This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional Computing Systems : From basic computing algorithms, the journey began. Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe. AI Agents vs. ChatGPT Many advanced AI agents, such as Auto-GPT and BabyAGI, utilize the GPT architecture.
Auto-generated code suggestions can increase developers’ productivity and optimize their workflow by providing straightforward answers, handling routine coding tasks, reducing the need to context switch and conserving mental energy. It can also modernize legacy code and translate code from one programming language to another.
It suggests code snippets and even completes entire functions based on natural language prompts. TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs).
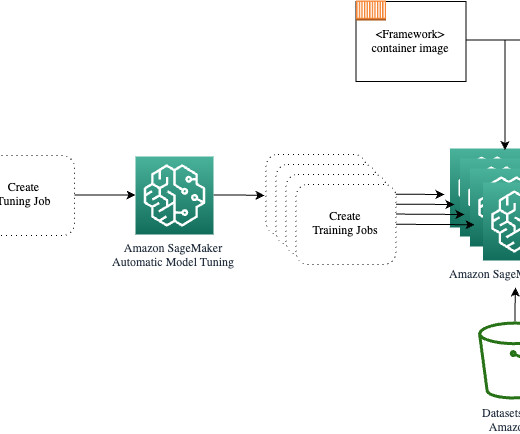
Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model. An AutoML tool applies a combination of different algorithms and various preprocessing techniques to your data. The following diagram presents the overall solution workflow.
sktime — Python Toolbox for Machine Learning with Time Series Editor’s note: Franz Kiraly is a speaker for ODSC Europe this June. Be sure to check out his talk, “ sktime — Python Toolbox for Machine Learning with Time Series ,” there! Welcome to sktime, the open community and Python framework for all things time series.
The algorithm is trained on trillions of lines of publicly accessible code from places like GitHub repositories. Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. The researchers used approximately 8.35
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. The following diagram shows our solution architecture.
Core Principles of Support Vector Regression When implementing SVR in machine learning, three fundamental components work together: The Epsilon () Tube : Defines the acceptable error margin in Support Vector Regression Controls prediction accuracy and model complexity Helps optimize the SVR model’s performance Support Vectors : Key data points (..)
The algorithm is trained on trillions of lines of publicly accessible code from places like GitHub repositories. Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. The researchers used approximately 8.35
This approach leverages search algorithms like breadth-first or depth-first search, enabling the LLM to engage in lookahead and backtracking during the problem-solving process. Performance: On various benchmark reasoning tasks, Auto-CoT has matched or exceeded the performance of manual CoT prompting.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
From completing entire lines of code and functions to writing comments and aiding in debugging and security checks, Copilot serves as an invaluable tool for developers. Mintlify Mintlify is a time-saving tool that auto-generates code documentation directly in your favorite code editor.
In early trials, cuOpt delivered routing solutions in 10 seconds , achieving a 90% reduction in cloud costs and enabling technicians to complete more service calls daily. They trained a machine learning algorithm to search the BIKG databases for genes with the designated features mentioned in literature as treatable.
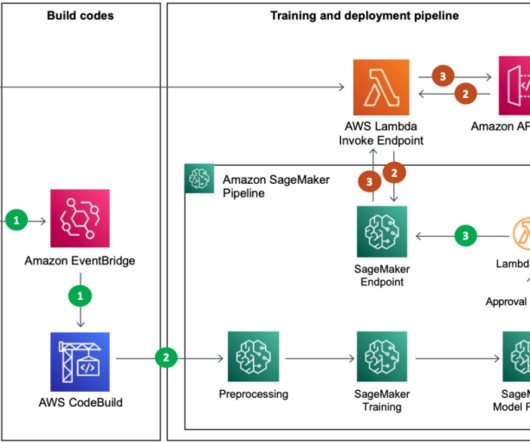
Therefore, we decided to introduce a deep learning-based recommendation algorithm that can identify not only linear relationships in the data, but also more complex relationships. When training is complete (through the Lambda step), the deployed model is updated to the SageMaker endpoint.
This is because a large portion of the available memory bandwidth is consumed by loading the model’s parameters and by the auto-regressive decoding process.As The server-side batching includes different techniques to optimize the throughput further for generative language models based on the auto-regressive decoding.
