This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NaturalLanguageProcessing (NLP) is a rapidly growing field that deals with the interaction between computers and human language. Transformers is a state-of-the-art library developed by Hugging Face that provides pre-trained models and tools for a wide range of naturallanguageprocessing (NLP) tasks.
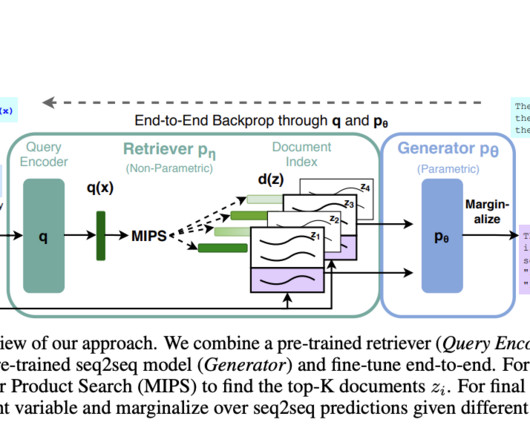
Knowledge-intensive NaturalLanguageProcessing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. Researchers from Facebook AIResearch, University College London, and New York University introduced Retrieval-Augmented Generation (RAG) models to address these limitations.
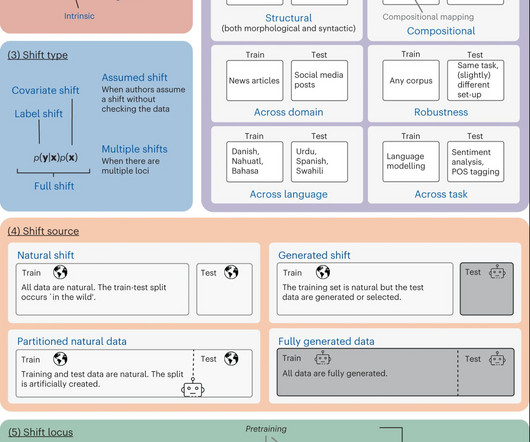
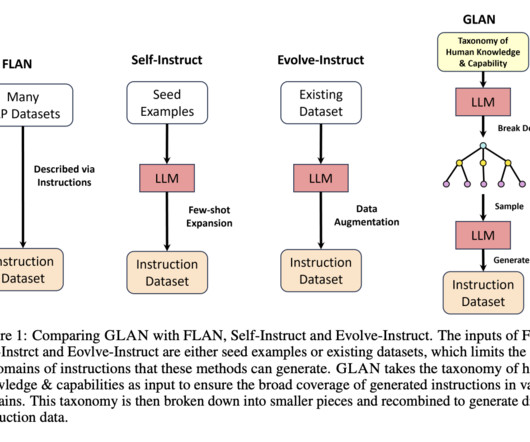
A model’s capacity to generalize or effectively apply its learned knowledge to new contexts is essential to the ongoing success of NaturalLanguageProcessing (NLP). Having the taxonomy in place makes it easier to get good generalizations, which further fosters the growth of NaturalLanguageProcessing.
The machine learning community faces a significant challenge in audio and music applications: the lack of a diverse, open, and large-scale dataset that researchers can freely access for developing foundation models. It provides researchers worldwide with access to a comprehensive dataset, free from licensing fees or restricted access.
NaturalLanguageProcessing (NLP) is useful in many fields, bringing about transformative communication, information processing, and decision-making changes. All credit for this research goes to the researchers of this project. The post Can AI Really Understand Sarcasm?
In particular, the instances of irreproducible findings, such as in a review of 62 studies diagnosing COVID-19 with AI , emphasize the necessity to reevaluate practices and highlight the significance of transparency. Multiple factors contribute to the reproducibility crisis in AIresearch.
graduates have each expanded the frontiers of AIresearch and are now ready to embark on new adventures in academia, industry, and beyond. These fantastic individuals bring with them a wealth of knowledge, fresh ideas, and a drive to continue contributing to the advancement of AI.
