This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They process and generate text that mimics human communication. At the leading edge of NaturalLanguageProcessing (NLP) , models like GPT-4 are trained on vast datasets. They understand and generate language with high accuracy. Personal experiences, emotions, and biological processes shape human memory.
Most AI systems operate within the confines of their programmed algorithms and datasets, lacking the ability to extrapolate or infer beyond their training. Bridging the Gap with NaturalLanguageProcessingNaturalLanguageProcessing (NLP) stands at the forefront of bridging the gap between human language and AI comprehension.
One of the most promising areas within AI in healthcare is NaturalLanguageProcessing (NLP), which has the potential to revolutionize patient care by facilitating more efficient and accurate data analysis and communication.
Take, for instance, word embeddings in naturallanguageprocessing (NLP). BERT and its Variants : BERT (Bidirectional Encoder Representations from Transformers) by Google, is another significant model that has seen various updates and iterations like RoBERTa, and DistillBERT.
To tackle the issue of single modality, Meta AI released the data2vec, the first of a kind, self supervised high-performance algorithm to learn patterns information from three different modalities: image, text, and speech. Why Does the AI Industry Need the Data2Vec Algorithm?
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes. However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deep learning and NaturalLanguageProcessing (NLP) to play pivotal roles in this tech.
Traditional machine learning is a broad term that covers a wide variety of algorithms primarily driven by statistics. The two main types of traditional ML algorithms are supervised and unsupervised. These algorithms are designed to develop models from structured datasets. Do We Still Need Traditional Machine Learning Algorithms?
Transformer Models and BERT Model : In this course, participants delve into the specifics of Transformer models and the Bidirectional Encoder Representations from Transformers (BERT) model. This course is ideal for those interested in the latest in naturallanguageprocessing technologies.
Pixabay: by Activedia Image captioning combines naturallanguageprocessing and computer vision to generate image textual descriptions automatically. Various algorithms are employed in image captioning, including: 1. These algorithms can learn and extract intricate features from input images by using convolutional layers.
Featured Community post from the Discord Aman_kumawat_41063 has created a GitHub repository for applying some basic ML algorithms. It offers pure NumPy implementations of fundamental machine learning algorithms for classification, clustering, preprocessing, and regression. Learn AI Together Community section!
This term refers to how much time, memory, or processing power an algorithm requires as the size of the input grows. AI models like neural networks , used in applications like NaturalLanguageProcessing (NLP) and computer vision , are notorious for their high computational demands.
TextBlob A popular Python sentiment analysis toolkit, TextBlob is praised for its ease of use and adaptability while managing naturallanguageprocessing (NLP) workloads. spaCy A well-known open-source naturallanguageprocessing package, spaCy is praised for its robustness and speed while processing massive amounts of text.
At that time, the field of naturallanguageprocessing was not as advanced as it is today, which is quite remarkable considering it was only about six years ago when this project was initiated. We started with 20k transactions and a distilled BERT model trained on them. Could you share the genesis story behind Ntropy?
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computer vision , naturallanguageprocessing , and more. The Paillier algorithm works as depicted.
Black box algorithms such as xgboost emerged as the preferred solution for a majority of classification and regression problems. Later, Python gained momentum and surpassed all programming languages, including Java, in popularity around 2018–19. In 2023, we witnessed the substantial transformation of AI, marking it as the ‘year of AI.’
With these fairly complex algorithms often being described as “giant black boxes” in news and media, a demand for clear and accessible resources is surging. This concept is not exclusive to naturallanguageprocessing, and has also been employed in other domains.
Naturallanguageprocessing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., rely on Language Models as their foundation. Unigrams, N-grams, exponential, and neural networks are valid forms for the Language Model.
Over the past few years, Large Language Models (LLMs) have garnered attention from AI developers worldwide due to breakthroughs in NaturalLanguageProcessing (NLP). These models have set new benchmarks in text generation and comprehension.
Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data. A foundation model is built on a neural network model architecture to process information much like the human brain does. An open-source model, Google created BERT in 2018.
RoBERTa is an optimized variant of BERT, designed to improve the pretraining process and fine-tune hyperparameters, leading to enhanced performance across a wide range of naturallanguageprocessing tasks. Both challenges will be addressed using RoBERTa, a state-of-the-art Transformer-based machine learning model.
They are now capable of naturallanguageprocessing ( NLP ), grasping context and exhibiting elements of creativity. Generative AI uses advanced machine learning algorithms and techniques to analyze patterns and build statistical models. the generated content) should most likely land.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. NLTK is appreciated for its broader nature, as it’s able to pull the right algorithm for any job.
Understanding the terminology, from the foundational aspects of training and fine-tuning to the cutting-edge concepts of transformers and reinforcement learning, is the first step towards demystifying the powerful algorithms that drive modern AI language systems.
