This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its because the foundational principle of data-centric AI is straightforward: a model is only as good as the data it learns from. No matter how advanced an algorithm is, noisy, biased, or insufficient data can bottleneck its potential. Why is this the case? AI-assisted dataset optimization represents another frontier.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
In this process, the AI system's training data, model parameters, and algorithms are updated and improved based on input generated from within the system. Model Drift: The model’s predictive capabilities and efficiency decrease over time due to changing real-world environments. Let’s discuss this in more detail.
When AI algorithms, pre-trained models, and data sets are available for public use and experimentation, creative AI applications emerge as a community of volunteer enthusiasts builds upon existing work and accelerates the development of practical AI solutions. Morgan and Spotify.
Two of the most important concepts underlying this area of study are concept drift vs datadrift. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy. Find out how Viso Suite can automate your team’s projects by booking a demo.
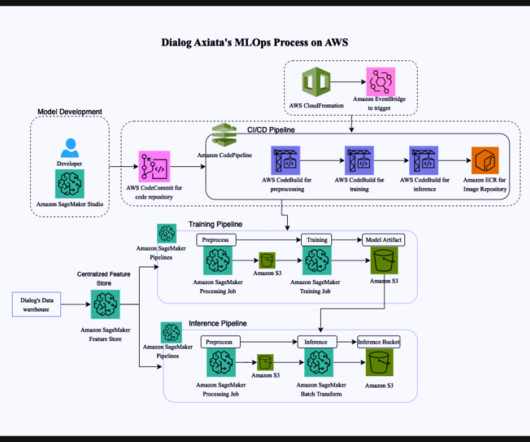
Artificial intelligence (AI) and machine learning (ML) offerings from Amazon Web Services (AWS) , along with integrated monitoring and notification services, help organizations achieve the required level of automation, scalability, and model quality at optimal cost.
Not surprisingly, data quality and drifting is incredibly important. Many datadrift error translates into poor performance of ML models which are not detected until the models have ran. A recent study of datadrift issues at Uber reveled a highly diverse perspective.
By establishing standardized workflows, automating repetitive tasks, and implementing robust monitoring and governance mechanisms, MLOps enables organizations to accelerate model development, improve deployment reliability, and maximize the value derived from ML initiatives.
You need full visibility and automation to rapidly correct your business course and to reflect on daily changes. Imagine yourself as a pilot operating aircraft through a thunderstorm; you have all the dashboards and automated systems that inform you about any risks. Autoscaling Deployments with MLOps. See DataRobot MLOps in Action.
Introduction Deepchecks is a groundbreaking open-source Python package that aims to simplify and enhance the process of implementing automated testing for machine learning (ML) models. With Deepchecks, developers can start incorporating automated testing early in their workflow and gradually build up their test suites as they go.
On the other hand, you might be building a click-through rate prediction model like Google and training that model on every single data point as it streams into the system, which is extremely complicated from an infrastructure and algorithmic perspective. That’s the datadrift problem, aka the performance drift problem.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
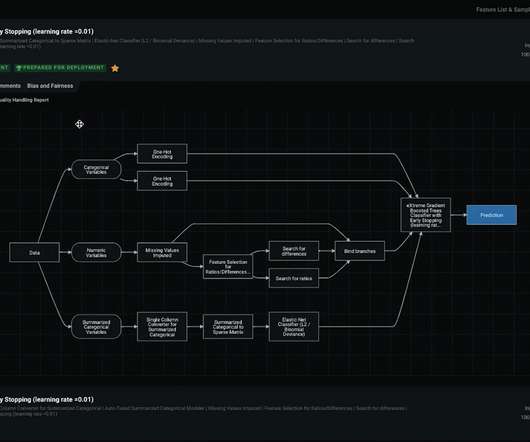
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
Concurrently, the ensemble model strategically combines the strengths of various algorithms. By conducting experiments within these automated pipelines, significant cost savings could be achieved. Datadrift and model drift are also monitored. It also helps maintain an experiment version tracking system.
This includes AWS Identity and Access Management (IAM) or single sign-on (SSO) access, security guardrails, Amazon SageMaker Studio provisioning, automated stop/start to save costs, and Amazon Simple Storage Service (Amazon S3) set up. MLOps engineering – Focuses on automating the DevOps pipelines for operationalizing the ML use case.
