This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post KModes Clustering Algorithm for Categorical data appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction: Clustering is an unsupervised learning method whose task is to.
Introduction In the bustling world of machine learning, categorical data is like the DNA of our datasets – essential yet complex. But how do we make this data comprehensible to our algorithms? Enter One Hot Encoding, the transformative process that turns categorical variables into a language that machines understand.
One of the biggest challenges is handling categorical attributes while dealing with datasets. In this article, we will delve into the world of auditing data, anomaly detection, and the impact of encoding categorical attributes on models. Introduction The world of auditing data can be complex, with many challenges to overcome.
Introduction “Data is the fuel for Machine Learning algorithms” Real-world. The post How to Handle Missing Values of Categorical Variables? ArticleVideo Book This article was published as a part of the Data Science Blogathon. appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Classification algorithms are used to categorize data into a class. The post 5 Classification Algorithms you should know – introductory guide! appeared first on Analytics Vidhya.
There are a lot of algorithms that come from the family of Boosted, such as AdaBoost, Gradient Boosting, XGBoost, and many more. One of the algorithms from Boosted family is a CatBoost algorithm. Introduction If enthusiastic learners want to learn data science and machine learning, they should learn the boosted family.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
Introduction Support vector machine is one of the most famous and decorated machine learning algorithms in classification problems. The heart and soul of this algorithm is the concept of Hyperplanes where these planes help to categorize the high dimensional data which are either […].
Brandwatch builds upon proprietary algorithms integrated with advanced language models, creating a system that processes social media conversations with depth. This system processes vast datasets of creator content and engagement metrics, utilizing AI to match brands with relevant influencers based on pattern recognition algorithms.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. But what if we could predict a student’s engagement level before they begin?
One often encounters datasets with categorical variables in data analysis and machine learning. However, many machine learning algorithms require numerical input. By transforming category data into numerical labels, label encoding enables us to use them in various algorithms. […] The post How to Perform Label Encoding in Python?
Introduction Logistic regression is a statistical technique used to model the probability of a binary (categorical variable that can take on two distinct values) outcome based on one or more predictor variables.
It employs algorithms like usage patterns, historical data and peak hour surges to improve bandwidth by analyzing demands and optimizing services. In addition, AI efficiently categorizes threats by assessing their potential severity, impact and damage. This will trigger the incident response team to jump in and protect coverage.
If, however, the surveillance system fines one neglectful neighbor more than another because its algorithm favors one skin color or clothing style over another, opinions could change. It insists that algorithms under its authority “do not process any biometric data and do not implement any facial recognition techniques.
These systems, built on biased datasets and algorithms, fail to reflect the diversity of global populations. Bias in AI typically can be categorized into algorithmic bias and data-driven bias. Algorithmic bias occurs when the logic and rules within an AI model favor specific outcomes or populations.
With AI-powered features like text recognition, content categorization, and smart search, Evernote ensures that users can quickly locate notes, even within images or scanned documents. Users can create notebooks, categorize content, and collaborate in real time with colleagues.
At its core, machine learning algorithms seek to identify patterns within data, enabling computers to learn and adapt to new information. Classification: Categorizing data into discrete classes (e.g., 2) Logistic regression Logistic regression is a classification algorithm used to model the probability of a binary outcome.
Based on this, it makes an educated guess about the importance of incoming emails, and categorizes them into specific folders. In addition to the smart categorization of emails, SaneBox also comes with a feature named SaneBlackHole, designed to banish unwanted emails.
Bookkeeping involves the meticulous scanning of receipts, methodically tracking all income and expenses, and categorizing expenditures. However, now, you need to categorize it for tax purposes. Imagine this scenario: you’ve purchased a printer for your home office, and it turns out to be of great help.
The Ministry of Justice in Baden-Württemberg recommended using AI with natural language understanding (NLU) and other capabilities to help categorize each case into the different case groups they were handling. The courts needed a transparent, traceable system that protected data. Explainability will play a key role.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. One of the most fundamental tasks in Machine Learning is classification , which involves categorizing data into predefined classes.