Sentiment analysis, commonly referred to as opinion mining/sentiment classification, is the technique of identifying and extracting subjective information from source materials using computational linguistics , text analysis , and naturallanguageprocessing. positive, negative, neutral). are used to classify the text sentiment.
But now, a computer can be taught to comprehend and process human language through NaturalLanguageProcessing (NLP), which was implemented, to make computers capable of understanding spoken and written language. It has a state-of-the-art language representation model developed by Facebook AI.
Large Language Models (LLMs) have revolutionized naturallanguageprocessing, demonstrating remarkable capabilities in various applications. Transformer architecture has emerged as a major leap in naturallanguageprocessing, significantly outperforming earlier recurrent neural networks.
These limitations are particularly significant in fields like medical imaging, autonomous driving, and naturallanguageprocessing, where understanding complex patterns is essential. Deep learning algorithms can identify tumors with high precision, reducing false positives and improving diagnostic accuracy.
Introduction In naturallanguageprocessing, text categorization tasks are common (NLP). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, Depending on the data they are provided, different classifiers may perform better or worse (eg.
Amazon SageMaker JumpStart provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning.
Sentiment analysis and other naturallanguage programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. He spent 10 years as Head of Morgan Stanley’s Algorithmic Trading Division in San Francisco.
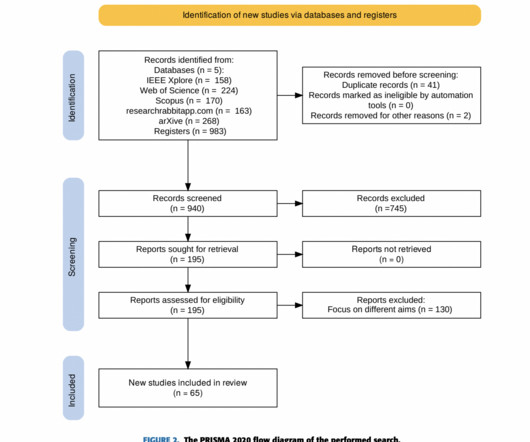
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
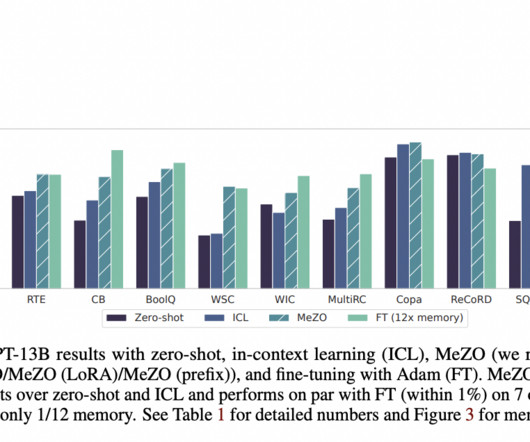
Training experiment: Training BERT Large from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently. Training a well-performing BERT Large model from scratch typically requires 450 million sequences to be processed. The first uses traditional accelerated EC2 instances.
With advancements in deep learning, naturallanguageprocessing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Traditional Computing Systems : From basic computing algorithms, the journey began.
Large language models (LLMs) have seen remarkable success in naturallanguageprocessing (NLP). Many methods have been developed to achieve comparable accuracy with reduced training costs like optimized algorithms, distributed architectures, and hardware acceleration.
Generated with Bing and edited with Photoshop Predictive AI has been driving companies’ ROI for decades through advanced recommendation algorithms, risk assessment models, and fraud detection tools. The predictive AI algorithms can be used to predict a wide range of variables, including continuous variables (e.g.,
Many different transformer models have already been implemented in Spark NLP, and specifically for text classification, Spark NLP provides various annotators that are designed to work with pretrained language models. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
The most common techniques used for extractive summarization are term frequency-inverse document frequency (TF-IDF), sentence scoring, text rank algorithm, and supervised machine learning (ML). It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary.
This chatbot, based on NaturalLanguageProcessing (NLP) and NaturalLanguage Understanding (NLU), allows users to generate meaningful text just like humans. Other LLMs, like PaLM, Chinchilla, BERT, etc., It meaningfully answers questions, summarizes long paragraphs, completes codes and emails, etc.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. Transformers and transfer-learning NaturalLanguageProcessing (NLP) systems face a problem known as the “knowledge acquisition bottleneck”. We have updated our library and this blog post accordingly.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in NaturalLanguageProcessing, and Vision Transformers in computer vision tasks. million training images, and over 50,000 validation images.
He calls the blending of AI algorithms and model architectures homogenization , a trend that helped form foundation models. That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for naturallanguageprocessing, a report on AI said at the end of that year.
Photo by adrianna geo on Unsplash NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.23.20 They fine-tuned BERT, RoBERTa, DistilBERT, ALBERT, XLNet models on siamese/triplet network structure to be used in several tasks: semantic textual similarity, clustering, and semantic search. Let’s recap.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content