This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To tackle the issue of single modality, Meta AI released the data2vec, the first of a kind, self supervised high-performance algorithm to learn patterns information from three different modalities: image, text, and speech. Why Does the AI Industry Need the Data2Vec Algorithm?
Traditional machine learning is a broad term that covers a wide variety of algorithms primarily driven by statistics. The two main types of traditional ML algorithms are supervised and unsupervised. These algorithms are designed to develop models from structured datasets. Do We Still Need Traditional Machine Learning Algorithms?
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
The explosion in deep learning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Below, we highlight a panoply of works that demonstrate Google Research’s efforts in developing new algorithms to address the above challenges.
This drastically enhanced the capabilities of computervision systems to recognize patterns far beyond the capability of humans. In this article, we present 7 key applications of computervision in finance: No.1: 4: Algorithmic Trading and Market Analysis No.5: Applications of ComputerVision in Finance No.
Understanding Computational Complexity in AI The performance of AI models depends heavily on computational complexity. This term refers to how much time, memory, or processing power an algorithm requires as the size of the input grows. Put simply, if we double the input size, the computational needs can increase fourfold.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computervision , natural language processing , and more. NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
Pixabay: by Activedia Image captioning combines natural language processing and computervision to generate image textual descriptions automatically. Image captioning integrates computervision, which interprets visual information, and NLP, which produces human language.
Recently, convolutions have emerged as a critical primitive for sequence modeling, supporting state-of-the-art performance in language modeling, time-series analysis, computervision, DNA modeling, and more. Despite being asymptotically efficient, the FFT convolution algorithm has a low wall-clock time on contemporary accelerators.
Amazon SageMaker JumpStart provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning.
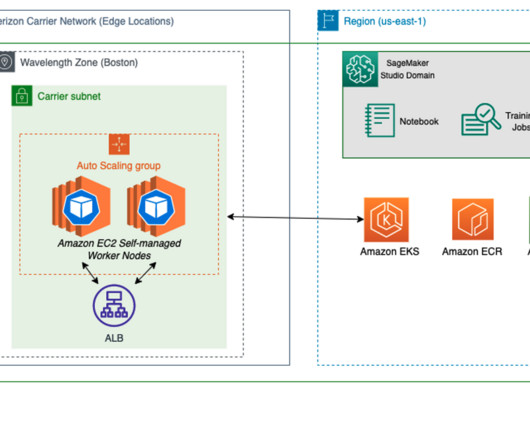
Training experiment: Training BERT Large from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently. Training a well-performing BERT Large model from scratch typically requires 450 million sequences to be processed. The first uses traditional accelerated EC2 instances.
Black box algorithms such as xgboost emerged as the preferred solution for a majority of classification and regression problems. The advent of more powerful personal computers paved the way for the gradual acceptance of deep learning-based methods.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computervision tasks. million training images, and over 50,000 validation images.
As an example, smart venue solutions can use near-real-time computervision for crowd analytics over 5G networks, all while minimizing investment in on-premises hardware networking equipment. JumpStart provides access to hundreds of built-in algorithms with pre-trained models that can be seamlessly deployed to SageMaker endpoints.
