This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post MobileBERT: BERT for Resource-Limited Devices appeared first on Analytics Vidhya. Overview As the size of the NLP model increases into the hundreds of billions of parameters, so does the importance of being able to.
This article introduces UltraFastBERT, a BERT-based framework matching the efficacy of leading BERT models but using just 0.3% of the available neurons while delivering results comparable to BERT models with a similar size and training process, especially on the downstream tasks.
In contrast, LLMs rely on static data patterns and mathematical algorithms. LLMs, such as GPT-4 and BERT , operate on entirely different principles when processing and storing information. However, despite these abilities, how LLMs store and retrieve information differs significantly from human memory. How Human Memory Works?
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
GPT, BERT) Image Generation (e.g., These are essential for understanding machine learning algorithms. Explore text generation models like GPT and BERT. Hugging Face: For working with pre-trained NLP models like GPT and BERT. Generative AI Techniques: Text Generation (e.g., GANs, DALLE) Music and Video Generation 5.
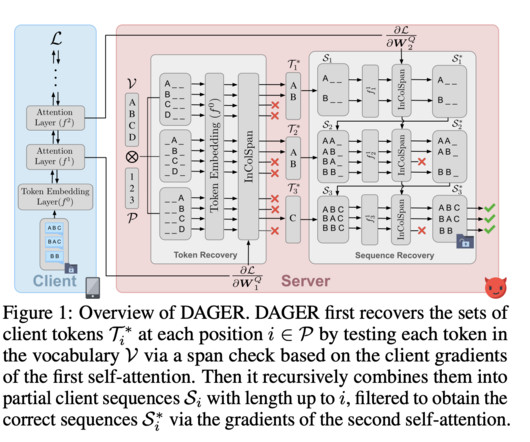
have developed DAGER, an algorithm that precisely recovers entire batches of input text. DAGER outperforms previous attacks in speed, scalability, and reconstruction quality, recovering batches up to size 128 on large language models like GPT-2, LLaMa-2, and BERT. Researchers from INSAIT, Sofia University, ETH Zurich, and LogicStar.ai
One of the earliest and widely recognized works in predictive modeling within deep learning is the Recurrent Neural Network (RNN) based language model by Tomas Mikolov , which demonstrated how predictive algorithms could capture sequential dependencies to predict future tokens in language tasks.
Most AI systems operate within the confines of their programmed algorithms and datasets, lacking the ability to extrapolate or infer beyond their training. Their approach began with an existing artificial neuron model, S-Bert, known for its language comprehension capabilities.
BERT and its Variants : BERT (Bidirectional Encoder Representations from Transformers) by Google, is another significant model that has seen various updates and iterations like RoBERTa, and DistillBERT. These models are trained on diverse datasets, enabling them to create embeddings that capture a wide array of linguistic nuances.
Once the brain signals are collected, AI algorithms process the data to identify patterns. These algorithms map the detected patterns to specific thoughts, visual perceptions, or actions. The encoder, a BERT (Bidirectional Encoder Representations from Transformers) model, transforms EEG waves into unique codes.
Googles search algorithm is powered by AI models like RankBrain and BERT, which predict what you meant to search for not just what you typed. And what does it mean for the way we consume and trust online information? When you Google something, youre not getting an organic list of the best results.
BERT is a state-of-the-art algorithm designed by Google to process text data and convert it into vectors ([link]. What makes BERT special is, apart from its good results, the fact that it is trained over billions of records and that Hugging Face provides already a good battery of pre-trained models we can use for different ML tasks.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
BERT, GPT, or T5) based on the task. Strategy Pattern The Strategy Pattern defines a family of interchangeable algorithms, encapsulating each one and allowing the behavior to change dynamically at runtime. Switching algorithms dynamically (Strategy pattern) to balance latency and accuracy based on system load or real-time constraints.
Behind the scenes, platforms rely on sophisticated algorithms to keep harmful content at bay, and the rapid growth of artificial intelligence […] The post Building Multi-Modal Models for Content Moderation on Social Media appeared first on Analytics Vidhya. Before you can even hit the report button, it’s gone.
The explosion in deep learning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Below, we highlight a panoply of works that demonstrate Google Research’s efforts in developing new algorithms to address the above challenges.
Introduction Large Language Models (LLMs) are foundational machine learning models that use deep learning algorithms to process and understand natural language. These models are trained on massive amounts of text data to learn patterns and entity relationships in the language.
To tackle the issue of single modality, Meta AI released the data2vec, the first of a kind, self supervised high-performance algorithm to learn patterns information from three different modalities: image, text, and speech. Why Does the AI Industry Need the Data2Vec Algorithm?
Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes. These deep-learning algorithms dissect individual preferences based on various musical elements such as tempo and mood to craft personalized song suggestions. Creating music using artificial intelligence began several decades ago.
Traditional machine learning is a broad term that covers a wide variety of algorithms primarily driven by statistics. The two main types of traditional ML algorithms are supervised and unsupervised. These algorithms are designed to develop models from structured datasets. Do We Still Need Traditional Machine Learning Algorithms?