The rise of large language models (LLMs) has transformed naturallanguageprocessing, but training these models comes with significant challenges. All credit for this research goes to the researchers of this project. Dont Forget to join our 60k+ ML SubReddit. For instance, Llama-3.1-405B
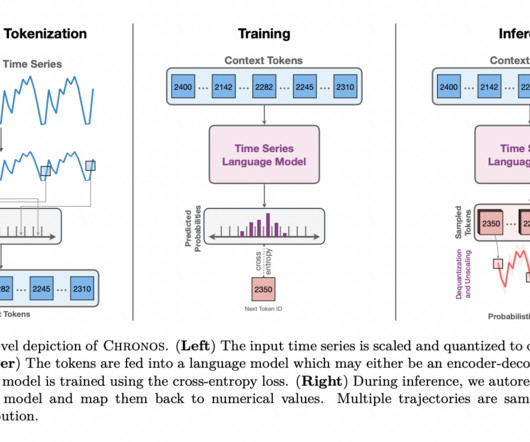
This process involves scaling and quantizing the data into discrete bins, similar to how words form a vocabulary in language models. This tokenization allows Chronos to use the same architectures as naturallanguageprocessing tasks, such as the T5 family of models, to forecast future data points in a time series.
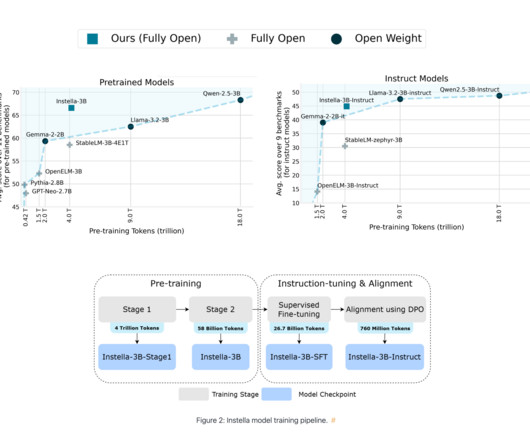
By releasing Instella openly, AMD provides the community with the opportunity to study, refine, and adapt the model for a range of applicationsfrom academic research to practical, everyday solutions. All credit for this research goes to the researchers of this project.
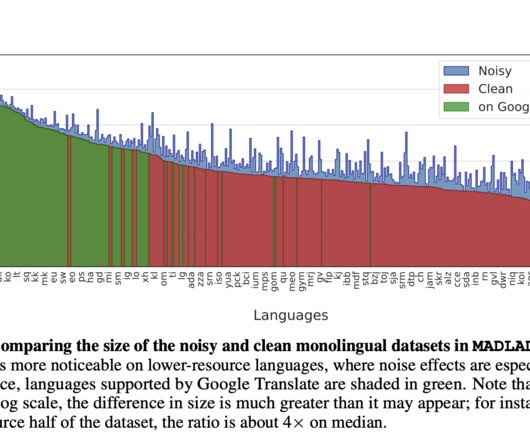
In the ever-evolving field of NaturalLanguageProcessing (NLP), the development of machine translation and language models has been primarily driven by the availability of vast training datasets in languages like English. All Credit For This Research Goes To the Researchers on This Project.
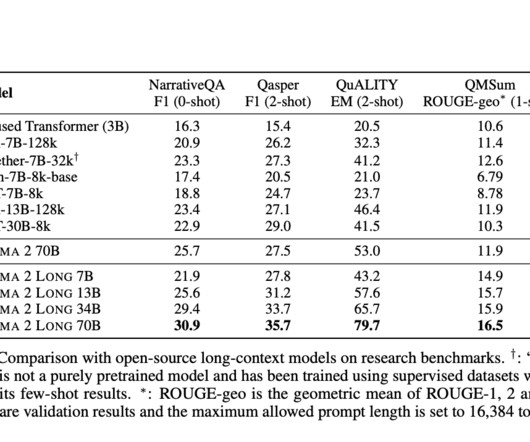
The emergence of Large Language Models (LLMs) in naturallanguageprocessing represents a groundbreaking development. Ultimately, the team hopes to empower researchers and developers to harness the potential of long-context LLMs for a wide array of applications, ushering in a new era of naturallanguageprocessing.
The well-known Large Language Models (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in NaturalLanguageProcessing (NLP) and NaturalLanguage Generation (NLG). All credit for this research goes to the researchers of this project.
Machine learning (ML) is a powerful technology that can solve complex problems and deliver customer value. However, ML models are challenging to develop and deploy. This is why Machine Learning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses.
