This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
sktime — Python Toolbox for Machine Learning with Time Series Editor’s note: Franz Kiraly is a speaker for ODSC Europe this June. Be sure to check out his talk, “ sktime — Python Toolbox for Machine Learning with Time Series ,” there! Welcome to sktime, the open community and Python framework for all things time series.
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). Kite Kite is an AI-driven coding assistant specifically designed to accelerate development in Python and JavaScript.
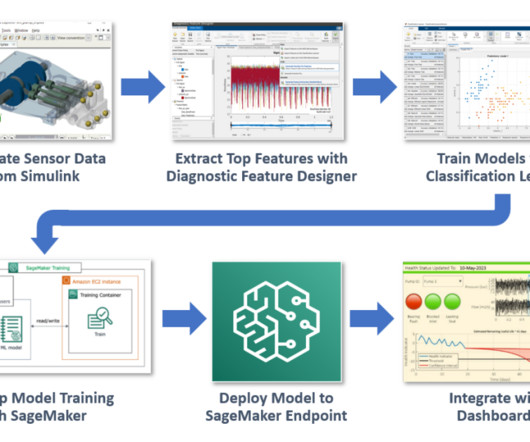
Because we have a model of the system and faults are rare in operation, we can take advantage of simulated data to train our algorithm. Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. Install Python if necessary. classifierModel = fitctree(.
Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. One of the most popular models available today is XGBoost.
The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python. TorchScript is a static subset of Python that captures the structure of a PyTorch model. Triton uses TorchScript for improved performance and flexibility.
It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment. This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. Auto scaling. With this sample payload, we strive to achieve 1000 TPS.
We train an XGBoost model for a classification task on a credit card fraud dataset. Model Framework XGBoost Model Size 10 MB End-to-End Latency 100 milliseconds Invocations per Second 500 (30,000 per minute) ML Task Binary Classification Input Payload 10 KB We use a synthetically created credit card fraud dataset.
Low-Code PyCaret: Let’s start off with a low-code open-source machine learning library in Python. Without a deep understanding of underlying algorithms and techniques, novices can dip their toes in the waters of machine learning because PyCaret takes care of much of the heavy lifting for them.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., For example, if your team works on recommender systems or natural language processing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases.
Use a Python notebook to invoke the launched real-time inference endpoint. Basic knowledge of Python, Jupyter notebooks, and ML. To understand more about PCA and dimensionality reduction, refer to Principal Component Analysis (PCA) Algorithm. For Training method and algorithms , select Auto. Choose Add step.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). are getting famous with use cases like image classification, object detection, chat-bots, text generation, and more. So let’s get the buggy war started!
People don’t even need the in-depth knowledge of the various machine learning algorithms as it contains pre-built libraries. It supports languages like Python and R and processes the data with the help of data flow graphs. This framework can perform classification, regression, etc., It is an open source framework.
This is the reason why data scientists need to be actively involved in this stage as they need to try out different algorithms and parameter combinations. BentoML : BentoML is a Python-first tool for deploying and maintaining machine learning models in production. We also save the trained model as an artifact using wandb.save().
New algorithms/software can help you systematically curate your data via automation. These techniques are based on years of research from my team, investigating what sorts of data problems can be detected algorithmically using information from a trained model. Don’t think you have to manually do all of the data curation work yourself!
Optuna also offers a variety of search algorithms and pruning techniques that can further improve the optimization process. Comparing Grid Search and Optuna for Hyperparameter Tuning: A Code Analysis As an example, I give python codes to hyper-parameter tuning for the Supper Vector Machine(SVM) model’s parameters. We have 0.84
Language complexity: Some languages, such as Chinese and Arabic, have complex characters and scripts that can make them more difficult to process using NLP algorithms. For text classification, however, there are many similarities. Snorkel Flow’s “Auto-Suggest Key Terms” feature works on any language with “white-space” tokenization.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. eks-create.sh This will create one instance of each type.
Simulation of consumption of queue up to drivers estimated position becomes an easy simple algorithm and results in wait time classification. Libraries Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. The Python scientific visualisation landscape is huge.
Generative artificial intelligence (AI) refers to AI algorithms designed to generate new content, such as images, text, audio, or video, based on a set of learned patterns and data. For information on incorporating autoscaling in your endpoint, see Going Production: Auto-scaling Hugging Face Transformers with Amazon SageMaker.
Furthermore, it ensures that data is consistent while effectively increasing the readability of the data’s algorithm. One way to solve Data Science’s challenges in Data Cleaning and pre-processing is to enable Artificial Intelligence technologies like Augmented Analytics and Auto-feature Engineering.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machine learning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science?
Throughout 2022, we gave over 224 grants to researchers and over $10M in Google Cloud Platform credits for topics ranging from the improvement of algorithms for post-quantum cryptography with collaborators at CNRS in France to fostering cybersecurity research at TU Munich and Fraunhofer AISEC in Germany.
These models are trained on massive amounts of text data using deep learning algorithms. Then you can use the model to perform tasks such as text generation, classification, and translation. If you already run your experiments on the DataRobot GUI, you could even add it as a custom task. and its affiliates.
These steps include defining business and project objectives, acquiring and exploring data, modeling the data with various algorithms, interpreting and communicating the project outcome, and implementing and maintaining the project. These Python virtual environments encapsulate and manage Python dependencies.
A day or two after some big research lab announces a state-of-the-art result on classifying images, extracting information from text, or detecting cyber attacks, you can go find that same model and replicate those state-of-the-art results with a couple lines of Python code and an internet connection. This could be something really simple.
A day or two after some big research lab announces a state-of-the-art result on classifying images, extracting information from text, or detecting cyber attacks, you can go find that same model and replicate those state-of-the-art results with a couple lines of Python code and an internet connection. This could be something really simple.
You can easily try out these models and use them with SageMaker JumpStart, which is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning.
Experimentation: With a structured pipeline, it’s easier to track experiments and compare different models or algorithms. The preprocessing stage involves cleaning, transforming, and encoding the data, making it suitable for machine learning algorithms. It makes the training iterations fast and trustable.
The base models can be diverse and trained by different algorithms. For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. TGI is implemented in Python and uses the PyTorch framework.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
The Inference Challenge with Large Language Models Before the advent of LLMs, natural language processing relied on smaller models focused on specific tasks like text classification, named entity recognition, and sentiment analysis. Let's start by understanding why LLM inference is so challenging compared to traditional NLP models.
Most employees don’t master the conventional data science toolkit (SQL, Python, R etc.). After parsing a question, an algorithm encodes it into a structured logical form in the query language of choice, such as SQL. in the data. section “Enriching the prompt with database information”).
Given the expansive realm of image forgery detection, we use the Error Level Analysis (ELA) algorithm as an illustrative method for detecting forgeries. Specifically, the JPEG algorithm operates on an 8×8 pixel grid. The model outputs the classification as 0, representing an untampered image. CPU or GPU Optimized.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content