These issues require more than a technical, algorithmic or AI-based solution. Additionally, the models themselves are created from limited architectures: “Almost all state-of-the-art NLP models are now adapted from one of a few foundation models, such as BERT, RoBERTa, BART, T5, etc.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
Machine learning , a subset of AI, involves three components: algorithms, training data, and the resulting model. An algorithm, essentially a set of procedures, learns to identify patterns from a large set of examples (training data). The culmination of this training is a machine-learning model. Impact of the LLM Black Box Problem 1.
the74million.org The Looming Leviathan: AI Ethics and the Reshaping of Our World Artificial intelligence (AI) has woven itself into the fabric of our lives, from the personalized shopping recommendations on our screens to the algorithms analyzing medical scans. Facebook Email icon An envelope.
Featured Community post from the Discord Aman_kumawat_41063 has created a GitHub repository for applying some basic ML algorithms. It offers pure NumPy implementations of fundamental machine learning algorithms for classification, clustering, preprocessing, and regression. Learn AI Together Community section!
Transformer Models and BERT Model : In this course, participants delve into the specifics of Transformer models and the Bidirectional Encoder Representations from Transformers (BERT) model. These courses provide a perfect foundation in AI, from understanding basic concepts to exploring advanced algorithms and architectures.
By utilizing machine learning algorithms , it produces new content, including images, text, and audio, that resembles existing data. Another breakthrough is the rise of generative language models powered by deep learning algorithms. Generative AI is an evolving field that has experienced significant growth and progress in 2023.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
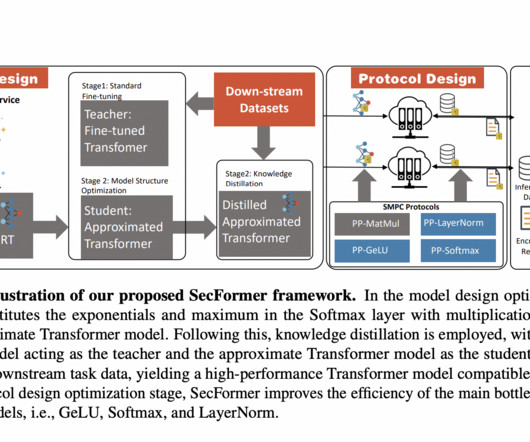
For instance, BERT BASE takes 71 seconds per sample via SMPC, compared to less than 1 second for plain-text inference ( shown in Figure 3 ). However, applying SMPC to Privacy-Preserving Inference (PPI) for large language models, particularly those based on the Transformer architecture, often results in significant performance issues.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. The code can be found on the GitHub repo.
GLEM goes further by proposing a variational EM algorithm that alternates between updating the LLM and GNN components for mutual enhancement. E-BERT aligns KG entity vectors with BERT's wordpiece embeddings, while K-BERT constructs trees containing the original sentence and relevant KG triples.
NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT. The Paillier algorithm works as depicted.
transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. the same result we are trying to achieve with “multi_class_classifier.ipynb”.
Today, we can train deep learning algorithms that can automatically extract and represent information contained in audio signals, if trained with enough data. AudioLM’s two main components w2v-BERT and SoundStream are used to represent semantic and acoustic information in audio data ( source ).
Due to this, businesses are now focusing on an ML-based approach, where different ML algorithms are trained on a large dataset of prelabeled text. These algorithms not only focus on the word but also its context in different scenarios and relation with other words. are used to classify the text sentiment.
An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages. Fine-tuning multilingual BERT models with AWS Batch GPU jobs We sought a solution to support multiple languages for our diverse user base.
Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
Amazon SageMaker JumpStart provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning.
Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
This term refers to how much time, memory, or processing power an algorithm requires as the size of the input grows. Models like GPT and BERT involve millions to billions of parameters, leading to significant processing time and energy consumption during training and inference.
The MiniGPT-5 framework, an interleaved language & vision generating algorithm technique that introduces the concept of “generative vokens” in an attempt to address the challenges mentioned above. Despite this limitation, the MiniGPT-5 framework outperforms the current state of the art baseline GILL framework across all metrics.
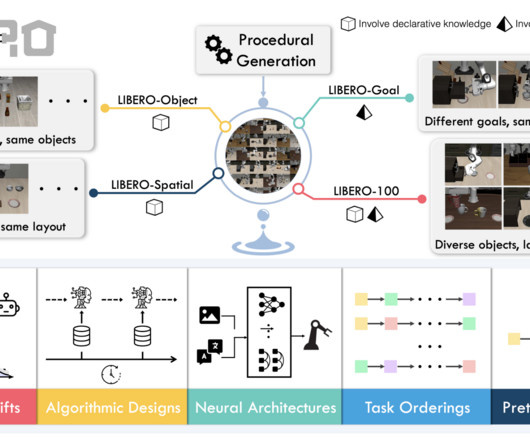
It aims to investigate essential LLDM research areas, such as knowledge transfer, neural architecture design, algorithm design, task order robustness, and pre-trained model utilization. Language instructions were encoded using pre-trained BERT embeddings.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content