This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenAI has been instrumental in developing revolutionary tools like the OpenAI Gym, designed for training reinforcement algorithms, and GPT-n models. Prompt design and engineering are growing disciplines that aim to optimize the output quality of AI models like ChatGPT. Imagine you're trying to translate English to French.
Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes. These deep-learning algorithms dissect individual preferences based on various musical elements such as tempo and mood to craft personalized song suggestions. Creating music using artificial intelligence began several decades ago.
By utilizing machine learning algorithms , it produces new content, including images, text, and audio, that resembles existing data. Another breakthrough is the rise of generative language models powered by deep learning algorithms. Generative AI is an evolving field that has experienced significant growth and progress in 2023.
The role of promptengineer has attracted massive interest ever since Business Insider released an article last spring titled “ AI ‘PromptEngineer Jobs: $375k Salary, No Tech Backgrund Required.” It turns out that the role of a PromptEngineer is not simply typing questions into a prompt window.
Black box algorithms such as xgboost emerged as the preferred solution for a majority of classification and regression problems. The introduction of attention mechanisms has notably altered our approach to working with deep learning algorithms, leading to a revolution in the realms of computer vision and natural language processing (NLP).
Generative AI uses advanced machine learning algorithms and techniques to analyze patterns and build statistical models. The quality of outputs depends heavily on training data, adjusting the model’s parameters and promptengineering, so responsible data sourcing and bias mitigation are crucial.
Promptengineering is crucial to steering LLMs effectively. Techniques like Word2Vec and BERT create embedding models which can be reused. BERT produces deep contextual embeddings by masking words and predicting them based on bidirectional context. LLMs utilize embeddings to understand word context.
Traditional Computing Systems : From basic computing algorithms, the journey began. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. These systems could solve pre-defined tasks using a fixed set of rules.
In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. For text tasks such as sentence classification, text classification, and question answering, you can use models such as BERT, RoBERTa, and DistilBERT.
Supervised learning Supervised learning is a widely used approach in machine learning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. Promptengineering : the provided prompt plays a crucial role, especially when dealing with compound nouns.
Like machine learning operations, LLMOps involves efforts from several contributors, like promptengineers, data scientists, DevOps engineers, business analysts, and IT operations. This is, in fact, a baseline, and the actual LLMOps workflow usually involves more stakeholders like promptengineers, researchers, etc.
Especially for DeepSpeed, the partitioning algorithm is tightly coupled with fused kernel operators. PromptengineeringPromptengineering refers to efforts to extract accurate, consistent, and fair outputs from large models, such text-to-image synthesizers or large language models.
It does a deep dive into two reinforcement learning algorithms used in training large language models (LLMs): Proximal Policy Optimization (PPO) Group Relative Policy Optimization (GRPO) LLM Training Overview The training of LLMs is divided into two phases: Pre-training: The model learns next token prediction using large-scale web data.
Over the past year, new terms, developments, algorithms, tools, and frameworks have emerged to help data scientists and those working with AI develop whatever they desire. PromptEngineering Another buzzword you’ve likely heard of lately, promptengineering means designing inputs for LLMs once they’re developed.
With these complex algorithms often labeled as "giant black boxes" in media, there's a growing need for accurate and easy-to-understand resources, especially for Product Managers wondering how to incorporate AI into their product roadmap. months on average. Learn more about it in our dedicated blog series on Generative AI.
Especially now with the growth of generative AI and promptengineering — both skills that use NLP — now’s a good time to get into the field while it’s hot with this introduction to NLP course. Classic Machine Learning in NLP The following section explores how traditional machine learning algorithms can be applied to NLP tasks.
This, coupled with the challenges of understanding AI concepts and complex algorithms, contributes to the learning curve associated with developing applications using LLMs. Langchain, a state-of-the-art library, brings convenience and flexibility to designing, implementing, and tuning prompts.
How Prompt Tuning Fits into the Broader Context of AI and Machine Learning In the broader context of AI and Machine Learning , prompt tuning is part of a larger strategy known as “promptengineering.” Prompt tuning is a more focused method compared to full model fine-tuning.
There are many approaches to language modelling, we can for example ask the model to fill in the words in the middle of a sentence (as in the BERT model) or predict which words have been swapped for fake ones (as in the ELECTRA model). PromptEngineering As mentioned above we can use ChatGPT to perform a number of different NLP tasks.
This is brought on by various developments, such as the availability of data, the creation of more potent computer resources, and the development of machine learning algorithms. BERT and GPT are examples. Understanding the Rise of LLMOps The number of LLMs available has significantly increased in recent years.
Supervised learning Supervised learning is a widely used approach in machine learning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. Promptengineering : the provided prompt plays a crucial role, especially when dealing with compound nouns.
In our review of 2019 we talked a lot about reinforcement learning and Generative Adversarial Networks (GANs), in 2020 we focused on Natural Language Processing (NLP) and algorithmic bias, in 202 1 Transformers stole the spotlight. Useful links: prompt OpenAI’s Dalle-2 with an online demo prompt Huggin face’s Stable diffusion with this demo.
A lot of the models, algorithms, and even the public data that’s been used to train models like ChatGPT is really commoditizing, and it’s become apparent that the most valuable asset now is all the private, domain-specific data and knowledge being used. Is it tweaking the algorithm or the model? But that part was challenging.
Different algorithms provide different ways of calculating this distance. The StringDistanceStringEvaluator measures the similarity between two strings using a string distance algorithm like Levenshtein distance. The smaller the distance, the more similar the two strings are.
Transformers, like BERT and GPT, brought a novel architecture that excelled at capturing contextual relationships in language. ChatGPT promptAlgorithm model has been trained on vast amounts of Internet text to develop a comprehensive understanding of various topics.
A lot of the models, algorithms, and even the public data that’s been used to train models like ChatGPT is really commoditizing, and it’s become apparent that the most valuable asset now is all the private, domain-specific data and knowledge being used. Is it tweaking the algorithm or the model? But that part was challenging.
A lot of the models, algorithms, and even the public data that’s been used to train models like ChatGPT is really commoditizing, and it’s become apparent that the most valuable asset now is all the private, domain-specific data and knowledge being used. Is it tweaking the algorithm or the model? But that part was challenging.
350x: Application Areas , Companies, Startups 3,000+: Prompts , PromptEngineering, & Prompt Lists 250+: Hardware, Frameworks , Approaches, Tools, & Data 300+: Achievements, Impacts on Society , AI Regulation, & Outlook 20x: What is Generative AI?
These algorithms take input data, such as a text or an image, and pair it with a target output, like a word translation or medical diagnosis. Information Retrieval: Using LLMs, such as BERT or GPT, as part of larger architectures to develop systems that can fetch and categorize information. They're about mapping and prediction.
In this post, we focus on the BERT extractive summarizer. BERT extractive summarizer The BERT extractive summarizer is a type of extractive summarization model that uses the BERT language model to extract the most important sentences from a text. It works by first embedding the sentences in the text using BERT.
accuracy on the development set, while its counterpart bert-base-uncased boasts an accuracy of 92.7%. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. This model achieves a 91.3%
After parsing a question, an algorithm encodes it into a structured logical form in the query language of choice, such as SQL. High-quality , so that the Text2SQL algorithm does not have to deal with excessive noise (inconsistencies, empty values etc.) section “Enriching the prompt with database information”). in the data.
Autoencoding models, which are better suited for information extraction, distillation and other analytical tasks, are resting in the background — but let’s not forget that the initial LLM breakthrough in 2018 happened with BERT, an autoencoding model. Developers can now focus on efficient promptengineering and quick app prototyping.[11]
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










