This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
AI-powered tools have become indispensable for automating tasks, boosting productivity, and improving decision-making. TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs).
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? without much tuning of the algorithm which is not bad at all! 21% compared to the Auto-Forecasting one — quite impressive! But what does this look like in practice?
MATLAB is a popular programming tool for a wide range of applications, such as data processing, parallel computing, automation, simulation, machine learning, and artificial intelligence. Because we have a model of the system and faults are rare in operation, we can take advantage of simulated data to train our algorithm.
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. This post illustrates how you can automate and simplify metadata generation using custom models by Amazon Comprehend. Custom classification is a two-step process.
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. To mitigate these risks, the FL model uses personalized training algorithms and effective masking and parameterization before sharing information with the training coordinator.
They’re actively creating the future of automation in what’s known as Robotic Process Automation 2.0. Source: Grand View Research What is Robotic Process Automation (RPA)? let’s first explain basic Robotic Process Automation. used Robotic Process Automation 2.0 But that’s not all they’re doing. Happy reading!
To train a computer algorithm when you don’t have any data. These days, with a little ingenuity, you can automate the task. In deep learning, a computer algorithm uses images, text, or sound to learn to perform a set of classification tasks. Say, you want to auto-detect headers in a document. It’s a tricky task.
By establishing standardized workflows, automating repetitive tasks, and implementing robust monitoring and governance mechanisms, MLOps enables organizations to accelerate model development, improve deployment reliability, and maximize the value derived from ML initiatives.
For example, if your team works on recommender systems or natural language processing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. It’s a binary classification problem where the goal is to predict whether a customer is a credit risk.
Without a deep understanding of underlying algorithms and techniques, novices can dip their toes in the waters of machine learning because PyCaret takes care of much of the heavy lifting for them. Like PyCaret, some aspects are automated such as feature engineering, hyperparameter tuning, and model selection.
Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it. The final outcome is an auto scaling, robust, and dynamically monitored solution.
For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. CLIP model CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification.
Codify Operations for Efficiency and Reproducibility By performing operations as code and incorporating automated deployment methodologies, organizations can achieve scalable, repeatable, and consistent processes. Build and release optimization – This area emphasizes the implementation of standardized DevSecOps processes.
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. Additionally, the researchers share a simple counterfactual fairness correction algorithm. A case for reframing automated medical image classification as segmentation Hooper et al.
During the training phase, we add “noise,” which changes the raw data from the files we feed into our algorithm, in order to automatically generate slight “mutations,” which are fed in each training cycle during our training phase. From there, we validate and classify data ourselves with algorithms we developed internally.
New algorithms/software can help you systematically curate your data via automation. These techniques are based on years of research from my team, investigating what sorts of data problems can be detected algorithmically using information from a trained model.
For Problem type , select Classification. In the following example, we drop the columns Timestamp, Country, state, and comments, because these features will have least impact for classification of our model. For Training method , select Auto. For more information, see Training modes and algorithm support. Choose Create.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code. Choose Add step.
In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. Additionally, the researchers share a simple counterfactual fairness correction algorithm. A case for reframing automated medical image classification as segmentation Hooper et al.
People don’t even need the in-depth knowledge of the various machine learning algorithms as it contains pre-built libraries. This framework can perform classification, regression, etc., Most of the organizations make use of Caffe in order to deal with computer vision and classification related problems.
Amazon SageMaker Inference Recommender is a capability of Amazon SageMaker that reduces the time required to get ML models in production by automating load testing and model tuning across SageMaker ML instances. We train an XGBoost model for a classification task on a credit card fraud dataset. large", "ml.m5.xlarge",
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from data preparation to model deployment. It provides a straightforward way to create high-quality models tailored to your specific problem type, be it classification, regression, or forecasting, among others.
Language complexity: Some languages, such as Chinese and Arabic, have complex characters and scripts that can make them more difficult to process using NLP algorithms. For text classification, however, there are many similarities. Snorkel Flow’s “Auto-Suggest Key Terms” feature works on any language with “white-space” tokenization.
Natural Language Processing seeks to automate the interpretation of human language by machines. However, NLP has reentered with the development of more sophisticated algorithms, deep learning, and vast datasets in recent years. Imagine training a computer to navigate this intricately woven tapestry—it’s no small feat!
[Summary] tl;dr: A tremendous amount of effort has been poured into training AI algorithms to competitively play games that computers have traditionally had trouble with, such as the retro games published by Atari, Go, DotA, and StarCraft II. Can the same algorithms that master Atari games help us grade these game assignments?
Furthermore, it ensures that data is consistent while effectively increasing the readability of the data’s algorithm. One way to solve Data Science’s challenges in Data Cleaning and pre-processing is to enable Artificial Intelligence technologies like Augmented Analytics and Auto-feature Engineering.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. W&B Sweeps will automate this kind of exploration.
You can easily try out these models and use them with SageMaker JumpStart, which is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. Default is 5.
Monitoring Monitor model performance for data drift and model degradation, often using automated monitoring tools. Feedback loops: Use automated and human feedback to improve prompt design continuously. Models are part of chains and agents, supported by specialized tools like vector databases.
Take that canonical spam classification example: if you see the phrase wire transfer , maybe it’s more likely to be spam. Rather than just throwing it away, we can use it to auto-generate labels and train machine-learning models that can then learn to extend beyond what’s in these expansive but sometimes brittle knowledge bases.
Take that canonical spam classification example: if you see the phrase wire transfer , maybe it’s more likely to be spam. Rather than just throwing it away, we can use it to auto-generate labels and train machine-learning models that can then learn to extend beyond what’s in these expansive but sometimes brittle knowledge bases.
These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. This operator simplifies the process of running distributed training jobs by automating the deployment and scaling of the necessary components.
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Specifically, the JPEG algorithm operates on an 8×8 pixel grid.
Efficiency: Pipelines automate repetitive tasks, reducing manual intervention and saving time. Experimentation: With a structured pipeline, it’s easier to track experiments and compare different models or algorithms. Model Training: The preprocessed data is fed into the chosen ML algorithm to train the model. Build the pipeline.
The base models can be diverse and trained by different algorithms. For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
SageMaker provides automated model tuning , which manages the undifferentiated heavy lifting of provisioning and managing compute infrastructure to run several iterations and select the optimized model candidate from training. Best Egg trains multiple credit models using classification and regression algorithms.
After parsing a question, an algorithm encodes it into a structured logical form in the query language of choice, such as SQL. High-quality , so that the Text2SQL algorithm does not have to deal with excessive noise (inconsistencies, empty values etc.) in the data. section “Enriching the prompt with database information”).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



