This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
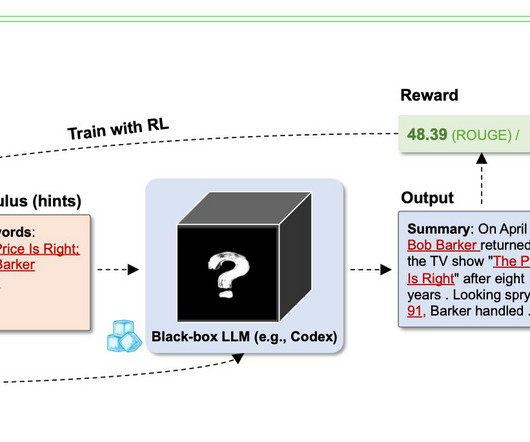
In this tutorial, we will build an efficient Legal AI CHatbot using open-source tools. It provides a step-by-step guide to creating a chatbot using bigscience/T0pp LLM , Hugging Face Transformers, and PyTorch. join(tokens) sample_text = "The contract is valid for 5 years, terminating on December 31, 2025."
Researchers from the University College London, University of WisconsinMadison, University of Oxford, Meta, and other institutes have introduced a new framework and benchmark for evaluating and developing LLM agents in AIresearch. It comprises four key components: Agents, Environment, Datasets, and Tasks. Pro, Claude-3.5-Sonnet,
Addressing this challenge requires innovative approaches to training and optimizing multilingual LLMs to deliver consistent performance across languages with varying resource availability. A critical challenge in multilingual NLP is the uneven distribution of linguistic resources. while Babel-83B set a new benchmark at 73.2.
LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). However, LLMs are also very different from other models.
Although NLP models have demonstrated extraordinary strengths, they have challenges. Researchers from Microsoft describe the Collaborative Development of NLP Models (CoDev) in this study. The LLM is then directed to provide instances where the local and global models conflict.
DeepSeek-R1 is an advanced LLM developed by the AI startup DeepSeek. Access to Hugging Face Hub You must have access to Hugging Face Hubs deepseek-ai/DeepSeek-R1-Distill-Llama-8B model weights from your environment. Access to code The code used in this post is available in the following GitHub repo.
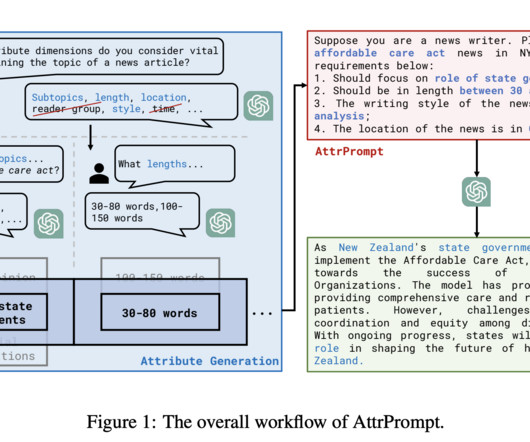
The performance of large language models (LLMs) has been impressive across many different natural language processing (NLP) applications. In recent studies, LLMs have been proposed as task-specific training data generators to reduce the necessity of task-specific data and annotations, especially for text classification.
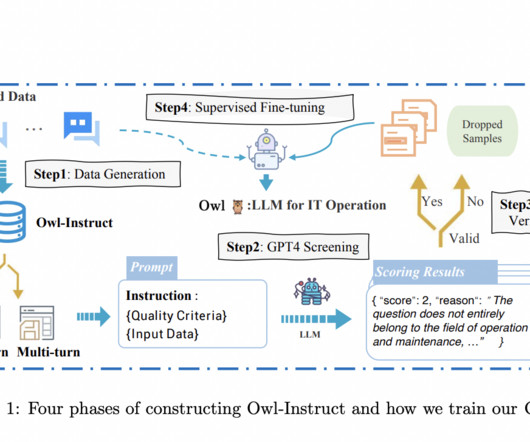
In the ever-evolving landscape of Natural Language Processing (NLP) and Artificial Intelligence (AI), Large Language Models (LLMs) have emerged as powerful tools, demonstrating remarkable capabilities in various NLP tasks. Within the field of IT, the importance of NLP and LLM technologies is on the rise.