Large Language Models (LLMs) have advanced significantly in naturallanguageprocessing, yet reasoning remains a persistent challenge. DeepSeek AIResearch presents CODEI/O , an approach that converts code-based reasoning into naturallanguage. Check out the Paper and GitHub Page.
In the ever-evolving landscape of NaturalLanguageProcessing (NLP) and Artificial Intelligence (AI), Large Language Models (LLMs) have emerged as powerful tools, demonstrating remarkable capabilities in various NLP tasks. All Credit For This Research Goes To the Researchers on This Project.
Central to NaturalLanguageProcessing (NLP) advancements are large language models (LLMs), which have set new benchmarks for what machines can achieve in understanding and generating human language. Join our 38k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup.
theguardian.com Sarah Silverman sues OpenAI and Meta claiming AI training infringed copyright The US comedian and author Sarah Silverman is suing the ChatGPT developer OpenAI and Mark Zuckerberg’s Meta for copyright infringement over claims that their artificial intelligence models were trained on her work without permission. AlphaGO was.
artificialintelligence-news.com Google’s new AI hub in Paris proves that Google feels insecure about AI This morning, Google’s CEO Sundar Pichai inaugurated a new hub in Paris dedicated to AI. ucf.edu Generative AI and Generative Conversations: Contrasting Futures for Organizational Change?
By reimagining the architecture of these models and integrating innovative techniques for efficient parameter use, the research team has achieved remarkable performance gains and broadened the horizon for the deployment of LLMs. Join our 38k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup.
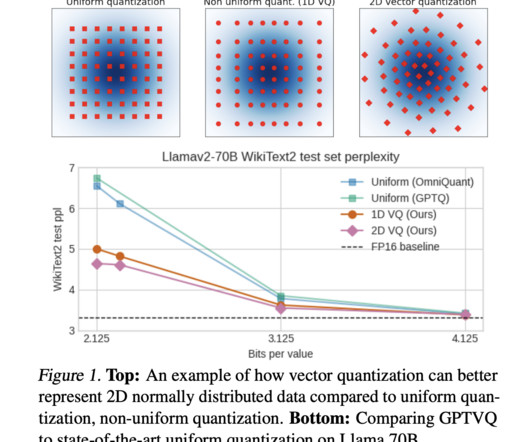
Efficiency of Large Language Models (LLMs) is a focal point for researchers in AI. A groundbreaking study by Qualcomm AIResearch introduces a method known as GPTVQ, which leverages vector quantization (VQ) to enhance the size-accuracy trade-off in neural network quantization significantly.
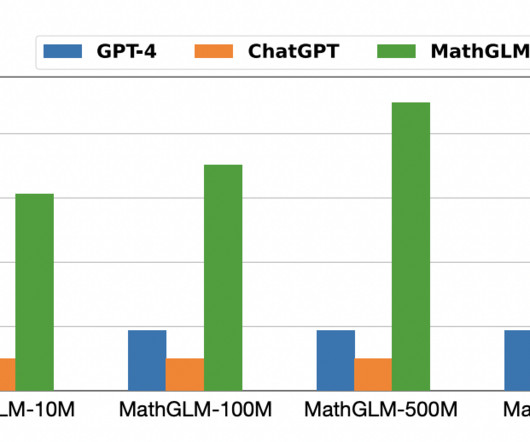
When it comes to downstream naturallanguageprocessing (NLP) tasks, large language models (LLMs) have proven to be exceptionally effective. The post Can Large Language Models Really Do Math? Their text comprehension and generation abilities make them extremely flexible for use in a wide range of NLP applications.
Large language models (LLMs) such as ChatGPT and Llama have garnered substantial attention due to their exceptional naturallanguageprocessing capabilities, enabling various applications ranging from text generation to code completion. All Credit For This Research Goes To the Researchers on This Project.