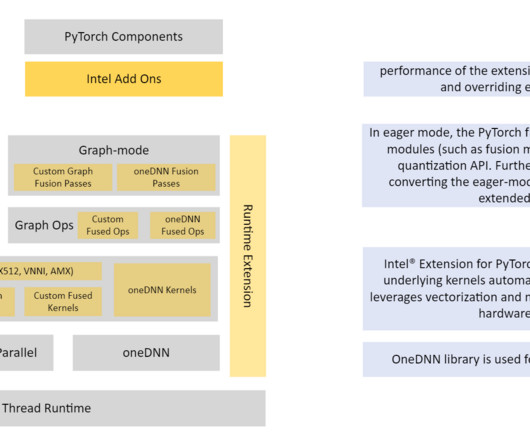
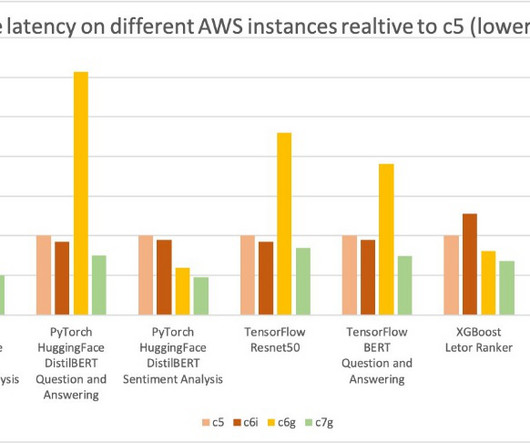
Quantization is a technique to reduce the computational and memory costs of running inference by representing the weights and activations with low-precision data types like 8-bit integer (INT8) instead of the usual 32-bit floating point (FP32). In the following example figure, we show INT8 inference performance in C6i for a BERT-base model.
Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., Use Cases for Foundation Models Applications in Pre-trained Language Models like GPT, BERT, Claude, etc. Applications in ComputerVision Models like ResNET, VGG, Image Captioning, etc. It builds algorithms to identify objects, analyze scenes, and track motion.
Product Embedding Generation: Forward Pass Algorithm The GNN approach learns two embeddings for each product: source and target. Algorithm 1 explains the procedure for generating these embeddings. Let and denote the source and target embedding for product at the step in the algorithm.
Computervision. BERT + Random Forest. SageMaker automatic model tuning, also known as hyperparameter tuning, finds the best version of a model by running many training jobs on your dataset using the algorithm and ranges of hyperparameters that you specify. BERT + Random Forest. BERT + Random Forest with HPO.
Language and vision models have experienced remarkable breakthroughs with the advent of Transformer architecture. Models like BERT and GPT have revolutionized natural language processing, while Vision Transformers have achieved significant success in computervision tasks.
Generated with Bing and edited with Photoshop Predictive AI has been driving companies’ ROI for decades through advanced recommendation algorithms, risk assessment models, and fraud detection tools. The predictive AI algorithms can be used to predict a wide range of variables, including continuous variables (e.g.,
Examples of text-only LLMs include GPT-3 , BERT , RoBERTa , etc. Why is there a need for Multimodal Language Models The text-only LLMs like GPT-3 and BERT have a wide range of applications, such as writing articles, composing emails, and coding. However, this text-only approach has also highlighted the limitations of these models.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
We cover computervision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking. For more information, see Building your own algorithm container. architecture.
About us: Viso Suite provides enterprise ML teams with 695% ROI on their computervision applications. Viso Suite makes it possible to integrate computervision into existing workflows rapidly by delivering full-scale management of the entire application lifecycle. A significant increase in errors can signal a drift.
Supervised learning Supervised learning is a widely used approach in machine learning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. SegGPT Many successful approaches from NLP are now being translated into computervision. Source: [link].
About us : Viso Suite is our end-to-end computervision infrastructure for enterprises. The powerful solution enables teams to develop, deploy, manage, and secure computervision applications in one place. Some common free-to-use pre-trained models include BERT, ResNet , YOLO etc. Book a demo to learn more.
Gain a practical understanding of the PatchTST algorithm and its application in Python, along with N-BEATS and N-HiTS, by transitioning from theoretical knowledge to hands-on implementation. Last Updated on June 28, 2023 by Editorial Team Author(s): M. Haseeb Hassan Originally published on Towards AI.
It’s dedicated to data scientists, and believe me: it’s run by some of the institution’s most experienced lecturers, including computer science and statistics professors. That’s why it helps to know the fundamentals of ML and the different learning algorithms before you do any data science work.
provides a robust end-to-end computervision infrastructure – Viso Suite. Our software helps several leading organizations start with computervision and implement deep learning models efficiently with minimal overhead for various downstream tasks. About us : Viso.ai Get a demo here. trillion words.
