This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Second, the LightAutoML framework limits the range of machine learning models purposefully to only two types: linear models, and GBMs or gradient boosted decision trees, instead of implementing large ensembles of different algorithms. Holdout Validation : The Holdout validation scheme is implemented if the holdout set is specified.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
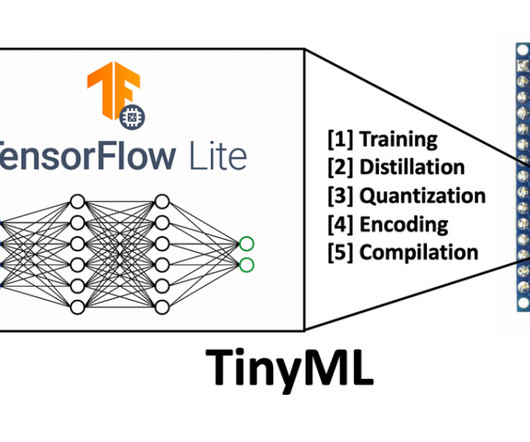
It would be safe to say that TinyML is an amalgamation of software, hardware, and algorithms that work in sync with each other to deliver the desired performance. Finally, applications & systems built on the TinyML algorithm must have the support of new algorithms that need low memory sized models to avoid high memory consumption.
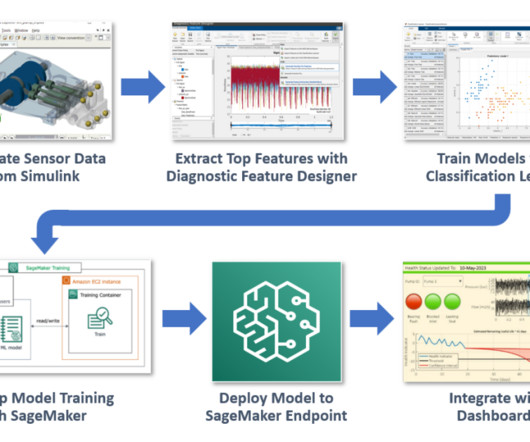
Because we have a model of the system and faults are rare in operation, we can take advantage of simulated data to train our algorithm. Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. To learn how to train RUL algorithms, see Predictive Maintenance Toolbox.
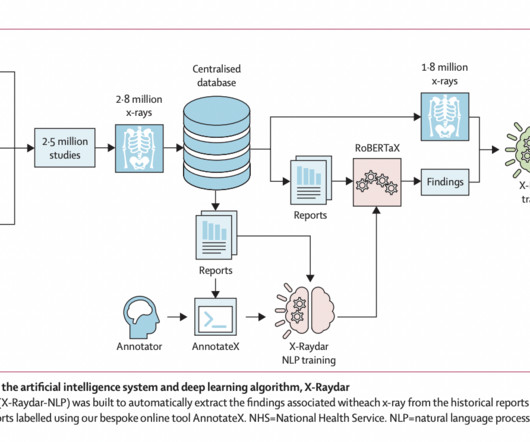
A custom-trained natural language processing (NLP) algorithm, X-Raydar-NLP, labeled the chest X-rays using a taxonomy of 37 findings extracted from the reports. The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test.
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. Amazon Comprehend custom classification API is used to organize your documents into categories (classes) that you define. Custom classification is a two-step process.
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? without much tuning of the algorithm which is not bad at all! After implementing our changes, the demand classification pipeline reduces the overall error in our forecasting process by approx.
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). It can generate complex algorithms and translate code between programming languages.
To mitigate these risks, the FL model uses personalized training algorithms and effective masking and parameterization before sharing information with the training coordinator. module.eks_blueprints_kubernetes_addons -auto-approve terraform destroy -target=module.m_fedml_edge_client_2.module.eks_blueprints_kubernetes_addons
Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
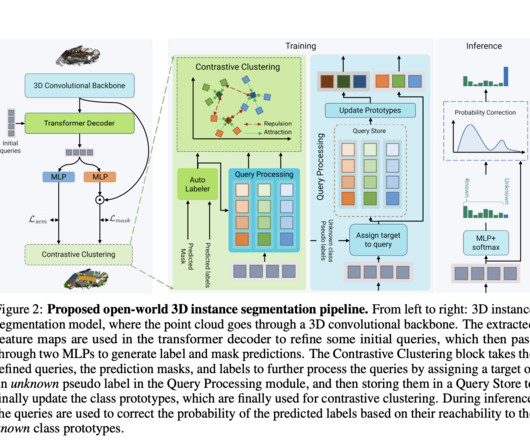
By providing object instance-level classification and semantic labeling, 3D semantic instance segmentation tries to identify items in a given 3D scene represented by a point cloud or mesh. This makes it impossible for intelligent identification algorithms to recognize unidentified or unusual things that are not background elements.
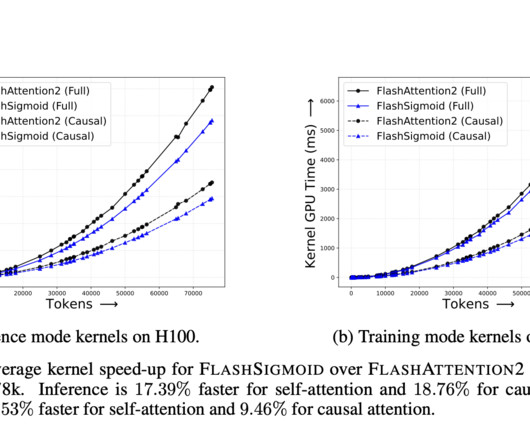
In supervised image classification and self-supervised learning, there’s a trend towards using richer pointwise Bernoulli conditionals parameterized by sigmoid functions, moving away from output conditional categorical distributions typically parameterized by softmax. Key observations from the empirical studies include: 1.
