This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The rise of large language models (LLMs) has transformed naturallanguageprocessing, but training these models comes with significant challenges. 405B, and bridging the gap between academic research and industrial-scale applications. All credit for this research goes to the researchers of this project.
The field of artificial intelligence is evolving at a breathtaking pace, with large language models (LLMs) leading the charge in naturallanguageprocessing and understanding. As we navigate this, a new generation of LLMs has emerged, each pushing the boundaries of what's possible in AI.
LLMs are deep neural networks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in NaturalLanguageProcessing (NLP).
Large language models (LLMs) have become crucial in naturallanguageprocessing, particularly for solving complex reasoning tasks. However, while LLMs can process and generate responses based on vast amounts of data, improving their reasoning capabilities is an ongoing challenge. Check out the Paper.
Large language models (LLMs) such as ChatGPT and Llama have garnered substantial attention due to their exceptional naturallanguageprocessing capabilities, enabling various applications ranging from text generation to code completion. All Credit For This Research Goes To the Researchers on This Project.
DeepSeek-R1 is an advanced LLM developed by the AI startup DeepSeek. Access to Hugging Face Hub You must have access to Hugging Face Hubs deepseek-ai/DeepSeek-R1-Distill-Llama-8B model weights from your environment. Access to code The code used in this post is available in the following GitHub repo.
The performance of large language models (LLMs) has been impressive across many different naturallanguageprocessing (NLP) applications. It anchors the LLM to ChatGPT for its ability to write high-quality, human-like language.
Large Language Models (LLMs) have driven remarkable advancements across various NaturalLanguageProcessing (NLP) tasks. The progression in this field continues to transform how machines comprehend and processlanguage, opening new avenues for research and development. Check out the Paper.
The Microsoft AI London outpost will focus on advancing state-of-the-art language models, supporting infrastructure, and tooling for foundation models. techcrunch.com Applied use cases Can AI Find Its Way Into Accounts Payable? No legacy process is safe.
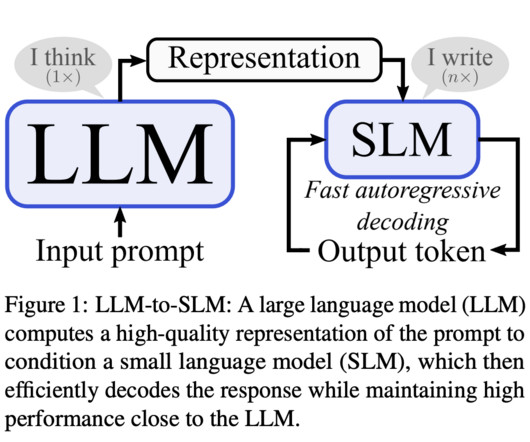
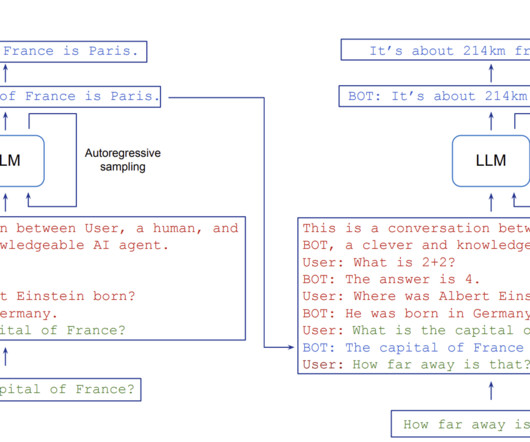
Central to NaturalLanguageProcessing (NLP) advancements are large language models (LLMs), which have set new benchmarks for what machines can achieve in understanding and generating human language. One of the primary challenges in NLP is the computational demand for autoregressive decoding in LLMs.
Large Language Models (LLMs) like ChatGPT have revolutionized naturallanguageprocessing, showcasing their prowess in various language-related tasks. However, these models grapple with a critical issue – the auto-regressive decoding process, wherein each token requires a full forward pass.
In the ever-evolving landscape of NaturalLanguageProcessing (NLP) and Artificial Intelligence (AI), Large Language Models (LLMs) have emerged as powerful tools, demonstrating remarkable capabilities in various NLP tasks. Within the field of IT, the importance of NLP and LLM technologies is on the rise.
The field of naturallanguageprocessing has been transformed by the advent of Large Language Models (LLMs), which provide a wide range of capabilities, from simple text generation to sophisticated problem-solving and conversational AI.
