This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NaturalLanguageProcessing (NLP) is a rapidly growing field that deals with the interaction between computers and human language. To help you on your journey to mastering NLP, we’ve curated a list of 20 GitHub repositories that offer valuable resources, code examples, and pre-trained models.
Introduction Transformers have revolutionized various domains of machine learning, notably in naturallanguageprocessing (NLP) and computer vision. Their ability to capture long-range dependencies and handle sequential data effectively has made them a staple in every AIresearcher and practitioner’s toolbox.
Introduction In NaturalLanguageProcessing (NLP), developing Large Language Models (LLMs) has proven to be a transformative and revolutionary endeavor. These models, equipped with massive parameters and trained on extensive datasets, have demonstrated unprecedented proficiency across many NLP tasks.
Knowledge-intensive NaturalLanguageProcessing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. The primary challenge in knowledge-intensive NLP tasks is that large pre-trained language models need help accessing and manipulating knowledge precisely.
A model’s capacity to generalize or effectively apply its learned knowledge to new contexts is essential to the ongoing success of NaturalLanguageProcessing (NLP). To address that, a group of researchers from Meta has proposed a thorough taxonomy to describe and comprehend NLP generalization research.
NaturalLanguageProcessing (NLP) is useful in many fields, bringing about transformative communication, information processing, and decision-making changes. In conclusion, the study is a significant step for effective sarcasm detection in NLP. The post Can AI Really Understand Sarcasm?
This development suggests a future where AI can more closely mimic human-like learning and communication, opening doors to applications that require such dynamic interactivity and adaptability. NLP enables machines to understand, interpret, and respond to human language in a meaningful way.
In the ever-evolving field of NaturalLanguageProcessing (NLP), the development of machine translation and language models has been primarily driven by the availability of vast training datasets in languages like English. What sets this dataset apart is the rigorous auditing process it underwent.
An early hint of today’s naturallanguageprocessing (NLP), Shoebox could calculate a series of numbers and mathematical commands spoken to it, creating a framework used by the smart speakers and automated customer service agents popular today.
Powered by clkmg.com In the News Deepset nabs $30M to speed up naturallanguageprocessing projects Deepset GmbH today announced that it has raised $30 million to enhance its open-source Haystack framework, which helps developers build naturallanguageprocessing applications.
In the ever-evolving landscape of NaturalLanguageProcessing (NLP) and Artificial Intelligence (AI), Large Language Models (LLMs) have emerged as powerful tools, demonstrating remarkable capabilities in various NLP tasks. If you like our work, you will love our newsletter.
Fortunately, a team of researchers in Africa is striving to bridge this digital divide. Their recent study in the journal Patterns outlines strategies to develop AI tools tailored to African languages. Kathleen Siminyu, an AIresearcher at the Masakhane Research Foundation, emphasizes the importance of this endeavor.
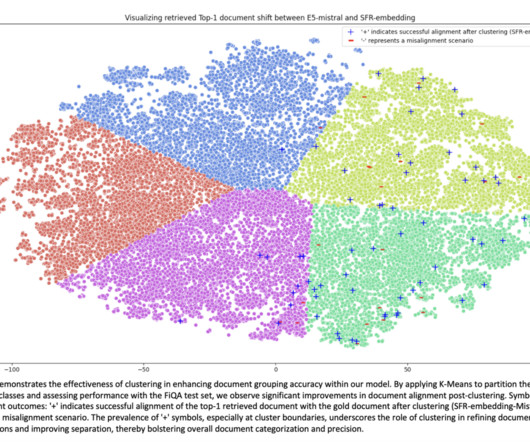
Salesforce AIResearchers introduced the SFR-Embedding-Mistral model to address the challenge of improving text-embedding models for various naturallanguageprocessing (NLP) tasks, including retrieval, clustering, classification, and semantic textual similarity.
nature.com Adoption and impacts of generative AI : Theoretical underpinnings and research agenda Large language models (LLMs) have received considerable interest in the field of naturallanguageprocessing (NLP) owing to their remarkable ability to generate clear, consistent, and contextually relevant materials.
When it comes to downstream naturallanguageprocessing (NLP) tasks, large language models (LLMs) have proven to be exceptionally effective. Their text comprehension and generation abilities make them extremely flexible for use in a wide range of NLP applications.