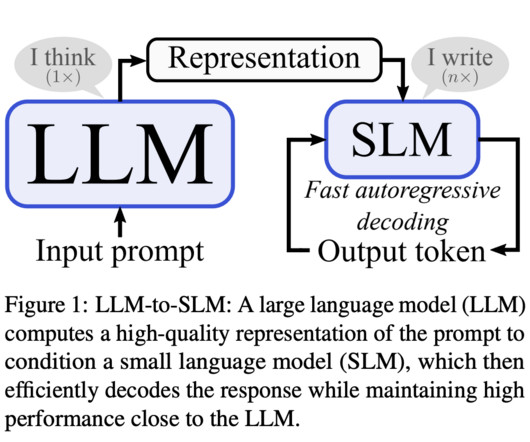
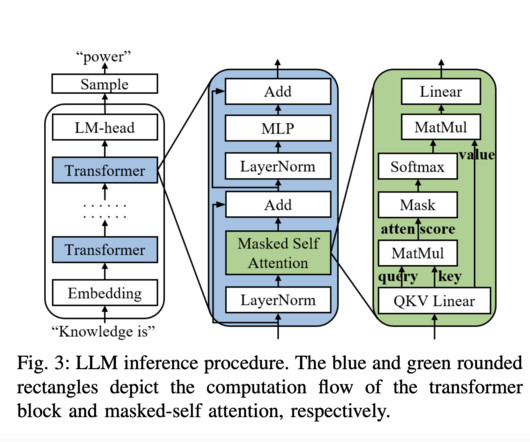
Central to Natural Language Processing (NLP) advancements are large language models (LLMs), which have set new benchmarks for what machines can achieve in understanding and generating human language. One of the primary challenges in NLP is the computational demand for autoregressive decoding in LLMs.
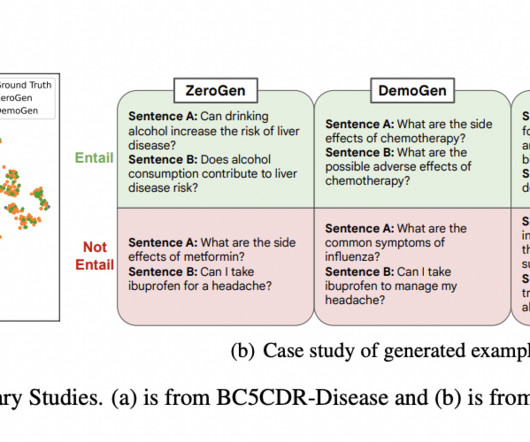
Medical data extraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical natural language processing (NLP). Even with its importance, particular difficulties arise while developing methodologies for clinical NLP. If you like our work, you will love our newsletter.
The shift across John Snow Labs’ product suite has resulted in several notable company milestones over the past year including: 82 million downloads of the open-source Spark NLP library. The no-code NLP Lab platform has experienced 5x growth by teams training, tuning, and publishing AI models.
Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. at Google, and “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” by Patrick Lewis, et al., Convert an incoming prompt to a graph query, then use the result set to select chunks for the LLM.
The Microsoft AI London outpost will focus on advancing state-of-the-art language models, supporting infrastructure, and tooling for foundation models. techcrunch.com Applied use cases Can AI Find Its Way Into Accounts Payable? No legacy process is safe.
Lately, Large language models (LLMs) are excelling in NLP and multimodal tasks but are facing two significant challenges: high computational costs and difficulties in conducting fair evaluations. These costs limit LLM development to a few major players, restricting research and applications.
Large Language Models (LLMs) have driven remarkable advancements across various Natural Language Processing (NLP) tasks. The progression in this field continues to transform how machines comprehend and process language, opening new avenues for research and development. on the AQuA dataset compared to the Self-Consistency method.
It is a General AI Assistant that focuses on real-world questions, avoiding LLM evaluation pitfalls. With human-crafted questions that reflect AI assistant use cases, GAIA ensures practicality. By targeting open-ended generation in NLP, GAIA aims to redefine evaluation benchmarks and advance the next generation of AI systems.