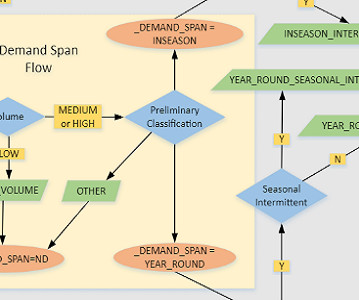
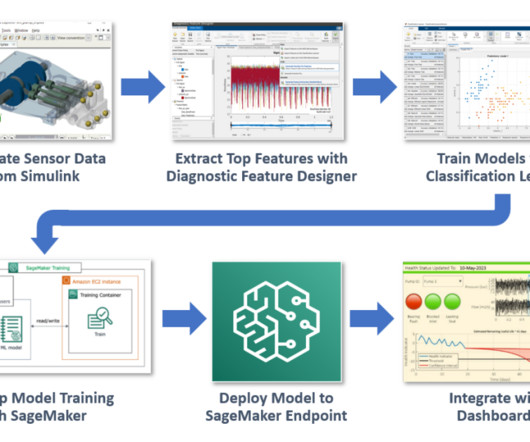


































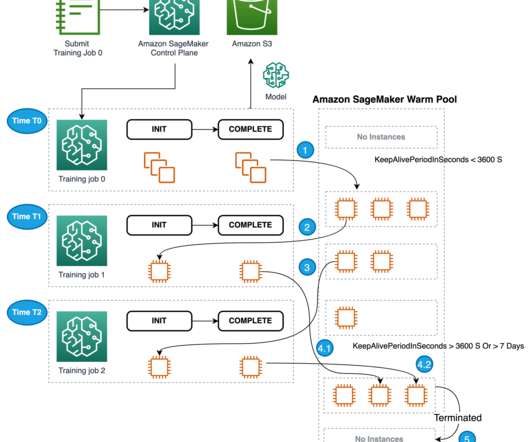







Let's personalize your content