Furthermore, these frameworks often lack flexibility in assessing diverse research outputs, such as novel algorithms, model architectures, or predictions. A six-level framework categorizes AI research agent capabilities, with MLGym-Bench focusing on Level 1: Baseline Improvement, where LLMs optimize models but lack scientific contributions.
If you’re new to ML, you probably must’ve heard of the words “algorithm” or “model” without knowing how they’re related to machine learning. Machine learning algorithms are categorized as supervised or unsupervised. Here’s a brief explanation in plain English. Subscribe now 1.
This step involves cleaning your data, handling missing values, normalizing or scaling your data and encoding categorical variables into a format your algorithm can understand. Clean, well-prepped data is more manageable for algorithms to read and learn from, leading to more accurate predictions and better performance.
For example, when implemented correctly, the image recognition algorithm can identify & label the dog in the image. Fundamentally, an image recognition algorithm generally uses machine learning & deep learning models to identify objects by analyzing every individual pixel in an image. How Image Recognition Works?
The best Farshidian can categorize how Spot is moving is that its somewhat similar to a trotting gait, except with an added flight phase (with all four feet off the ground at once) that technically turns it into a run. Understanding these hidden limits in hardware systems lets us improve performance and keep pushing the boundaries on control.
AI-powered algorithms can detect and correct inconsistencies, fill in missing attributes, and classify products based on predefined rules or learned patterns, reducing manual errors and ensuring uniformity across marketplaces, eCommerce platforms, print catalogs, and anywhere else you sell. to create those tailored product recommendations.
From chatbots that handle customer requests around the clock to predictive algorithms that preempt system failures, AI is not just an add-on; it is becoming a necessity in tech. Types of AI in ITSM AI in ITSM can be categorized into three types: automation, chatbots, and predictive analysis. Nightmare, right?
Sentiment analysis to categorize mentions as positive, negative, or neutral. It uses natural language processing (NLP) algorithms to understand the context of conversations, meaning it's not just picking up random mentions! Clean and intuitive user interface that's easy to navigate. Easy reporting functionality.
The US has relied on industry experts, while the EU and Brazil aim to set up a categorical system. forbes.com Not All Algorithms Are AI (Part 2): The Rise Of Real AI ChatGPT And Large Language Models: Now And Beyond Large language models (LLMs) and generative AI are deep learning on steroids. China takes a more restrictive stance.
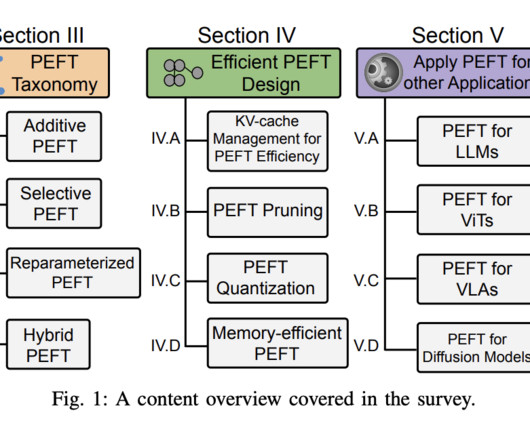
Researchers from Northeastern University, the University of California, Arizona State University, and New York University present this survey thoroughly examining diverse PEFT algorithms and evaluating their performance and computational requirements.
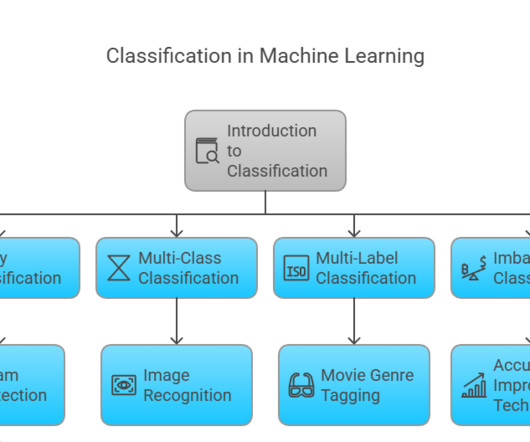
Introduction Classification algorithms are at the heart of data science, helping us categorize and organize data into pre-defined classes. These algorithms are used in a wide array of applications, from spam detection and medical diagnosis to image recognition and customer profiling.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests. This method takes a parameter, which we set to 3.