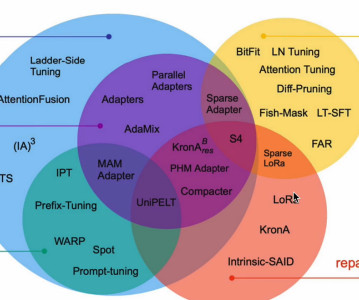





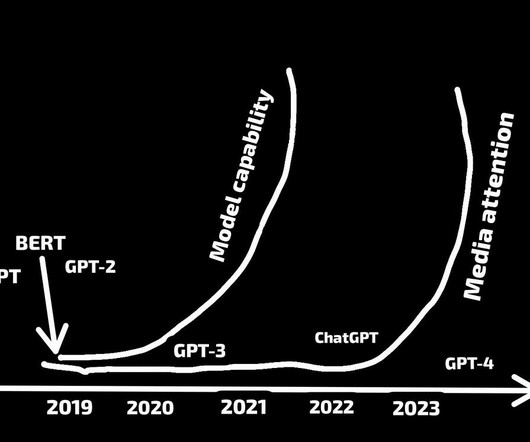












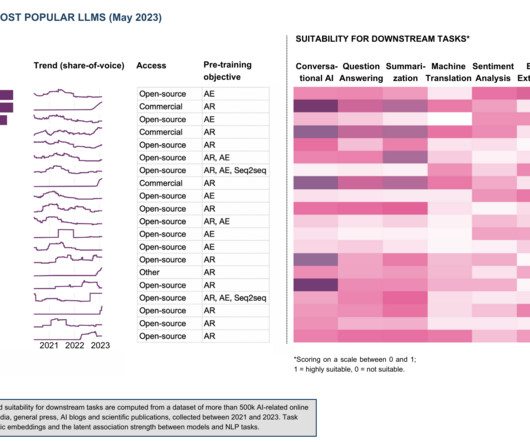






Let's personalize your content