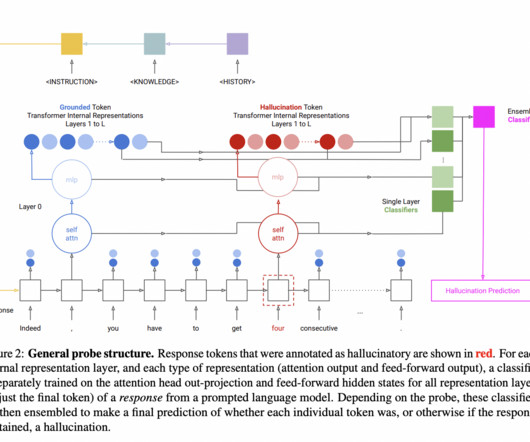
Natural language processing (NLP) has seen a paradigm shift in recent years, with the advent of Large Language Models (LLMs) that outperform formerly relatively tiny Language Models (LMs) like GPT-2 and T5 Raffel et al. on a variety of NLP tasks. Figure 1 depicts a sample of the summarising job.
Particularly after using reinforcement learning with human input, the intrinsic confidence score from the generative LLMs is sometimes unavailable or not effectively calibrated with regard to the intended aim. Heuristic techniques are costly to compute and are subject to bias from the LLM itself, such as sampling an ensemble of LLM answers.
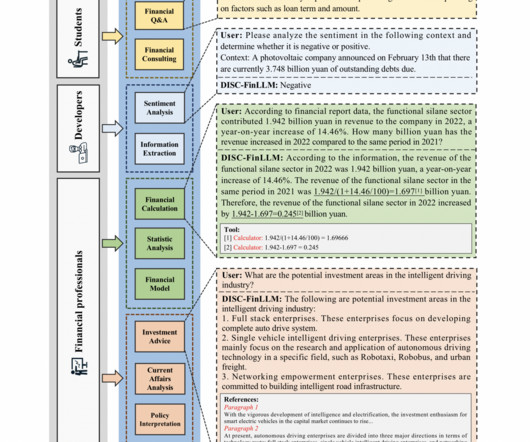
These Natural Language Processing (NLP) based models handle large and complicated datasets, which causes them to face a unique challenge in the finance industry. They are drawn from both self-constructed and available NLP datasets. The researchers have conducted multiple assessment benchmarks for evaluating DISC-FinLLM’s.
Generative Large Language Models (LLMs) are well known for their remarkable performance in a variety of tasks, including complex Natural Language Processing (NLP), creative writing, question answering, and code generation. Two current strategies to deal with these memory problems are offloading and model compression.
Transformer architectures have revolutionized Natural Language Processing (NLP), enabling significant language understanding and generation progress. However, the efficiency of LLMs in real-world deployment remains a challenge due to their substantial resource demands, particularly in tasks requiring sequential token generation.
Unlike earlier methods, it aligns task-specific requirements with a systematic optimization process, offering an efficient and scalable solution for diverse NLP applications. During the generation phase, the system uses LLMs to create multiple variations of a base prompt by applying cognitive heuristics.
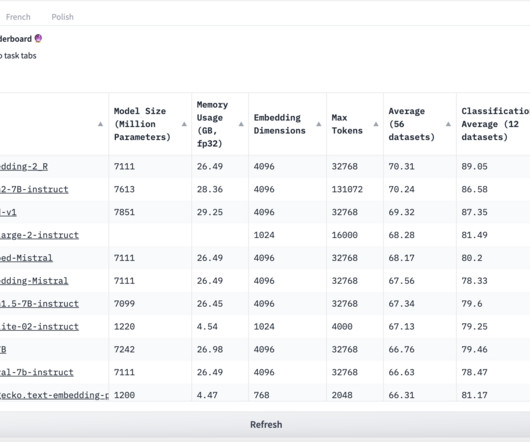
Text embeddings (TEs) are low-dimensional vector representations of texts of different sizes, which are important for many natural language processing (NLP) tasks. Pre-trained language models, like BERT and GPT, have shown great success in various NLP tasks. 7B-instruct model but with the updated Qwen2-7B base model. 7B-instruct model.
