This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ahead of AI & BigData Expo North America – where the company will showcase its expertise – Chuck Ros , Industry Success Director at SoftServe, provided valuable insights into the company’s AI initiatives, the challenges faced, and its future strategy for leveraging this powerful technology. .”
The survey uncovers a troubling lack of trust in dataquality—a cornerstone of successful AI implementation. Only 38% of respondents consider themselves ‘very trusting’ of the dataquality and training used in AI systems. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
The future of AI demands both, but it starts with the data. Why DataQuality Matters More Than Ever According to one survey, 48% of businesses use bigdata , but a much lower number manage to use it successfully. This emphasis on dataquality has profound implications. Why is this the case?
Addressing this gap will require a multi-faceted approach including grappling with issues related to dataquality and ensuring that AI systems are built on reliable, unbiased, and representative datasets. Companies have struggled with dataquality and data hygiene.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. And then I found certain areas in computer science very attractive such as the way algorithms work, advanced algorithms. What initially attracted you to computer science?
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
Introduction: The Reality of Machine Learning Consider a healthcare organisation that implemented a Machine Learning model to predict patient outcomes based on historical data. However, once deployed in a real-world setting, its performance plummeted due to dataquality issues and unforeseen biases.
But before AI/ML can contribute to enterprise-level transformation, organizations must first address the problems with the integrity of the data driving AI/ML outcomes. The truth is, companies need trusted data, not just bigdata. That’s why any discussion about AI/ML is also a discussion about data integrity.
A generative AI company exemplifies this by offering solutions that enable businesses to streamline operations, personalise customer experiences, and optimise workflows through advanced algorithms. Data forms the backbone of AI systems, feeding into the core input for machine learning algorithms to generate their predictions and insights.
However, with the emergence of Machine Learning algorithms, the retail industry has seen a revolutionary shift in demand forecasting capabilities. This technology allows computers to learn from historical data, identify patterns, and make data-driven decisions without explicit programming.
Artificial Intelligence (AI) stands at the forefront of transforming data governance strategies, offering innovative solutions that enhance data integrity and security. In this post, let’s understand the growing role of AI in data governance, making it more dynamic, efficient, and secure. You can connect with him on LinkedIn.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party bigdata sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Going from Data to Insights LexisNexis At HPCC Systems® from LexisNexis® Risk Solutions you’ll find “a consistent data-centric programming language, two processing platforms, and a single, complete end-to-end architecture for efficient processing.” These tools are designed to help companies derive insights from bigdata.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. Why Are Data Transformation Tools Important?
It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform bigdata analytics and gain valuable insights from their data. In a Hadoop cluster, data stored in the Hadoop Distributed File System (HDFS), which spreads the data across the nodes.
Step 3: Load and process the PDF data For this blog, we will use a PDF file to perform the QnA on it. We’ve selected a research paper titled “DEEP LEARNING APPLICATIONS AND CHALLENGES IN BIGDATA ANALYTICS,” which can be accessed at the following link: [link] Please download the PDF and place it in your working directory.
The Role of Data Scientists and ML Engineers in Health Informatics At the heart of the Age of Health Informatics are data scientists and ML engineers who play a critical role in harnessing the power of data and developing intelligent algorithms.
Machine Learning This involves training algorithms on large datasets to learn from data without explicit programming. BigData Analytics This involves analyzing massive datasets that are too large and complex for traditional data analysis methods.
Introduction In the age of bigdata, where information flows like a relentless river, the ability to extract meaningful insights is paramount. Association rule mining (ARM) emerges as a powerful tool in this data-driven landscape, uncovering hidden patterns and relationships between seemingly disparate pieces of information.
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. After you have completed the data preparation step, it’s time to train the classification model.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
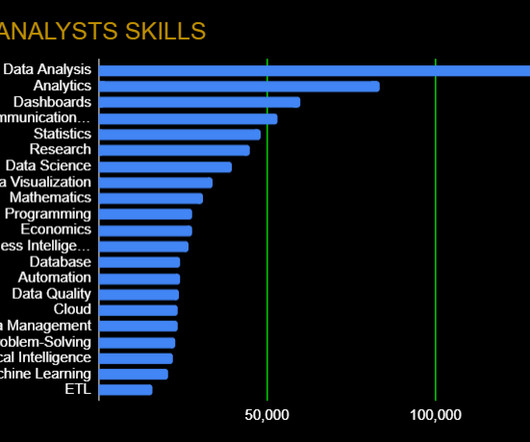
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Challenges in Credit Risk Modeling Despite its importance, credit risk modelling faces several challenges: DataQuality and Availability: Accurate credit risk modelling relies on high-quality, comprehensive data. Only complete or updated data can lead to reliable predictions and informed decision-making.
Issues such as dataquality, resistance to change, and a lack of skilled personnel can hinder success. Key Takeaways Dataquality is essential for effective Pricing Analytics implementation. Ensuring high-qualitydata collection processes is essential for reliable outcomes.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of bigdata technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
Next-generation sequencing (NGS) platforms have dramatically increased the speed and reduced the cost of DNA sequencing, leading to the generation of vast amounts of genomic data. Integrating and analyzing data from multiple platforms and experiments pose challenges due to data formats, normalization techniques, and dataquality differences.
Predictive Analytics Predictive analytics involves using statistical algorithms and Machine Learning techniques to forecast future events based on historical data. These technologies enable organisations to analyse vast amounts of data quickly and accurately.
Machine Learning Explored and applied ML algorithms for intelligent solutions. Job options after MBA in Business Analytics Job role Description Average Annual Salary Data Analyst Analysing and interpreting complex data sets, Data Analysts are crucial in extracting meaningful insights that guide strategic decision-making.
This blog delves into how Uber utilises Data Analytics to enhance supply efficiency and service quality, exploring various aspects of its approach, technologies employed, case studies, challenges faced, and future directions. Machine Learning Algorithms : Uber uses Machine Learning to refine its algorithms continuously.
While unstructured data may seem chaotic, advancements in artificial intelligence and machine learning enable us to extract valuable insights from this data type. BigDataBigdata refers to vast volumes of information that exceed the processing capabilities of traditional databases.
It is now the foundation for intelligent, data-driven decisions in present-day stock trading. Forecasts indicate that during the next five years, the global algorithmic trading market is expected to increase at a consistent rate of 8.53%. It went from simple rule-based systems to advanced data-driven algorithms.
Data scrubbing is often used interchangeably but there’s a subtle difference. Cleaning is broader, improving dataquality. This is a more intensive technique within data cleaning, focusing on identifying and correcting errors. Data scrubbing is a powerful tool within this cleaning service.
For example, retailers could analyze and reveal trends much faster with a bigdata platform. It also can ensure they retain quality details since they don’t have to limit how much they collect. Quality Most retailers have dealt with irrelevant results even when using automatic processing systems like AI.
By leveraging Machine Learning algorithms, predictive analytics, and real-time data processing, AI can enhance decision-making processes and streamline operations. Quality Monitoring AI can enhance water quality monitoring by analysing data from various sources in real-time.
Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it. However, generalizing feature engineering is challenging.
HPCC Systems — The Kit and Kaboodle for BigData and Data Science Bob Foreman | Software Engineering Lead | LexisNexis/HPCC Join this session to learn how ECL can help you create powerful data queries through a comprehensive and dedicated data lake platform. Check them out for free!
Advanced crawling algorithms allow them to adapt to new content and changes in website structures. Precision: Advanced algorithms ensure they accurately categorise and store data. This efficiency saves time and resources in data collection efforts. It is designed for scalability and can handle vast amounts of data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content