This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With so many examples of algorithmic bias leading to unwanted outputs and humans being, well, humans behavioural psychology will catch up to the AI train, explained Mortensen. However, such systems require robust dataintegration because siloed information risks undermining their reliability. The solutions?
Only a third of leaders confirmed that their businesses ensure the data used to train generative AI is diverse and unbiased. Furthermore, only 36% have set ethical guidelines, and 52% have established data privacy and security policies for generative AI applications. Want to learn more about AI and bigdata from industry leaders?
Artificial Intelligence (AI) stands at the forefront of transforming data governance strategies, offering innovative solutions that enhance dataintegrity and security. With AI, data quality checks happen in real time. This foresight is crucial in maintaining not just dataintegrity but also operational continuity.
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with DataIntegrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machine learning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
Why Data Quality Matters More Than Ever According to one survey, 48% of businesses use bigdata , but a much lower number manage to use it successfully. Its because the foundational principle of data-centric AI is straightforward: a model is only as good as the data it learns from. Why is this the case?
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. And then I found certain areas in computer science very attractive such as the way algorithms work, advanced algorithms. What initially attracted you to computer science?
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
Summary: Depth First Search (DFS) is a fundamental algorithm used for traversing tree and graph structures. Introduction Depth First Search (DFS) is a fundamental algorithm in Artificial Intelligence and computer science, primarily used for traversing or searching tree and graph data structures. What is Depth First Search?
Data analysts also require significant computational power. This enables data scientists to run complex algorithms without owning powerful machinery. Additionally, many data science tools and software platforms are now cloud-based. Its global network of data centers ensures fast data access and scalability.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party bigdata sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
However, with the emergence of Machine Learning algorithms, the retail industry has seen a revolutionary shift in demand forecasting capabilities. This technology allows computers to learn from historical data, identify patterns, and make data-driven decisions without explicit programming.
Another is augmented reality technology that uses algorithms to mimic digital information and understand a physical environment. This operating model increases operational efficiency and can better organize bigdata. The AI technology drives innovation to smart products and a more pointed focus on customer and user experience.
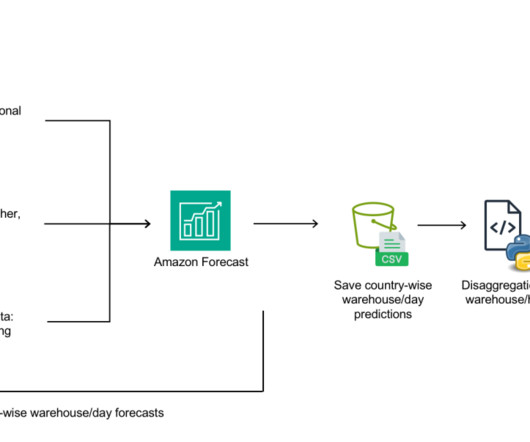
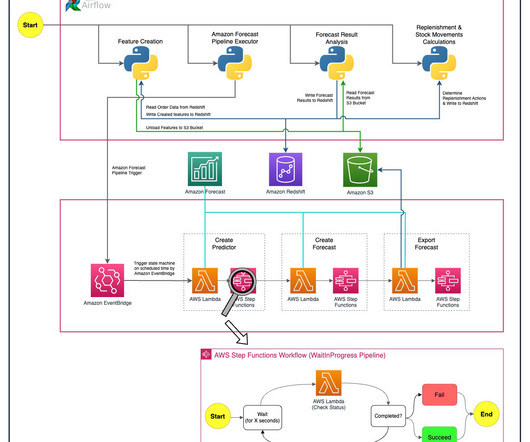
Amazon Forecast is a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts. Calculating courier requirements The first step is to estimate hourly demand for each warehouse, as explained in the Algorithm selection section.
His focus was building machine learning algorithms to simulate nervous network anomalies. He joined Getir in 2019 and currently works as a Senior Data Science & Analytics Manager. His team is responsible for designing, implementing, and maintaining end-to-end machine learning algorithms and data-driven solutions for Getir.
Getir used Amazon Forecast , a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts, to increase revenue by four percent and reduce waste cost by 50 percent. Deep/neural network algorithms also perform very well on sparse data set and in cold-start (new item introduction) scenarios.
The Role of Data Scientists and ML Engineers in Health Informatics At the heart of the Age of Health Informatics are data scientists and ML engineers who play a critical role in harnessing the power of data and developing intelligent algorithms.
Introduction Data transformation plays a crucial role in data processing by ensuring that raw data is properly structured and optimised for analysis. Data transformation tools simplify this process by automating data manipulation, making it more efficient and reducing errors.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Next-generation sequencing (NGS) platforms have dramatically increased the speed and reduced the cost of DNA sequencing, leading to the generation of vast amounts of genomic data. Integrating and analyzing data from multiple platforms and experiments pose challenges due to data formats, normalization techniques, and data quality differences.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
It relates to employing algorithms to find and examine data patterns to forecast future events. Through practice, machines pick up information or skills (or data). Algorithms and models Predictive analytics uses several methods from fields like machine learning, data mining, statistics, analysis, and modeling.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of bigdata technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
The AWS Glue ML transform builds on this intuition and provides an easy-to-use ML-based algorithm to automatically apply this approach to large datasets efficiently. Create the FindMatches ML transform On the AWS Glue console, expand DataIntegration and ETL in the navigation pane. This will open the ML transforms page.
