This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data. A metadata layer helps build the relationship between the raw data and AI extracted output.
When building machine learning (ML) models using preexisting datasets, experts in the field must first familiarize themselves with the data, decipher its structure, and determine which subset to use as features. So much so that a basic barrier, the great range of data formats, is slowing advancement in ML.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Rightsify’ s Global Copyright Exchange (GCX) offers vast collections of copyright-cleared music datasets tailored for machine learning and generative AI music initiatives. Text, Stem, MIDI, and sheet music pairings for audio are bundled with their AI music datasets, furnishing comprehensive resources for ML projects.
Despite advances in image and text-based AI research, the audio domain lags due to the absence of comprehensive datasets comparable to those available for computer vision or natural language processing. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
Knowledge bases effectively bridge the gap between the broad knowledge encapsulated within foundation models and the specialized, domain-specific information that businesses possess, enabling a truly customized and valuable generative artificial intelligence (AI) experience.
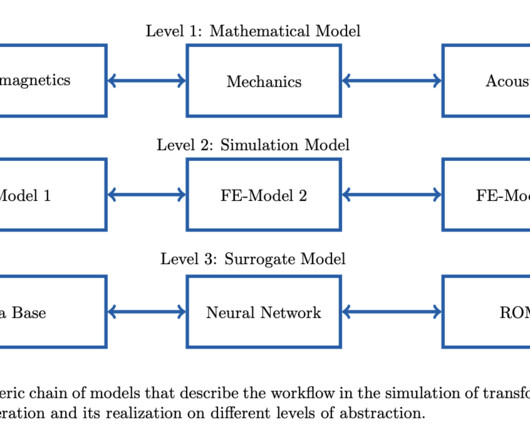
FMI’s container-based approach aids in replicating simulations but requires metadata for broader reproducibility and adaptation. MaRDIFlow’s design principle revolves around treating components as abstract objects defined by their input-output behavior and metadata. If you like our work, you will love our newsletter.
Artificial intelligence (AI) is now at the forefront of how enterprises work with data to help reinvent operations, improve customer experiences, and maintain a competitive advantage. The first step for successful AI is access to trusted, governed data to fuel and scale the AI. All of this supports the use of AI.
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. The data mesh architecture aims to increase the return on investments in data teams, processes, and technology, ultimately driving business value through innovative analytics and ML projects across the enterprise.
The company implements AI to the task of preventing and detecting malware. The term “AI” is broadly used as a panacea to equip organizations in the battle against zero-day threats. ML is unfit for the task. Not all AI is equal. Unlike ML, DL is built on neural networks, enabling it to self-learn and train on raw data.
Today is a revolutionary moment for Artificial Intelligence (AI). After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. The answer is that generative AI leverages recent advances in foundation models.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality. MeCo leverages readily available metadata, such as source URLs, during the pre-training phase.
Artificial intelligence (AI) adoption is still in its early stages. As more businesses use AI systems and the technology continues to mature and change, improper use could expose a company to significant financial, operational, regulatory and reputational risks. ” Are foundation models trustworthy?
When thinking of artificial intelligence (AI) use cases, the question might be asked: What won’t AI be able to do? The easy answer is mostly manual labor, although the day might come when much of what is now manual labor will be accomplished by robotic devices controlled by AI. We’re all amazed by what AI can do.
Machine learning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. Such infrastructure should not only address these issues but also scale according to the demands of AI workloads, thereby enhancing business outcomes. Let’s delve into the database portfolio from IBM available on AWS.
By setting up automated policy enforcement and checks, you can achieve cost optimization across your machine learning (ML) environment. Technical tags – These provide metadata about resources. The AWS reserved prefix aws: tags provide additional metadata tracked by AWS. This helps track spending for cost allocation purposes.
If your company is in the early stage of its AI journey or has budget constraints, you may struggle to find a deployment system for your model. Building ML infrastructure and integrating ML models with the larger business are major bottlenecks to AI adoption [1,2,3]. Db2 Warehouse on cloud also supports these ML features.
The European Artificial Intelligence Act, while not yet law, is driving new levels of human oversight and regulatory compliance for artificial intelligence (AI) within the European Union. Similar to GDPR for privacy, the EU AI Act has potential to set the tone for upcoming AI regulations worldwide.
It is well known that Artificial Intelligence (AI) has progressed, moving past the era of experimentation to become business critical for many organizations. While the promise of AI isn’t guaranteed and may not come easy, adoption is no longer a choice. So what is stopping AI adoption today? It is an imperative.
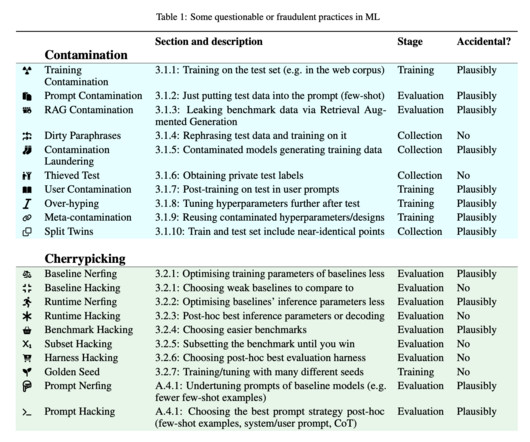
These methods have the potential to greatly exaggerate published results, deceiving the scientific community and the general public about the actual effectiveness of ML models. Due to the intricacy of ML research, which includes pre-training, post-training, and evaluation stages, there is much potential for QRPs. Check out the Paper.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
Last Updated on August 8, 2024 by Editorial Team Author(s): Gift Ojeabulu Originally published on Towards AI. Why VS Code might be better for many data scientists and ML engineers than Jupyter Notebook. Essential VS Code Extensions for Data Scientists and ML Engineers.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. The following diagram illustrates the end-to-end architecture, consisting of the metadata API layer, ingestion pipeline, embedding generation workflow, and frontend UI.
