This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Avi Perez, CTO of Pyramid Analytics, explained that his business intelligence software’s AI infrastructure was deliberately built to keep data away from the LLM , sharing only metadata that describes the problem and interfacing with the LLM as the best way for locally-hosted engines to run analysis.”There’s
Also, a lakehouse can introduce definitional metadata to ensure clarity and consistency, which enables more trustworthy, governed data. All of this supports the use of AI. And AI, both supervised and unsupervised machine learning, is often the best or sometimes only way to unlock these new big data insights at scale.
1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments. It empowers businesses to automate and consolidate multiple tools, applications and platforms while documenting the origin of datasets, models, associated metadata and pipelines.
With deep expertise in generative AI and enterprise solutions, Joo partners with global leaders like AWS, NVIDIA, IBM, and Meta AI to drive innovative AIstrategies. Joo (Joe) Moura is the Founder and CEO of CrewAI, the leading agent orchestration platform powering multi-agent automations at scale.
Watsonx.data is built on 3 core integrated components: multiple query engines, a catalog that keeps track of metadata, and storage and relational data sources which the query engines directly access. Later this year, it will leverage watsonx.ai foundation models to help users discover, augment, and enrich data with natural language.
The True Cost of Noncompliance Responsible AI requires governance Despite good intentions and evolving technologies, achieving responsible AI can be challenging. AI requires AI governance , not after the fact but baked into AIstrategy of your organization. So what is AI governance?
It really starts with understanding what you need – don’t go out and buy expensive GPUs just because you’re afraid you’ll miss out on the AI boat. I strongly believe that enterprise AIstrategies will fail in 2024 if organizations focus only on the models themselves and not on data.
Repository Information**: Not shown in the provided excerpt, but likely contains metadata about the repository. Specialist Solutions Architect focused on generative AIstrategy, applied AI solutions, and conducting research to help customers hyper-scale on AWS. About the authors Marco Punio is a Sr.
About the Authors Rupa Boddu is the Principal Tech Product Manager leading Generative AIstrategy and development for the AWS Sales and Marketing organization. She has successfully launched AI/ML applications across AWS and collaborates with executive teams of AWS customers to shape their AIstrategies.
Start by using the following code to download the PDF documents from the provided URLs and create a list of metadata for each downloaded document. !mkdir Specialist Solutions Architect focused on generative AIstrategy, applied AI solutions, and conducting research to help customers hyperscale on AWS. Marco Punio is a Sr.
This saves us the time it would otherwise take to memorize metadata and APIs. We’ll be working together to embed complex generative AIstrategies from Azure into DataRobot modeling strategies next – unlocking completely new use cases for the enterprise.
Similarity Search Similarity search is a potent Artificial Intelligence (AI) strategy that focuses on the meaning contained in the information rather than only employing keywords. User preferences, contextual data, and metadata are a few examples of these features.
With over 15 years of experience in architecting and building AI based products and platforms, he holds multiple patents and publications in AI and eCommerce. Marco Punio is a Solutions Architect focused on generative AIstrategy, applied AI solutions and conducting research to help customers hyperscale on AWS.
Broadcasters and telecom companies use the product to perform various video-related tasks, including scene recognition, anomaly detection, and enriching metadata. You can access all the features of this AI software free of cost for a limited period (up to 100 hours of processing).
io In the News OpenAI takes steps to boost AI-generated content transparency OpenAI is joining the Coalition for Content Provenance and Authenticity (C2PA) steering committee and will integrate the open standard’s metadata into its generative AI models to increase transparency around generated content. Powered by ai4.io
4 Best Practices for Developing a Strong Data Foundation Companies that invest in their data layer today are setting themselves up for long-term AI success in the future. Here are four best practices to help future-proof your data strategy: 1.
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. This extracted text is then available for further analysis and the creation of metadata, adding layout-based structure and meaning to the raw data.
Flexible data modeling – You can define custom collections and metadata schemas tailored to your specific use cases, allowing for flexible data modeling. Database schemas, table structures, and their associated metadata are processed through an embeddings model hosted on SageMaker JumpStart to generate embeddings.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




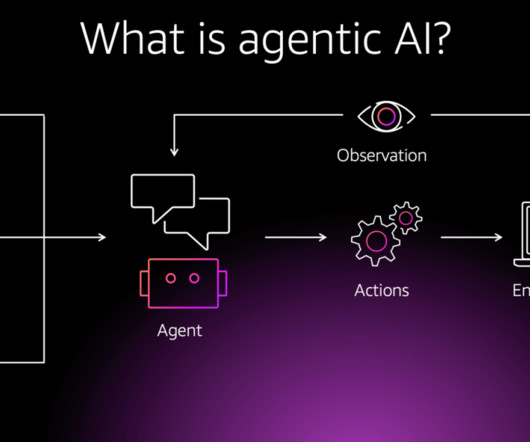



















Let's personalize your content