Unified Data Services: Azure Synapse Analytics combines bigdata and data warehousing, offering a unified analytics experience. Azure’s global network of data centres ensures high availability and performance, making it a powerful platform for Data Scientists to leverage for diverse data-driven projects.
Key issues include determining the optimal number of clusters, managing high-dimensional data, and addressing sensitivity to noise and outliers. Understanding these challenges is essential for implementing clustering algorithms successfully and deriving meaningful insights from complex datasets.
These include the database engine for executing queries, the query processor for interpreting SQL commands, the storage manager for handling physical data storage, and the transaction manager for ensuring dataintegrity through ACID properties. Data Independence: Changes in database structure do not affect application programs.
Perform an analysis on the transformed data Now that transformations have been done on the data, you may want to perform analyses to make sure they haven’t affected dataintegrity. This option selects the algorithm most relevant to your dataset and the best range of hyperparameters to tune model candidates.
Data can be structured (e.g., The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions. DataIntegration Once data is collected from various sources, it needs to be integrated into a cohesive format. databases), semi-structured (e.g.,
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks.
While unstructured data may seem chaotic, advancements in artificial intelligence and machine learning enable us to extract valuable insights from this data type. BigDataBigdata refers to vast volumes of information that exceed the processing capabilities of traditional databases.
The primary purpose of a DBMS is to provide a systematic way to manage large amounts of data, ensuring that it is organised, accessible, and secure. By employing a DBMS, organisations can maintain dataintegrity, reduce redundancy, and streamline data operations, enabling more informed decision-making.
Its speed and performance make it a favored language for bigdata analytics, where efficiency and scalability are paramount. This environment allows users to write, execute, and debug code in a seamless manner, facilitating rapid prototyping and exploration of algorithms. Q: Is C++ relevant in Data Science? About Pickl.AI
Price Optimization Software Tools like PROS or Vendavo use advanced algorithms to analyse historical sales data and predict optimal prices based on various factors such as demand elasticity and competitor actions. Below are some of the most effective tools and techniques used in Pricing Analytics.
The Retrieve API takes the incoming query, converts it into an embedding vector, and queries the backend store using the algorithms configured at the vector database level; the RetrieveAndGenerate API uses a user-configured LLM provided by Amazon Bedrock and generates the final answer in natural language. Nihir Chadderwala is a Sr.
As businesses increasingly rely on data-driven strategies, the global BI market is projected to reach US$36.35 The rise of bigdata, along with advancements in technology, has led to a surge in the adoption of BI tools across various sectors. Data Processing: Cleaning and organizing data for analysis.
It utilizes sophisticated algorithms and techniques to tackle various data imperfections. Data cleaning is the overarching strategy, while data scrubbing is a specific tactic. It’s a powerful toolkit equipped with specialized features to tackle many data imperfections.
Some of the popular cloud-based vendors are: Hevo Data Equalum AWS DMS On the other hand, there are vendors offering on-premise data pipeline solutions and are mostly preferred by organizations dealing with highly sensitive data. No built-in data quality functionality. No expert support.
Also included in the need for flexibility are data governance, dataintegration, and data exploration, all of which require crucial supervision and monitoring. These processes ensure all data are evaluated and all scopes are checked, tested, and assessed.
Online Processing: this type of data processing involves managing transactional data in real time and focuses on handling individual transaction. The systems are designed to ensure dataintegrity, concurrency and quick response times for enabling interactive user transactions. The Data Science courses provided by Pickl.AI
Understanding AIOps Think of AIOps as a multi-layered application of BigData Analytics , AI, and ML specifically tailored for IT operations. Its primary goal is to automate routine tasks, identify patterns in IT data, and proactively address potential issues. This might involve data cleansing and standardization efforts.
Rules Engine This is the brain of the CDSS, employing complex algorithms to analyze patient data against the knowledge base. The rules engine acts like a tireless medical consultant, constantly evaluating patient data and recommending the most suitable course of action based on the latest medical knowledge.
During a data analysis project, I encountered a significant data discrepancy that threatened the accuracy of our analysis. I conducted thorough data validation, collaborated with stakeholders to identify the root cause, and implemented corrective measures to ensure dataintegrity.
Explore More: BigData Engineers: An In-depth Analysis. Also Check: What is DataIntegration in Data Mining with Example? However, vSphere’s advanced algorithms and extensive configurations give it an edge in complex environments with varied workload demands. Demystifying Desktop as a Service (DaaS).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content