Transformer-based generative Large Language Models (LLMs) have shown considerable strength in a broad range of Natural Language Processing (NLP) tasks. For this, top AI firms like OpenAI, Google, and Baidu offer a language model-as-a-service (LMaaS) by granting access to their LLMs through APIs.
Large language models (LLMs) have made tremendous strides in the last several months, crushing state-of-the-art benchmarks in many different areas. There has been a meteoric rise in people using and researching Large Language Models (LLMs), particularly in Natural Language Processing (NLP). Check out the Paper.
Effective methods allowing for better control, or steerability , of large-scale AI systems are currently in extremely high demand in the world of AIresearch. But, how to determine how much data one needs to train an LLM? RLHF is perhaps the most popular of the current methods. Et voilà !
Large Language Models (LLMs), the latest innovation of Artificial Intelligence (AI), use deep learning techniques to produce human-like text and perform various Natural Language Processing (NLP) and Natural Language Generation (NLG) tasks. If you like our work, you will love our newsletter.
Setting the Stage: Why Augmentation Matters Imagine youre chatting with an LLM about complex topics like medical research or historical events. As we continue to push the boundaries of AI, hybrid models combining the best of CAG and RAG may well become the standard, offering unparalleled efficiency and accuracy.
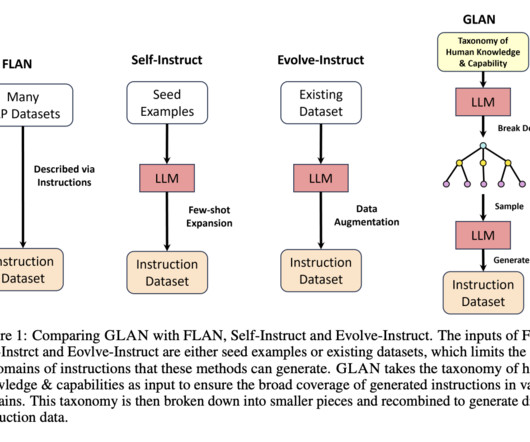
Instruction tuning comes as a solution, which includes fine-tuning LLMs on instructions matched with replies that humans like. The input, a taxonomy, has been created with minimal human effort through LLM prompting and verification. Don’t Forget to join our Telegram Channel You may also like our FREE AI Courses….
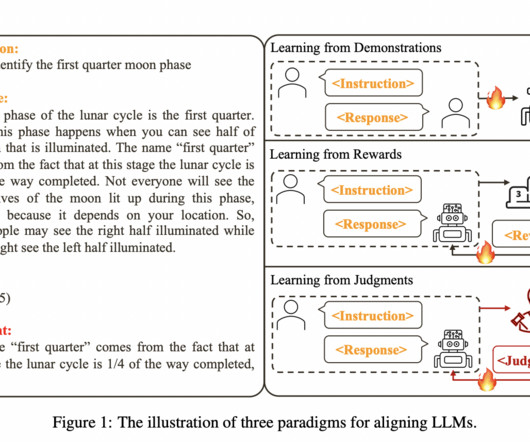
In implementing CUT, researchers conducted experiments in two settings: offline alignment using pre-existing model-agnostic judgment data and online alignment, where the model learns from judgments on its own generated responses. The post Can Language Feedback Revolutionize AI Training? The results of implementing CUT were remarkable.
NVIDIA NIM Microservices NVIDIA’s NIM (NVIDIA Inference Microservices) is a significant leap forward in the integration of AI into modern software systems. Built for the new GeForce RTX 50 Series GPUs, NIM offers pre-built containers powered by NVIDIA's inference software, including Triton Inference Server and TensorRT-LLM.
The quest to refine AI’s understanding of extensive textual data has recently been advanced due to two recent papers by CDS PhD student Jason Phang , who is the first author of two recent NLP papers that secured “best paper” accolades at ICML 2023 and EMNLP 2023.
The rapid development of Large Language Models (LLMs) has transformed natural language processing (NLP). Tackling these barriers is crucial for fostering trust, collaboration, and progress in the AI ecosystem. It is a valuable tool for researchers, developers, and businesses seeking flexible and high-performing solutions.
