This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These breakthroughs have not only enhanced the capabilities of machines to understand and generate human language but have also redefined the landscape of numerous applications, from search engines to conversational AI. GPT Architecture Here's a more in-depth comparison of the T5, BERT, and GPT models across various dimensions: 1.
Hugging Face is an AI research lab and hub that has built a community of scholars, researchers, and enthusiasts. In a short span of time, Hugging Face has garnered a substantial presence in the AI space. Large language models or LLMs are AI systems that use transformers to understand and create human-like text.
This post explores how Lumi uses Amazon SageMaker AI to meet this goal, enhance their transaction processing and classification capabilities, and ultimately grow their business by providing faster processing of loan applications, more accurate credit decisions, and improved customer experience.
Artificial Intelligence (AI) is revolutionizing how discoveries are made. AI is creating a new scientific paradigm with the acceleration of processes like data analysis, computation, and idea generation. Experiments proceed iteratively, with results categorized as improvements, maintenance, or declines.
Author(s): MSVPJ Sathvik Originally published on Towards AI. This panel has designed the guidelines for annotating the wellness dimensions and categorized the posts into the six wellness dimensions based on the sensitive content of each post. What are wellness dimensions? Considering its structure, we have taken Halbert L.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis. RALMs’ language models are categorized into autoencoder, autoregressive, and encoder-decoder models.
In this article, we will be talking about how the collaboration between AI and blockchain gives birth to numerous privacy protection techniques, and their application in different verticals including de-identification, data encryption, k-anonymity, and multi-tier distributed ledger methods.
True to their name, generative AI models generate text, images, code , or other responses based on a user’s prompt. Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
That is Generative AI. Microsoft is already discontinuing its Cortana app this month to prioritize newer Generative AI innovations, like Bing Chat. billion R&D budget to generative AI, as indicated by CEO Tim Cook. To understand this, think of a sentence: “Unite AI Publish AI and Robotics news.”
With advancements in deep learning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. These AI agents, transcending chatbots and voice assistants, are shaping a new paradigm for both industries and our daily lives.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. In this post, we focus on the BERT extractive summarizer. It works by first embedding the sentences in the text using BERT.
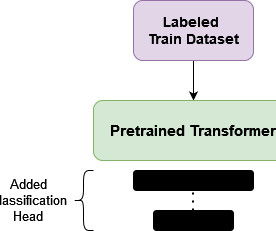
Author(s): Ehssan Originally published on Towards AI. In the case of BERT (Bidirectional Encoder Representations from Transformers), learning involves predicting randomly masked words (bidirectional) and sentence-order prediction. For concreteness, we will use BERT as the base model and set the number of classification labels to 4.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., Copywriting The most popular model for this task is GPT-3; however, there are open-source alternatives such as BLOOM (from BigScience) and Eleuther AI’s GPT-J.
Understanding these mechanisms in advanced AI systems is crucial for ensuring their safety, and fairness, and minimizing biases and errors, especially in critical contexts. Existing surveys detail a range of techniques utilized in Explainable AI analyses and their applications within NLP.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. The system’s error detection mechanism is designed to identify and categorize failures during execution promptly. Training these models, however, is challenging. Check out the Paper.
The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family. The persistence of smaller models challenges assumptions about the dominance of large-scale AI. These sources can be categorized into three types: textual documents (e.g.,
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
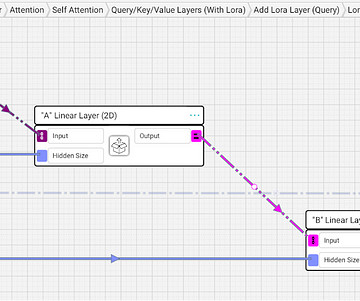
Last Updated on September 27, 2023 by Editorial Team Author(s): David Winer Originally published on Towards AI. Back when BERT and GPT2 were first revolutionizing natural language processing (NLP), there was really only one playbook for fine-tuning. Inside LoRA layer visualized implementation First, I’ll start with what is LoRA.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. With Amazon Bedrock, developers can experiment, evaluate, and deploy generative AI applications without worrying about infrastructure management.
Large language Models also intersect with Generative Ai, it can perform a variety of Natural Language Processing tasks, including generating and classifying text, question answering, and translating text from one language to another language, and Document summarization. RoBERTa (Robustly Optimized BERT Approach) — developed by Facebook AI.
M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. Fine-tune the sentence transformer M5_ASIN_SMALL_V20 Now we create a sentence transformer from a BERT-based model called M5_ASIN_SMALL_V2.0. str.split("|").str[0] All other code remains the same.
Author(s): MSVPJ Sathvik Originally published on Towards AI. Lastly, with the help of expert annotators, we were successful in categorizing the data based on the respective criteria for both escapism and PTSD. So, how did we work on the categorizing? were used to capture nuanced language patterns.
MusicLM is specifically trained on SoundStream, w2v-BERT, and MuLan pre-trained modules. This includes 78,366 categorized sound events across 44 categories and 39,187 non-categorized sound events. The post Get Ready for a Sound Revolution in AI: 2023 is the Year of Generative Sound Waves appeared first on MarkTechPost.