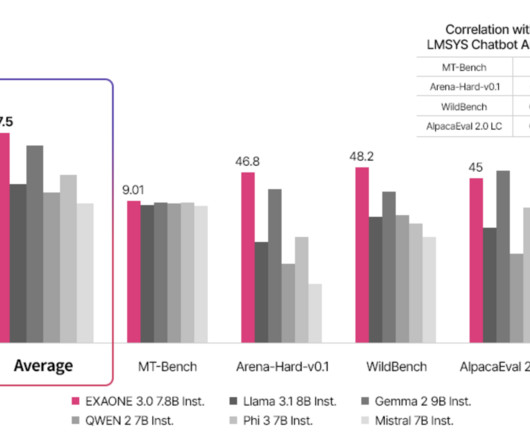
LG AIResearch has recently announced the release of EXAONE 3.0. The release as an open-source large language model is unique to the current version with great results and 7.8B LG AIResearch is driving a new development direction, marking it competitive with the latest technology trends. parameters. Released: A 7.8B
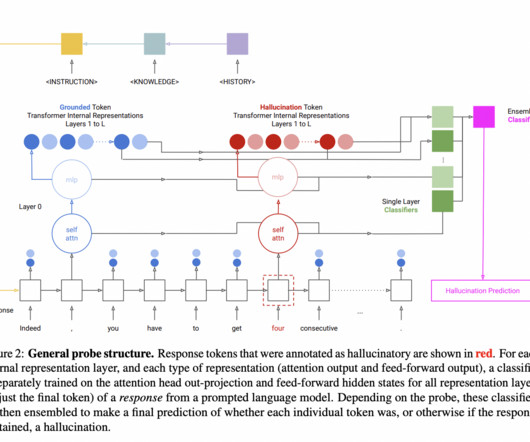
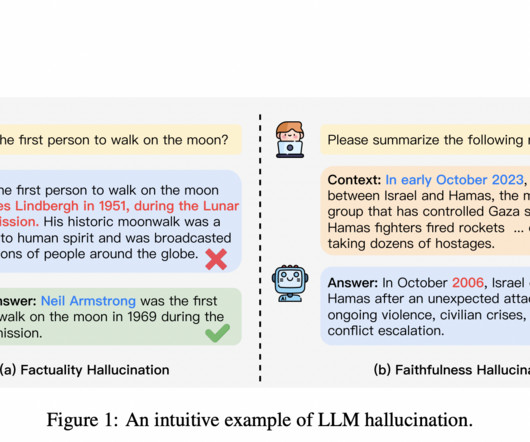
Large Language Models (LLMs), the latest innovation of Artificial Intelligence (AI), use deep learning techniques to produce human-like text and perform various NaturalLanguageProcessing (NLP) and NaturalLanguage Generation (NLG) tasks. The post Do Language Models Know When They Are Hallucinating?
The currently existing techniques for instruction tuning frequently rely on NaturalLanguageProcessing (NLP) datasets, which are scarce, or self-instruct approaches that produce artificial datasets having difficulty with diversity. Join our 38k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup.
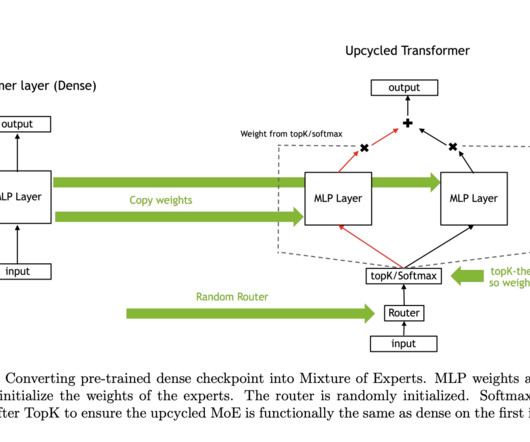
Mixture of Experts (MoE) models are becoming critical in advancing AI, particularly in naturallanguageprocessing. MoE architectures differ from traditional dense models by selectively activating subsets of specialized expert networks for each input. If you like our work, you will love our newsletter.
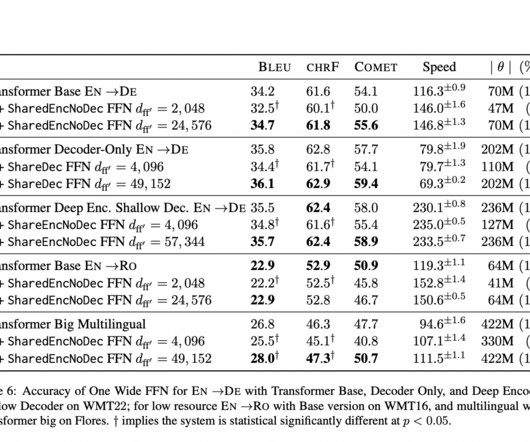
Transformer design that has recently become popular has taken over as the standard method for NaturalLanguageProcessing (NLP) activities, particularly Machine Translation (MT). All Credit For This Research Goes To the Researchers on This Project. If you like our work, you will love our newsletter.