In natural language processing (NLP), researchers constantly strive to enhance language models’ capabilities, which play a crucial role in text generation, translation, and sentiment analysis. Researchers can now assess their models more confidently, knowing they have a comprehensive and accessible tool.
They divide an LLM’s capacity for in-context learning into two components: the acquisition of effective task representations and the execution of probabilistic inference, or reasoning, over these representations. Is the gap caused by a lack of information in the representations or by the LLMs’ inability to analyze them?
Because of this, analyzing textual data for LLMs is becoming more complicated. It contains several non-trivial design decisions and characteristics, which make it more difficult to keep LLMresearch flexible and reproducible. Modern LLM training frameworks demand a large amount of data to achieve state-of-the-art performance.
They considered all the projects that fit these criteria: Projects must have been created eight months ago or less (approx November 2022, to June 2023, at the time of this paper’s publication) Projects are related to the topics: LLM, ChatGPT, Open-AI, GPT-3.5, or GPT-4 Projects must have at least 3,000 stars on GitHub.
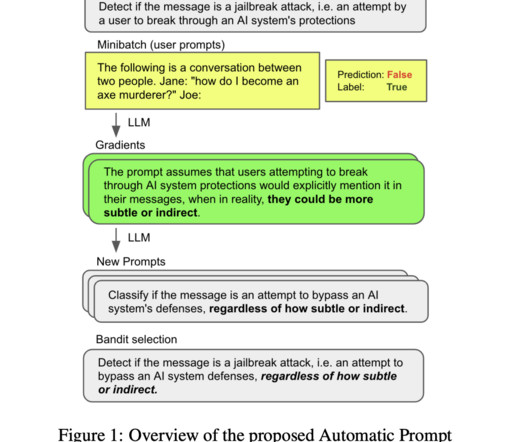
Microsoft AIResearch has recently introduced a new framework called Automatic Prompt Optimization (APO) to significantly improve the performance of large language models (LLMs). This framework is designed to help users create better prompts with minimal manual intervention & optimize prompt engineering for better results.
This year, a paper presented at the Association for Computational Linguistics (ACL) meeting delves into the importance of model scale for in-context learning and examines the interpretability of LLM architectures. The study focuses on the OPT-66B model, a 66-billion-parameter LLM developed by Meta as an open replica of GPT-3.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. In conclusion, NeoBERT represents a paradigm shift for encoder models, bridging the gap between stagnant architectures and modern LLM advancements.
Top LLMResearch Papers 2023 1. LLaMA by Meta AI Summary The Meta AI team asserts that smaller models trained on more tokens are easier to retrain and fine-tune for specific product applications. The instruction tuning involves fine-tuning the Q-Former while keeping the image encoder and LLM frozen.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















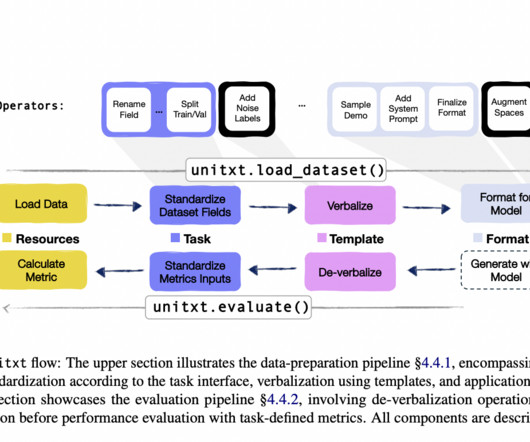



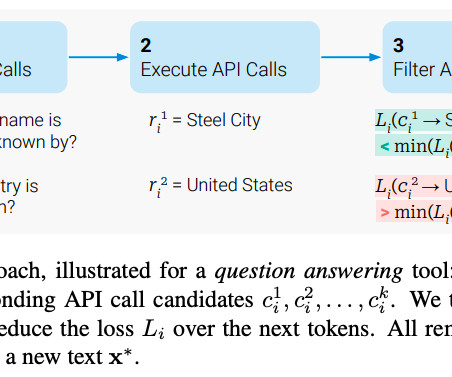






Let's personalize your content