AI and Blockchain have emerged as two of the most groundbreaking technical innovations in recent times. Artificial Intelligence (AI) : Enables machines and computers to emulate human thinking and decision-making processes.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
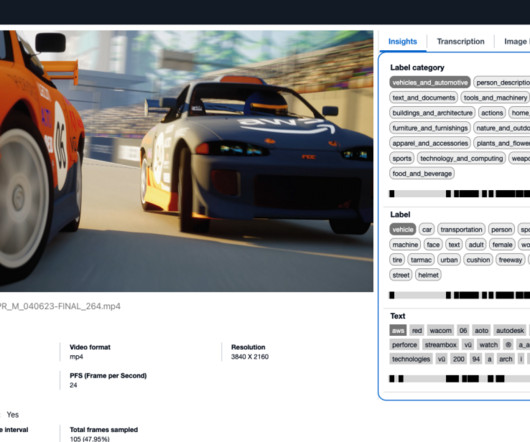
Generative artificial intelligence (AI) has unlocked fresh opportunities for these use cases. In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWS AI and generative AI services to provide a framework to streamline video extraction and evaluation processes.
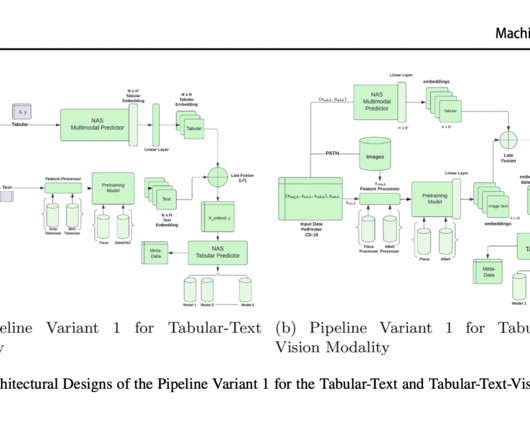
An improvement in AutoML for dealing with complicated data modalities, including tabular-text, text-vision, and vision-text-tabular configurations, the proposed method simplifies and guarantees the efficiency and adaptability of multimodal ML pipelines. The Sequential Model-Based Optimization (SMBO) approach uses it as a search space.
In the past decade, Artificial Intelligence (AI) and Machine Learning (ML) have seen tremendous progress. Modern AI and ML models can seamlessly and accurately recognize objects in images or video files. The SEER framework allows developers to train large & complex ML models on random data with no supervision, i.e
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Its AI courses provide valuable knowledge and hands-on experience, helping learners build and optimize AI models, understand advanced AI concepts, and apply AI solutions to real-world problems.
Today, we are excited to announce three launches that will help you enhance personalized customer experiences using Amazon Personalize and generative AI. Amazon Personalize is a fully managed machine learning (ML) service that makes it easy for developers to deliver personalized experiences to their users.
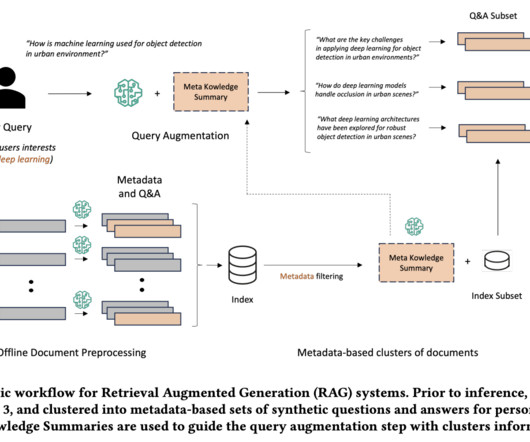
RAG has gained significant attention because it addresses the need for more precise, context-aware outputs in AI-driven systems. The key innovations in this methodology include generating metadata and synthetic Question and Answer (QA) pairs for each document and introducing the concept of a Meta Knowledge Summary (MK Summary).
It was in 2014 when ICML organized the first AutoML workshop that AutoML gained the attention of ML developers. ai, IBM Watson AI, Microsoft AzureML, and a lot more. Next, the LightAutoML inner datasets contain CV iterators and metadata that implement validation schemes for the datasets.
Building a deployment pipeline for generative artificial intelligence (AI) applications at scale is a formidable challenge because of the complexities and unique requirements of these systems. Generative AI models are constantly evolving, with new versions and updates released frequently.
Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. To maximize the value of their AI initiatives, organizations must maintain data integrity throughout its lifecycle.
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI.
Iambic Therapeutics is a drug discovery startup with a mission to create innovative AI-driven technologies to bring better medicines to cancer patients, faster. Our advanced generative and predictive artificial intelligence (AI) tools enable us to search the vast space of possible drug molecules faster and more effectively.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. In the context of Amazon Bedrock , observability and evaluation become even more crucial.
Organizations of all sizes and types are using generative AI to create products and solutions. In this post, we show you how to manage user access to enterprise documents in generative AI-powered tools according to the access you assign to each persona. If you don’t already have an AWS account, you can create one.
Can AI replace forensics analysts? More importantly, would AI-driven findings even hold up in court? Experts can check hard drives, metadata, data packets, network access logs or email exchanges to find, collect, and process information. Forensic analysts can use AI in several ways. What Is Digital Forensic Science?
The development of machine learning (ML) models for scientific applications has long been hindered by the lack of suitable datasets that capture the complexity and diversity of physical systems. The data is available with a PyTorch interface, allowing for seamless integration into existing ML pipelines.
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content