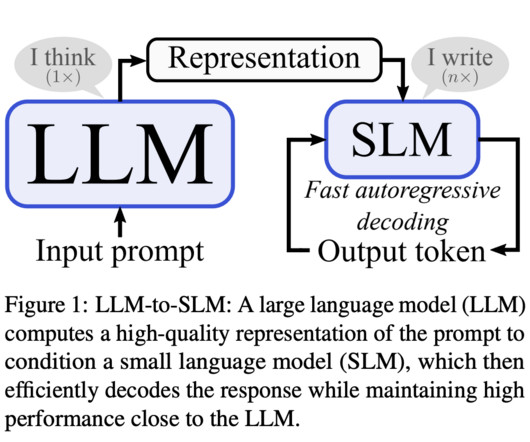
Central to NaturalLanguageProcessing (NLP) advancements are large language models (LLMs), which have set new benchmarks for what machines can achieve in understanding and generating human language. One of the primary challenges in NLP is the computational demand for autoregressive decoding in LLMs.
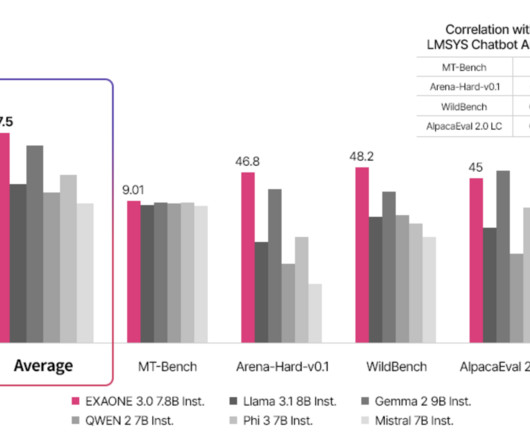
LG AIResearch has recently announced the release of EXAONE 3.0. The release as an open-source large language model is unique to the current version with great results and 7.8B LG AIResearch is driving a new development direction, marking it competitive with the latest technology trends. parameters.
The well-known Large Language Models (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in NaturalLanguageProcessing (NLP) and NaturalLanguage Generation (NLG). If you like our work, you will love our newsletter.
Transformer design that has recently become popular has taken over as the standard method for NaturalLanguageProcessing (NLP) activities, particularly Machine Translation (MT). This not only lessens the model’s computational load but also improves its effectiveness and applicability for diverse NLP applications.
In the rapidly evolving field of artificial intelligence, naturallanguageprocessing has become a focal point for researchers and developers alike. The Most Important Large Language Models (LLMs) in 2023 1. This model marked a new era in NLP with pre-training of language models becoming a new standard.
No legacy process is safe. And this is particularly true for accounts payable (AP) programs, where AI, coupled with advancements in deep learning, computer vision and naturallanguageprocessing (NLP), is helping drive increased efficiency, accuracy and cost savings for businesses.
economist.com Apple’s next nebulous idea: smart home robots Apple’s next big project could be harder than building a car — making a smart AI robot that can figure out how to navigate my house. In the real world, it is a prediction—and a welcome one.
In the consumer technology sector, AI began to gain prominence with features like voice recognition and automated tasks. Over the past decade, advancements in machine learning, NaturalLanguageProcessing (NLP), and neural networks have transformed the field. Notable acquisitions include companies like Xnor.a
LLMs are deep neural networks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in NaturalLanguageProcessing (NLP).
Medical data extraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical naturallanguageprocessing (NLP). Even with its importance, particular difficulties arise while developing methodologies for clinical NLP.
The currently existing techniques for instruction tuning frequently rely on NaturalLanguageProcessing (NLP) datasets, which are scarce, or self-instruct approaches that produce artificial datasets having difficulty with diversity. Don’t Forget to join our Telegram Channel You may also like our FREE AI Courses….
Large Language Models (LLMs), the latest innovation of Artificial Intelligence (AI), use deep learning techniques to produce human-like text and perform various NaturalLanguageProcessing (NLP) and NaturalLanguage Generation (NLG) tasks. If you like our work, you will love our newsletter.
Since OpenAI unveiled ChatGPT in late 2022, the role of foundational large language models (LLMs) has become increasingly prominent in artificial intelligence (AI), particularly in naturallanguageprocessing (NLP).
Naturallanguageprocessing (NLP) in artificial intelligence focuses on enabling machines to understand and generate human language. This field encompasses a variety of tasks, including language translation, sentiment analysis, and text summarization. Also, don’t forget to follow us on Twitter.