Naturallanguageprocessing (NLP) in artificial intelligence focuses on enabling machines to understand and generate human language. This field encompasses a variety of tasks, including language translation, sentiment analysis, and text summarization. Also, don’t forget to follow us on Twitter.
Large language models have recently brought about a paradigm change in naturallanguageprocessing, leading to previously unheard-of advancements in language creation, comprehension, and reasoning. All credit for this research goes to the researchers of this project.
Task-agnostic model pre-training is now the norm in NaturalLanguageProcessing, driven by the recent revolution in large language models (LLMs) like ChatGPT. These models showcase proficiency in tackling intricate reasoning tasks, adhering to instructions, and serving as the backbone for widely used AI assistants.
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1. Focus on AIResearch and Development** . . . .
These findings highlight the potential for continued advancements in naturallanguageprocessing and its application to problem-solving. Future research directions include evaluating the MCMC-EM fine-tuning technique on diverse tasks and datasets to assess its generalizability.
The performance of large language models (LLMs) has been impressive across many different naturallanguageprocessing (NLP) applications. Don’t forget to join our 25k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
Naturallanguageprocessing is advancing rapidly, focusing on optimizing large language models (LLMs) for specific tasks. These models, often containing billions of parameters, pose a significant challenge in customization. Also, don’t forget to follow us on Twitter. Join our Telegram Channel and LinkedIn Gr oup.
Though it has always played an essential part in naturallanguageprocessing, textual data processing now sees new uses in the field. Multiple teams working on different naturallanguageprocessing (NLP) activities have already used Unitxt as a core utility for LLMs in IBM.
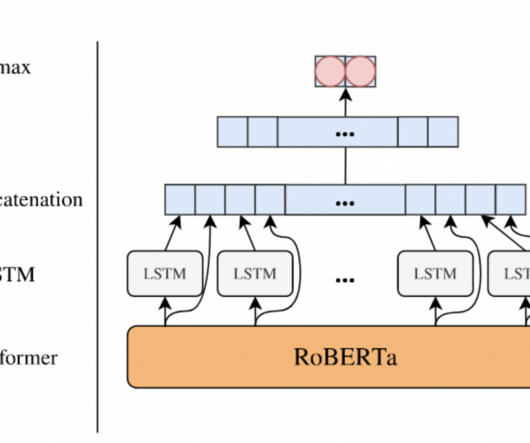
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. All credit for this research goes to the researchers of this project. Check out the Paper and Model on Hugging Face.
Top 10 AIResearch Papers 2023 1. Sparks of AGI by Microsoft Summary In this research paper, a team from Microsoft Research analyzes an early version of OpenAI’s GPT-4, which was still under active development at the time. Sign up for more AIresearch updates. Enjoy this article?
Generative models have emerged as transformative tools across various domains, including computer vision and naturallanguageprocessing, by learning data distributions and generating samples from them. Among these models, Diffusion Models (DMs) have garnered attention for their ability to produce high-quality images.
Artificial intelligence’s ascent of large language models (LLMs) has redefined naturallanguageprocessing. Quantization, the process of reducing model weights and activations to lower bit precision, is crucial for deploying models on resource-constrained devices.
In the consumer technology sector, AI began to gain prominence with features like voice recognition and automated tasks. Over the past decade, advancements in machine learning, NaturalLanguageProcessing (NLP), and neural networks have transformed the field.
Researchers continually strive to build models that can understand, reason, and generate text like humans in the rapidly evolving field of naturallanguageprocessing. These models must grapple with complex linguistic nuances, bridge language gaps, and adapt to diverse tasks. Check out the Project and Github.
The demand for powerful and versatile language models has become more pressing in naturallanguageprocessing and artificial intelligence. However, building language models that can excel in various language tasks remains a complex challenge. trillion tokens. Check out the Reference Article and Project.
Large language models (LLMs) have become crucial in naturallanguageprocessing, particularly for solving complex reasoning tasks. However, while LLMs can process and generate responses based on vast amounts of data, improving their reasoning capabilities is an ongoing challenge.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content