This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Second, the LightAutoML framework limits the range of machine learning models purposefully to only two types: linear models, and GBMs or gradient boosted decision trees, instead of implementing large ensembles of different algorithms. Finally, the CV Preset works with image data with the help of some basic tools.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
This article will explore the latest advances in pose analytics algorithms and AI vision techniques, their applications and use cases, and their limitations. However, modern deeplearning based approaches have achieved major breakthroughs by improving the performance significantly for both single-person and multi-person pose estimation.
Furthermore, ML models are often dependent on DeepLearning, Deep Neural Networks, Application Specific Integrated Circuits (ASICs) and Graphic Processing Units (GPUs) for processing the data, and they often have a higher power & memory requirement.
How to use deeplearning (even if you lack the data)? To train a computer algorithm when you don’t have any data. Read on to learn how to use deeplearning in the absence of real data. What is deeplearning? First, let’s (briefly) tackle an important question: What is deeplearning?
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? However, we already know that: Machine Learning models deliver better results in terms of accuracy when we are dealing with interrelated series and complex patterns in our data.
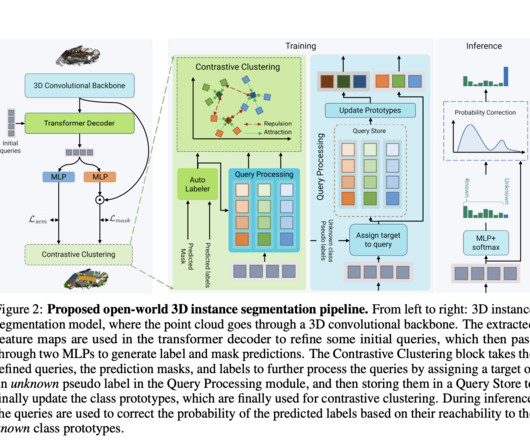
By providing object instance-level classification and semantic labeling, 3D semantic instance segmentation tries to identify items in a given 3D scene represented by a point cloud or mesh. The unknown classes are ignored by current techniques that learn on a fixed set and are also watched over and given the background label.
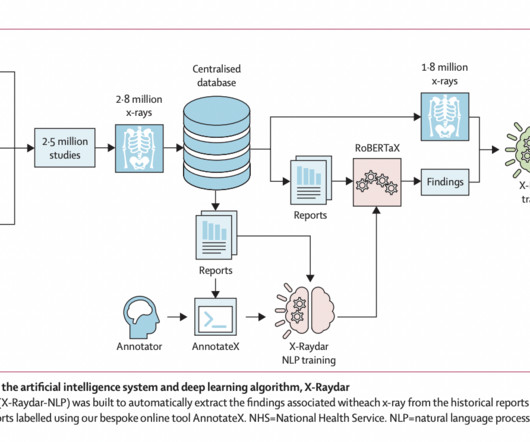
A custom-trained natural language processing (NLP) algorithm, X-Raydar-NLP, labeled the chest X-rays using a taxonomy of 37 findings extracted from the reports. The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset.
About this series In this series , we will learn how to code the must-to-know deeplearningalgorithms such as convolutions, backpropagation, activation functions, optimizers, deep neural networks, and so on using only plain and modern C++. else if (z <= -45.) result = 0.; else result = 1. / (1. + A hamster?
Photo by NASA on Unsplash Hello and welcome to this post, in which I will study a relatively new field in deeplearning involving graphs — a very important and widely used data structure. This post includes the fundamentals of graphs, combining graphs and deeplearning, and an overview of Graph Neural Networks and their applications.
Carl Froggett, is the Chief Information Officer (CIO) of Deep Instinct , an enterprise founded on a simple premise: that deeplearning , an advanced subset of AI, could be applied to cybersecurity to prevent more threats, faster. From there, we validate and classify data ourselves with algorithms we developed internally.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. In this post, we dive deep to see how Amazon SageMaker can serve these models using NVIDIA Triton Inference Server.