In this example, we take a deep dive into how real estate companies can effectively use AI to automate their investment strategies. Let’s take a look at an example use case, which showcases the effective use of AI to automate strategic decisions and explores the collaboration capabilities enabled by the DataRobot AI platform.
The ML platform can utilize historic customer engagement data, also called “clickstream data”, and transform it into features essential for the success of the search platform. From an algorithmic perspective, Learning To Rank (LeToR) and Elastic Search are some of the most popular algorithms used to build a Seach system.
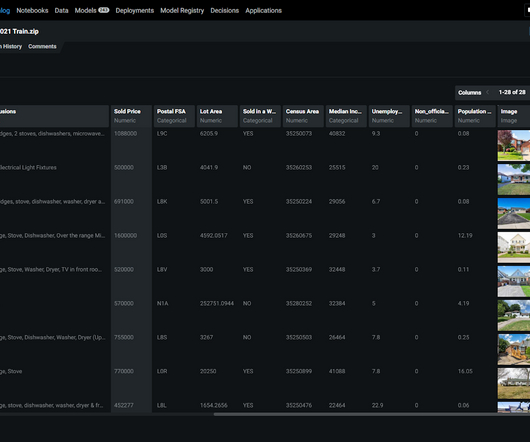
Machine learning models are only as good as the data they are trained on. Even with the most advanced neural network architectures, if the training data is flawed, the model will suffer. Data issues like label errors, outliers, duplicates, datadrift, and low-quality examples significantly hamper model performance.
This is where the DataRobot AI platform can help automate and accelerate your process from data to value, even in a scalable environment. Let’s run through the process and see exactly how you can go from data to predictions. DataRobot Blueprint—from data to predictions. Generate Model Compliance Documentation.
Ingest your data and DataRobot will use all these data points to train a model—and once it is deployed, your marketing team will be able to get a prediction to know if a customer is likely to redeem a coupon or not and why. All of this can be integrated with your marketing automation application of choice. A look at datadrift.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Automation : Automating as many tasks to reduce human error and increase efficiency. Collaboration : Ensuring that all teams involved in the project, including data scientists, engineers, and operations teams, are working together effectively. But we chose not to go with the same in our deployment due to a couple of reasons.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. By automating complex forecasting processes, AI significantly improves accuracy and efficiency in various applications.
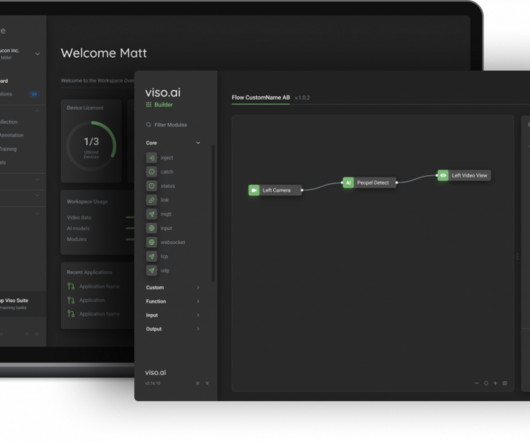
By easily integrating into existing tech stacks, Viso Suite makes it easy to automate inefficient and expensive processes. Therefore, to do face recognition, the algorithm often runs face verification. For ECG data they applied a mapping algorithm from activities to effort levels and a lightweight CNN architecture.
Data Quality Check: As the data flows through the integration step, ETL pipelines can then help improve the quality of data by standardizing, cleaning, and validating it. This ensures that the data which will be used for ML is accurate, reliable, and consistent. 4 How to create scalable and efficient ETL data pipelines.
Monitoring Monitor model performance for datadrift and model degradation, often using automated monitoring tools. Feedback loops: Use automated and human feedback to improve prompt design continuously. Deployment Deploy models through pipelines, typically involving feature stores and containerization.
The pipelines let you orchestrate the steps of your ML workflow that can be automated. The orchestration here implies that the dependencies and data flow between the workflow steps must be completed in the proper order. Reduce the time it takes for data and models to move from the experimentation phase to the production phase.
This vision is embraced by conversational interfaces which allow humans to interact with data using language, our most intuitive and universal channel of communication. After parsing a question, an algorithm encodes it into a structured logical form in the query language of choice, such as SQL. in the data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content