Back then we were, like many in the industry, focused on developing new algorithms and—i.e. Researchers still do great work in model-centric AI, but off-the-shelf models and auto ML techniques have improved so much that model choice has become commoditized at production time.
A typical application of GNN is node classification. The problems that GNNs are used to solve can be divided into the following categories: Node Classification: The goal of this task is to determine the labeling of samples (represented as nodes) by examining the labels of their immediate neighbors (i.e., their neighbors’ labels).
To train a computer algorithm when you don’t have any data. You can create synthetic data that acts just like real data – and so allows you to train a deep learning algorithm to solve your business problem, leaving your sensitive data with its sense of privacy, intact. Say, you want to auto-detect headers in a document.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it. The final outcome is an auto scaling, robust, and dynamically monitored solution.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. It’s a binary classification problem where the goal is to predict whether a customer is a credit risk.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. threshold – This is a score threshold for determining classification.
The Inference Challenge with Large Language Models Before the advent of LLMs, natural language processing relied on smaller models focused on specific tasks like text classification, named entity recognition, and sentiment analysis. Let's start by understanding why LLM inference is so challenging compared to traditional NLP models.
The base models can be diverse and trained by different algorithms. For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model.
Without a deep understanding of underlying algorithms and techniques, novices can dip their toes in the waters of machine learning because PyCaret takes care of much of the heavy lifting for them. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python.
CLIP model CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification. This is where the power of auto-tagging and attribute generation comes into its own. Moreover, auto-generated tags or attributes can substantially improve product recommendation algorithms.
The architecture is an auto-regressive architecture, i.e., the model produces one word at a time and then takes in the sequence attached with the predicted word, to predict the next word. To perform this, extractive summarization methods like tf-idf, and text-rank algorithms have been used.
It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment. This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. Auto scaling. With this sample payload, we strive to achieve 1000 TPS.
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. Additionally, the researchers share a simple counterfactual fairness correction algorithm. A case for reframing automated medical image classification as segmentation Hooper et al.
Triton implements multiple scheduling and batching algorithms that can be configured on a model-by-model basis. When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group.
New algorithms/software can help you systematically curate your data via automation. These techniques are based on years of research from my team, investigating what sorts of data problems can be detected algorithmically using information from a trained model. Don’t think you have to manually do all of the data curation work yourself!
Data scientists train multiple ML algorithms to examine millions of consumer data records, identify anomalies, and evaluate if a person is eligible for credit. Best Egg trains multiple credit models using classification and regression algorithms. Inference is run in two ways—real time and batch—based on the user requirements.
In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
During the training phase, we add “noise,” which changes the raw data from the files we feed into our algorithm, in order to automatically generate slight “mutations,” which are fed in each training cycle during our training phase. From there, we validate and classify data ourselves with algorithms we developed internally.
For example, if your team works on recommender systems or natural language processing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. Scale AI combines human annotators and machine learning algorithms to deliver efficient and reliable annotations for your team.
For Problem type , select Classification. In the following example, we drop the columns Timestamp, Country, state, and comments, because these features will have least impact for classification of our model. For Training method , select Auto. For more information, see Training modes and algorithm support. Choose Create.
This is the reason why data scientists need to be actively involved in this stage as they need to try out different algorithms and parameter combinations. It checks data and model quality, data drift, target drift, and regression and classification performance. We also save the trained model as an artifact using wandb.save().
To understand more about PCA and dimensionality reduction, refer to Principal Component Analysis (PCA) Algorithm. In this case, because we’re training the dataset to predict whether the transaction is fraudulent or valid, we use binary classification. For Training method and algorithms , select Auto. Choose Add step.
Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. language models, image classification models, or speech recognition models). Let’s get started! The Pix2Seq framework for object detection.
The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
Given the expansive realm of image forgery detection, we use the Error Level Analysis (ELA) algorithm as an illustrative method for detecting forgeries. Specifically, the JPEG algorithm operates on an 8×8 pixel grid. The model outputs the classification as 0, representing an untampered image.
Optuna also offers a variety of search algorithms and pruning techniques that can further improve the optimization process. I have the binary classification problem that is why I try to make maximize F1 score. F1 score and parameters: {‘C’: 4, ‘kernel’: ‘poly’, ‘degree’: 1, ‘gamma’: ‘auto’}. We have 0.84
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. Additionally, the researchers share a simple counterfactual fairness correction algorithm. A case for reframing automated medical image classification as segmentation Hooper et al.
People don’t even need the in-depth knowledge of the various machine learning algorithms as it contains pre-built libraries. This framework can perform classification, regression, etc., Most of the organizations make use of Caffe in order to deal with computer vision and classification related problems.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
In short: RPA is a set of algorithms that integrate different applications, simplifying mundane, monotonous, and repetitive tasks; these include switching between applications, logging into a system, downloading files, and copying data. Source: Grand View Research What is Robotic Process Automation (RPA)? Before we get to RPA 2.0,
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content