From completing entire lines of code and functions to writing comments and aiding in debugging and security checks, Copilot serves as an invaluable tool for developers. Mintlify Mintlify is a time-saving tool that auto-generates code documentation directly in your favorite code editor.
Apart from the clear performance benefit, we can be much more confident the agent will remain on track and complete the task. 2: A structured agentic flow with deterministic auto-fixing When dealing with problems in the generated output, I believe it’s best to do as much of the correction deterministically, without involving the LLM again.
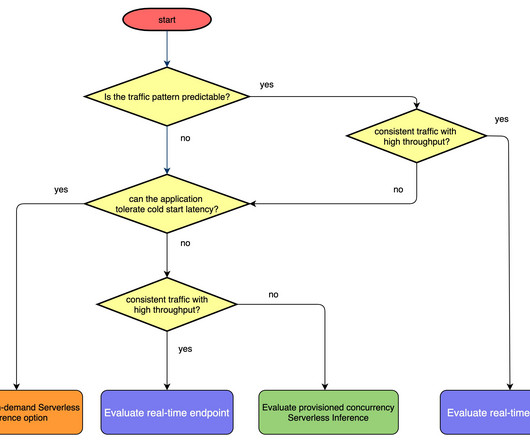
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
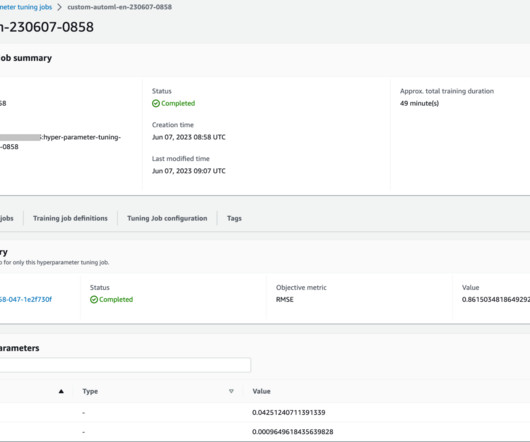
We previously explored a single job optimization, visualized the outcomes for SageMaker built-in algorithm, and learned about the impact of particular hyperparameter values. In this post, we run multiple HPO jobs with a custom training algorithm and different HPO strategies such as Bayesian optimization and random search.
Use a Python notebook to invoke the launched real-time inference endpoint. Basic knowledge of Python, Jupyter notebooks, and ML. Another option is to download complete data for your ML model training use cases using SageMaker Data Wrangler processing jobs. Load the best model to a real-time inference endpoint for predictions.
The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
Going from Data to Insights LexisNexis At HPCC Systems® from LexisNexis® Risk Solutions you’ll find “a consistent data-centric programming language, two processing platforms, and a single, complete end-to-end architecture for efficient processing.” These tools are designed to help companies derive insights from big data.
Although the direct environmental impact might not be obvious, sub-optimized code amplifies the carbon footprint of modern applications through factors like heightened energy consumption, prolonged hardware usage, and outdated algorithms. Impact of unoptimized code on cloud computing and application carbon footprint AWS’s infrastructure is 3.6
One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python. TorchScript is a static subset of Python that captures the structure of a PyTorch model. Triton uses TorchScript for improved performance and flexibility. xlarge instance.
Trending AI Open Source Projects minbpe is an open-source project from famed researcher Andrej Karpathy and provides minimal, clean code for the ( Byte Pair Encoding (BPE) algorithm commonly used in LLM tokenization. Neural Flow is a Python script for plotting the intermediate layer outputs of Mistral 7B.
