpretation.
Data visualisation principles include clarity, accuracy, efficiency, consistency, and aesthetics. A bar chart represents categoricaldata with rectangular bars. In contrast, a histogram represents the distribution of numerical data by dividing it into intervals and displaying the frequency of each interval with bars.
Predictive analytics is rapidly becoming indispensable in data-driven decision-making, especially grant funding. It uses statistical algorithms and machine learning techniques to analyze historical data and predict future outcomes. According to a report by Gartner, poor dataquality costs businesses an average of $12.9
But this approach is expensive, time-consuming, and out of reach for all but the most well-funded companies, making the use of free, open-source alternatives for data curation appealing if sufficiently high dataquality can be achieved.
But this approach is expensive, time-consuming, and out of reach for all but the most well-funded companies, making the use of free, open-source alternatives for data curation appealing if sufficiently high dataquality can be achieved.
But this approach is expensive, time-consuming, and out of reach for all but the most well-funded companies, making the use of free, open-source alternatives for data curation appealing if sufficiently high dataquality can be achieved.
By visualizing data distributions, scatter plots, or heatmaps, data scientists can quickly identify outliers, clusters, or trends that might go unnoticed in raw data. This aids in detecting anomalies, understanding dataquality issues, and improving data cleaning processes.
Median: The middle value in a dataset, helping to understand the data’s distribution. Mode: The most frequent value, useful in categoricaldata. Applications Descriptive Data Analysis is widely used in business reporting and dashboards. Techniques Mean: The average value of a dataset, providing a central tendency.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content