Researchers are actively seeking innovative solutions to overcome the constraints of current general-purpose AI models, which often need more precision in niche tasks, and domain-specific models, which are limited in their flexibility. In conclusion, the findings from this research suggest a paradigm shift in AI model development.
Generated with Bing and edited with Photoshop Predictive AI has been driving companies’ ROI for decades through advanced recommendation algorithms, risk assessment models, and fraud detection tools. However, the recent surge in generative AI has made it the new hot topic. a social media post or product description).
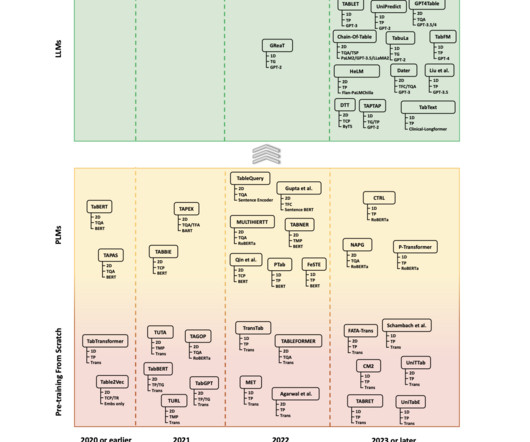
Against this backdrop, researchers began using PLMs like BERT, which required less data and provided better predictive performance. The methodology proposed by the research team categorizes tabular data into two major categories: 1D and 2D. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
In the general language domain, there are two main branches of pre-trained language models: BERT (and its variants) and GPT (and its variants). The first one, BERT (and its variants), has received the most attention in the biomedical domain; examples include BioBERT and PubMedBERT, while the second one has received less attention.
AWS ProServe solved this use case through a joint effort between the Generative AI Innovation Center (GAIIC) and the ProServe ML Delivery Team (MLDT). The AWS GAIIC is a group within AWS ProServe that pairs customers with experts to develop generative AI solutions for a wide range of business use cases using proof of concept (PoC) builds.
The transformative power of advanced summarization capabilities will only continue growing as more industries adopt artificial intelligence (AI) to harness overflowing information streams. This approach requires a deeper understanding of the text, because the AI needs to interpret the meaning and then express it in a new, concise form.
For instance, a BERT model with 86 million parameters can perform NLI tasks, while the smallest effective zero-shot generative LLMs require 7-8 billion parameters. This approach allows the use of smaller encoder language models like BERT for classification tasks, dramatically reducing computational requirements compared to generative LLMs.
The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. BERT is a pre-trained transformer-based deep learning model for natural language processing that achieved state-of-the-art results across a wide array of natural language processing tasks when this model was proposed.
The KGW Family modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary into a green list and a red list based on the preceding token. This method is particularly valuable when an advanced, AI-based analysis of the subtle effects of watermarking is required. So let’s get started.
Traditionally reliant on human expertise and manual research, the legal profession is at the cusp of a technological shift as Artificial Intelligence (AI) makes inroads. The integration of AI for legal research raises questions about the future direction of the legal profession and prompts a reevaluation of its core practices.
Methodology Based on Pre-Trained Language Models (PLMs): Text-to-SQL jobs were optimized using the semantic knowledge of pre-trained language models (PLMs) such as BERT and RoBERTa. To provide more precise SQL queries, schema-aware PLMs integrated knowledge of database structures.
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervised learning. Foundation models underpin generative AI capabilities, from text-generation to music creation to image generation. Github Copilot GitHub Copilot is an AI-powered code assistant.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! cats” component of Docs, for which we’ll be training a text categorization model to classify sentiment as “positive” or “negative.” You can also get data science training on-demand wherever you are with our Ai+ Training platform.
Complete training materials for FastText and Bert implementation accompany the dataset, with upcoming suggestions for data proportioning based on RegMix methodology. URL labeling utilizes GPT-4 to process the top million root URLs, categorizing them into Domain-of-Interest (DoI) and Domain-of-Non-Interest (DoNI) URLs.
Its categorical power is brittle. Predictive pipelines for gen AI begin with a function that accepts the text document to examine and inserts it into the prompt template, resulting in a complete prompt. The problem of accuracy Text-generating AIs are trained to understand language largely by filling in missing tokens.
Its categorical power is brittle. Why you should not deploy genAI for predictive into production Given the relative ease of building predictive pipelines using generative AI, it might be tempting to set one up for large-scale use. BERT for misinformation. The largest version of BERT contains 340 million parameters.
Its categorical power is brittle. The main challenges of deploying genAI for predictive into production Given the relative ease of building predictive pipelines using generative AI, it might be tempting to set one up for large-scale use. BERT for misinformation. The largest version of BERT contains 340 million parameters.
The SST2 dataset is a text classification dataset with two labels (0 and 1) and a column of text to categorize. Training – Take the shaped CSV file and run fine-tuning with BERT for text classification utilizing Transformers libraries. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content