Triton implements multiple scheduling and batching algorithms that can be configured on a model-by-model basis. When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
The architecture is an auto-regressive architecture, i.e., the model produces one word at a time and then takes in the sequence attached with the predicted word, to predict the next word. To perform this, extractive summarization methods like tf-idf, and text-rank algorithms have been used.
Without a deep understanding of underlying algorithms and techniques, novices can dip their toes in the waters of machine learning because PyCaret takes care of much of the heavy lifting for them. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python.
CLIP model CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification. This is where the power of auto-tagging and attribute generation comes into its own. Moreover, auto-generated tags or attributes can substantially improve product recommendation algorithms.
A machine learning framework is a library, interface or any tool that is generally open source and enables the people to build various machine learning models with ease. People don’t even need the in-depth knowledge of the various machine learningalgorithms as it contains pre-built libraries.
It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment. This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. Auto scaling. With this sample payload, we strive to achieve 1000 TPS.
The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
This is the reason why data scientists need to be actively involved in this stage as they need to try out different algorithms and parameter combinations. Evidently : Evidently AI is an open-source Python library for monitoring machine learning models during development, validation, and in production.
These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera. MP involves identifying and removing redundant or unnecessary model parameters using various pruning algorithms. 2020 or Hoffman et al.,
Machine learning has increased considerably in several areas due to its performance in recent years. Thanks to modern computers’ computing capacity and graphics cards, deeplearning has made it possible to achieve results that sometimes exceed those experts give.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. eks-create.sh This will create one instance of each type.
Generative artificial intelligence (AI) refers to AI algorithms designed to generate new content, such as images, text, audio, or video, based on a set of learned patterns and data. Hugging Face and Amazon introduced Hugging Face DeepLearning Containers (DLCs) to scale fine tuning tasks across multiple GPUs and nodes.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machine learning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science?
We also help make global conferences accessible to more researchers around the world, for example, by funding 24 students this year to attend DeepLearning Indaba in Tunisia. Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M
However, NLP has reentered with the development of more sophisticated algorithms, deeplearning, and vast datasets in recent years. Example 4: Sentiment Analysis & Text Classification Brands tap into NLP for sentiment analysis, sifting through thousands of online reviews or social media mentions to gauge public sentiment.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). are getting famous with use cases like image classification, object detection, chat-bots, text generation, and more. So let’s get the buggy war started!
The creation of foundation models is one of the key developments in the field of large language models that is creating a lot of excitement and interest amongst data scientists and machine learning engineers. These models are trained on massive amounts of text data using deeplearningalgorithms. and its affiliates.
The machine learning (ML) lifecycle defines steps to derive values to meet business objectives using ML and artificial intelligence (AI). Use Case To drive the understanding of the containerization of machine learning applications, we will build an end-to-end machine learningclassification application. scikit-learn==1.1.1
Embeddings are essential for LLMs to understand natural language, enabling them to perform tasks like text classification, question answering, and more. Optimization: Use database optimizations like approximate nearest neighbor ( ANN ) search algorithms to balance speed and accuracy in retrieval tasks.
These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. He’s a graduate of University of Colorado at Boulder, where he applied deeplearning to improve knowledge tracking on a K-12 online tutoring platform.
The base models can be diverse and trained by different algorithms. For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Utilizing the latest Hugging Face LLM modules on Amazon SageMaker, AWS customers can now tap into the power of SageMaker deeplearning containers (DLCs).
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
The Inference Challenge with Large Language Models Before the advent of LLMs, natural language processing relied on smaller models focused on specific tasks like text classification, named entity recognition, and sentiment analysis. Let's start by understanding why LLM inference is so challenging compared to traditional NLP models.
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. We provide guidance on building, training, and deploying deeplearning networks on Amazon SageMaker.
Amazon SageMaker Canvas is a no-code workspace that enables analysts and citizen data scientists to generate accurate machine learning (ML) predictions for their business needs. You can also view the entire model building workflow, including suggested preprocessing steps, algorithms, and hyperparameter ranges in a notebook.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content