Vision Transformer (ViT) have recently emerged as a competitive alternative to Convolutional Neural Networks (CNNs) that are currently state-of-the-art in different image recognition computervision tasks. ViT models outperform the current state-of-the-art (CNN) by almost x4 in terms of computational efficiency and accuracy.
If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a Large Language Model (LLM). An easy way to describe LLM is an AI algorithm capable of understanding and generating human language.
This would change in 1986 with the publication of “Parallel Distributed Processing” [ 6 ], which included a description of the backpropagation algorithm [ 7 ]. In retrospect, this algorithm seems obvious, and perhaps it was. We were definitely in a Kuhnian pre-paradigmatic period. It would not be the last time that happened.)
Large language models (LLMs) are transformer-based models trained on a large amount of unlabeled text with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. We recently launched zero-shot classification model support in Amazon SageMaker JumpStart.
In technical terms, this component is made up of a UNet neural network and a scheduling algorithm. How diffusion works The central idea of generating images with diffusion models relies on the fact that we have powerful computervision models. The word “diffusion” describes what happens in this component.
Architecture and training process How CLIP resolves key challenges in computervision Practical applications Challenges and limitations while implementing CLIP Future advancements How Does CLIP Work? It often uses a transformer-based architecture, like a Transformer or BERT, to process text sequences.
The early 2000s witnessed a resurgence, fueled by advancements in hardware like GPUs, innovative algorithms such as ReLU activation and dropout, and the availability of massive datasets. Today, DNNs power cutting-edge technologies like transformers, revolutionizing fields like natural language processing and computervision.
ONNX is an open standard for representing computervision and machine learning models. ONNX (Open Neural Network Exchange) is an open-source format that facilitates interoperability between different deep learning algorithms for simple model sharing and deployment. A popular library for traditional machine learning algorithms.
Collecting, labeling, and cleaning data for computervision is a pain. Dragon is a new foundation model (improvement of BERT) that is pre-trained jointly from text and knowledge graphs for improved language, knowledge and reasoning capabilities. Dragon can be used as a drop-in replacement for BERT.
Using deep learning, computers can learn and recognize patterns from data that are considered too complex or subtle for expert-written software. In this workshop, you’ll learn how deep learning works through hands-on exercises in computervision and natural language processing.
With the increasing sophistication of the algorithms and hardware in use today and with the scale at which they run, the complexity of the software necessary to carry out day-to-day tasks only increases. You can find other posts in the series here.) Great machine learning (ML) research requires great systems.
The Role of Data Scientists and ML Engineers in Health Informatics At the heart of the Age of Health Informatics are data scientists and ML engineers who play a critical role in harnessing the power of data and developing intelligent algorithms.
After this, you can feed this file to any model like BERT, etc. Fig: Initial text file [Image by author] SQuAD format converted file [Image by author] As displayed, the Initial file is a pure text file [unstructured], and below that, you can see a SQuAD format converted JSON file [structured].
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























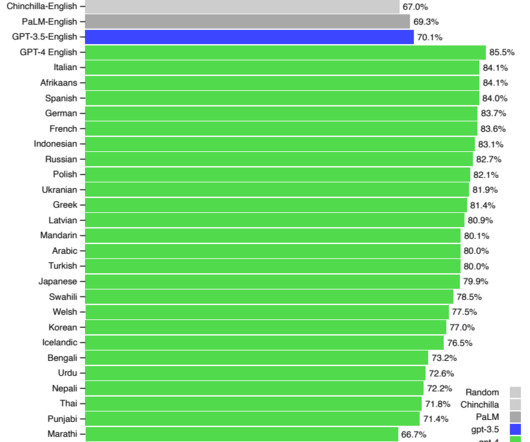















Let's personalize your content