Researchers continually strive to build models that can understand, reason, and generate text like humans in the rapidly evolving field of naturallanguageprocessing. These models must grapple with complex linguistic nuances, bridge language gaps, and adapt to diverse tasks.
A lot goes into NLP. Languages, dialects, unstructured data, and unique business needs all contribute to requiring constant innovation from the field. Going beyond NLP platforms and skills alone, having expertise in novel processes, and staying afoot in the latest research are becoming pivotal for effective NLP implementation.
The quest to refine AI’s understanding of extensive textual data has recently been advanced due to two recent papers by CDS PhD student Jason Phang , who is the first author of two recent NLP papers that secured “best paper” accolades at ICML 2023 and EMNLP 2023. By Stephen Thomas
Summary: Amazon’s Ultracluster is a transformative AI supercomputer, driving advancements in Machine Learning, NLP, and robotics. Its high-performance architecture accelerates AIresearch, benefiting healthcare, finance, and entertainment industries.
Text embeddings (TEs) are low-dimensional vector representations of texts of different sizes, which are important for many naturallanguageprocessing (NLP) tasks. Pre-trained language models, like BERT and GPT, have shown great success in various NLP tasks.
[Apply now] 1west.com In The News Almost 60% of people want regulation of AI in UK workplaces, survey finds Almost 60% of people would like to see the UK government regulate the use of generative AI technologies such as ChatGPT in the workplace to help safeguard jobs, according to a survey. siliconangle.com Can AI improve cancer care?
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. All credit for this research goes to the researchers of this project.
The performance of large language models (LLMs) has been impressive across many different naturallanguageprocessing (NLP) applications. Don’t forget to join our 25k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
Large language models, such as PaLM, Chinchilla, and ChatGPT, have opened up new possibilities in performing naturallanguageprocessing (NLP) tasks from reading instructive cues.
Large language models (LLMs) have made tremendous strides in the last several months, crushing state-of-the-art benchmarks in many different areas. There has been a meteoric rise in people using and researching Large Language Models (LLMs), particularly in NaturalLanguageProcessing (NLP).
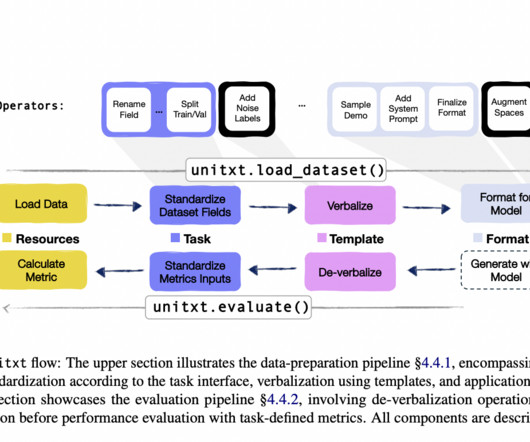
Though it has always played an essential part in naturallanguageprocessing, textual data processing now sees new uses in the field. Multiple teams working on different naturallanguageprocessing (NLP) activities have already used Unitxt as a core utility for LLMs in IBM.
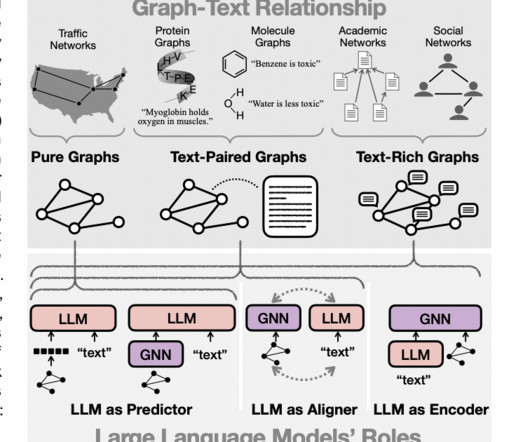
In NLP, dialogue systems generate highly generic responses such as “I don’t know” even for simple questions. Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right). Is commonsense knowledge already captured by pre-trained language models?
Top 10 AIResearch Papers 2023 1. Sparks of AGI by Microsoft Summary In this research paper, a team from Microsoft Research analyzes an early version of OpenAI’s GPT-4, which was still under active development at the time. Sign up for more AIresearch updates. Enjoy this article?
Recently introduced Large Language Models (LLMs) have taken the Artificial Intelligence (AI) community by storm. These models have been able to successfully imitate human beings by using super-good NaturalLanguageProcessing (NLP), NaturalLanguage Generation (NLG) and NaturalLanguage Understanding (NLU).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content