Their newly integrated AutoGPTQ library in the Transformers ecosystem allows users to quantize and run LLMs using the GPTQ algorithm. To tackle this, the researchers integrated the GPTQ algorithm, a quantization technique, into the AutoGPTQ library.
This data is created algorithmically to mimic the characteristics of real-world data and can serve as an alternative or supplement to it. “A lot of research is going into developing more computationally efficient algorithms,” Smolinksi adds. But when you have constraints, you become more creative.”
Consider these questions: Do you have a platform that combines statistical analyses, prescriptive analytics and optimization algorithms? Do you have purpose-built algorithms to improve intermittent and variable demand forecasting? Master data enrichment to enhance categorization and materials attributes.
AI algorithms can categorize emails more effectively than traditional filters, prioritizing important messages and reducing the clutter of less relevant ones. Bias in AI Algorithms AI systems are only as unbiased as the data they are trained on. “AI in email is about creating an intuitive and responsive experience.”
Modern SaaS analytics solutions can seamlessly integrate with AI models to predict user behavior and automate data sorting and analysis; and ML algorithms enable SaaS apps to learn and improve over time. AI and ML algorithms enhance these features by processing unique app data more efficiently.
Its Python domain offers simple, medium, and hard challenges that are categorized for gradual learning. By focussing on topics like algorithms, regex, string manipulation, and maths, each challenge enhances fundamental Python abilities.
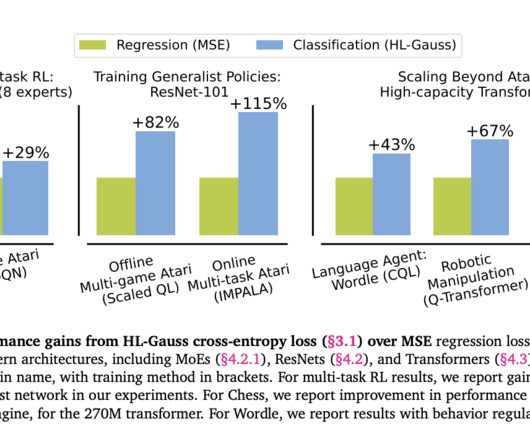
This shift involves converting real-valued targets to categorical labels and minimizing categorical cross-entropy. Their work extensively examines methods for training value functions with categorical cross-entropy loss in deep RL. Their approach transforms the regression problem in TD learning into a classification problem.
Source: UC Berkeley Types of AI Agents World Economic Forum has categorized AI agents into the following types: 1. By using goal-oriented planning algorithms, they excel in complex decision-making tasks. Leverage Learning Module to reflect on the outcomes of the action to enhance future performance.
In the past, the business relied on a conventional approach to segmentation, categorizing customers by geographic location, based on the underlying assumption that farmers from the same region would have similar needs. For example, in the US, mortgage companies have been under fire for alleged racial profiling of their AI algorithms.
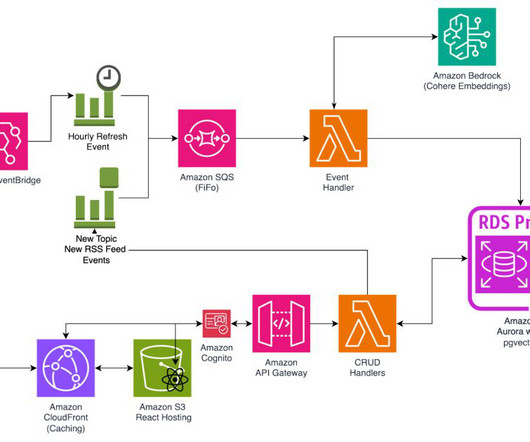
On our website, users can subscribe to an RSS feed and have an aggregated, categorized list of the new articles. However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content