You can try out this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. It’s an auto-regressive language model that uses an optimized transformer architecture. With a 180-billion-parameter size and trained on a massive 3.5-trillion-token
A complete example is available in our GitHub notebook. Python SDK support for Inference Recommender We recently released Python SDK support for Inference Recommender. This greatly simplifies the use of Inference Recommender using the Python SDK. Because XGBoost is a memory-intensive algorithm, we provide ml.m5
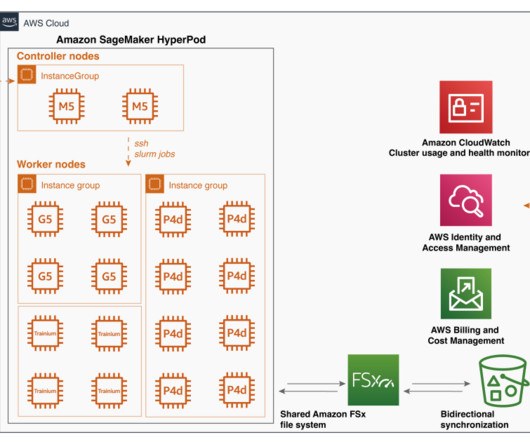
During the iterative research and development phase, data scientists and researchers need to run multiple experiments with different versions of algorithms and scale to larger models. To accelerate iteration and innovation in this field, sufficient computing resources and a scalable platform are essential.
The CodeGen model allows users to translate natural language, such as English, into programming languages, such as Python. Salesforce developed an ensemble of CodeGen models (Inline for automatic code completion, BlockGen for code block generation, and FlowGPT for process flow generation) specifically tuned for the Apex programming language.
New algorithms/software can help you systematically curate your data via automation. These techniques are based on years of research from my team, investigating what sorts of data problems can be detected algorithmically using information from a trained model. Don’t think you have to manually do all of the data curation work yourself!
Furthermore, having factoid product descriptions can increase customer satisfaction by enabling a more personalized buying experience and improving the algorithms for recommending more relevant products to users, which raise the probability that users will make a purchase. jpg and the complete metadata from styles/38642.json.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., For example, if your team works on recommender systems or natural language processing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases.
The primary focus is building a robust text search that goes beyond traditional word-matching algorithms as well as an interface for comparing search algorithms. When the job is complete, you can obtain the raw transcript data using GetTranscriptionJob. Python provides a wrapper library around the tool called ffmpeg-python.
People don’t even need the in-depth knowledge of the various machine learning algorithms as it contains pre-built libraries. It supports languages like Python and R and processes the data with the help of data flow graphs. It is an open-source framework that is written in Python and can efficiently operate on both GPUs and CPUs.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). In this article, you will learn about what sentiment analysis is and how you can build and deploy a sentiment analysis system in Python.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight.
We build a model to predict the severity (benign or malignant) of a mammographic mass lesion trained with the XGBoost algorithm using the publicly available UCI Mammography Mass dataset and deploy it using the MLOps framework. The full instructions with code are available in the GitHub repository. Choose Create key. Choose Save.
Complete the following steps to edit an existing space: On the space details page, choose Stop space. EFS mounts provide a solid alternative for sharing Python environments like conda or virtualenv across multiple workspaces. To start using Amazon CodeWhisperer, make sure that the Resume Auto-Suggestions feature is activated.
You can easily try out these models and use them with SageMaker JumpStart, which is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
The AWS Python SDK Boto3 may also be combined with Torch Dataset classes to create custom data loading code. NCCL is an NVIDIA-developed open-source library implementing inter-GPU communication algorithms. and above, AWS contributed an automated communication algorithm selection logic for EFA networks ( NCCL_ALGO can be left unset).
script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources. Create a Python job controller script that creates N training manifest files, one for each training run, and submits the jobs to the EKS cluster. script, you likely need to run a Python job to preprocess the data.
For example, you’ll be able to use the information that certain spans of text are definitely not PERSON entities, without having to provide the complete gold-standard annotations for the given example. pip install spacy-huggingface-hub huggingface-cli login # Package your pipeline python -m spacy package./en_ner_fashion./output
The pay-off is the.pipe() method, which adds data-streaming capabilities to spaCy: import spacy nlp = spacy.load('de') for doc in nlp.pipe(texts, n_threads=16, batch_size=10000): analyse_text(doc) My favourite post on the Zen of Python iterators was written by Radim, the creator of Gensim. This is what I’ve done with spaCy.
If you’re focused on a project with numerous stored charts, you’ve tested a couple of metrics, or you’ve been working iteratively on an algorithm — well, we have the resource for you. You can see the complete installation process by clicking here. You should now have everything you need to complete this tutorial.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content