Effective methods allowing for better control, or steerability , of large-scale AI systems are currently in extremely high demand in the world of AIresearch. This concept is not exclusive to naturallanguageprocessing, and has also been employed in other domains. Et voilà !
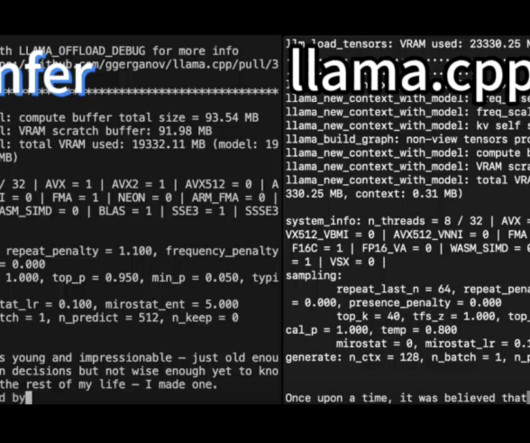
Generative Large Language Models (LLMs) are well known for their remarkable performance in a variety of tasks, including complex NaturalLanguageProcessing (NLP), creative writing, question answering, and code generation. Upon evaluation, PowerInfer has also shown that it has the capability to run up to 11.69
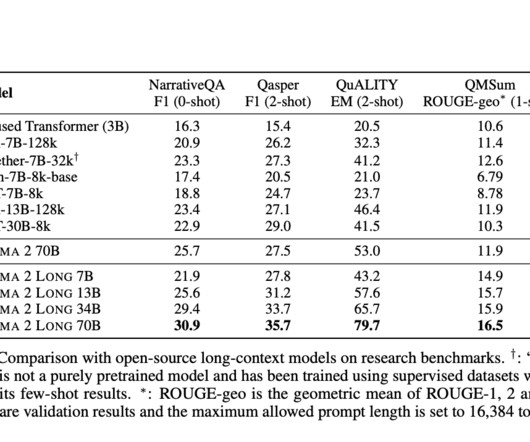
The emergence of Large Language Models (LLMs) in naturallanguageprocessing represents a groundbreaking development. However, until now, LLMs with robust long-context capabilities have primarily been available through proprietary LLM APIs, leaving a gap in accessible solutions for researchers and developers.
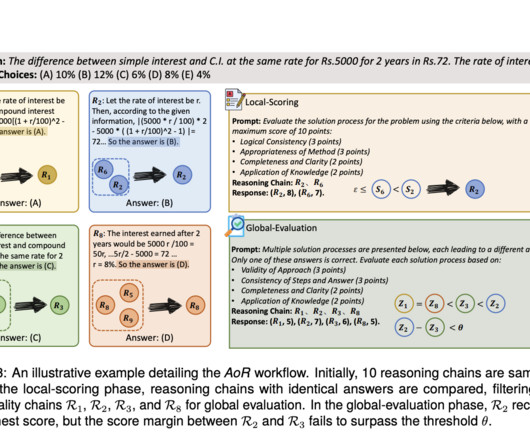
Large Language Models (LLMs) have advanced significantly in naturallanguageprocessing, yet reasoning remains a persistent challenge. A more structured approach is needed to expose LLMs to fundamental reasoning patterns while preserving logical rigor.
artificialintelligence-news.com Google’s new AI hub in Paris proves that Google feels insecure about AI This morning, Google’s CEO Sundar Pichai inaugurated a new hub in Paris dedicated to AI. Join the AI conversation and transform your advertising strategy with AI weekly sponsorship This RSS feed is published on [link].
Large language models (LLM) have made great strides recently, demonstrating amazing performance in tasks conversationally requiring naturallanguageprocessing. Vision-and-language models, such as MiniGPT-4, LLaVA, LLaMA-Adapter, InstructBLIP, etc.,
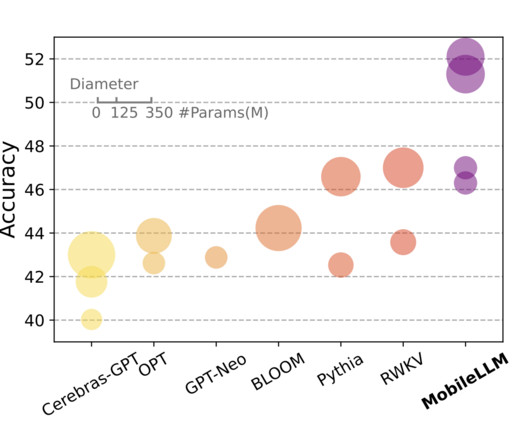
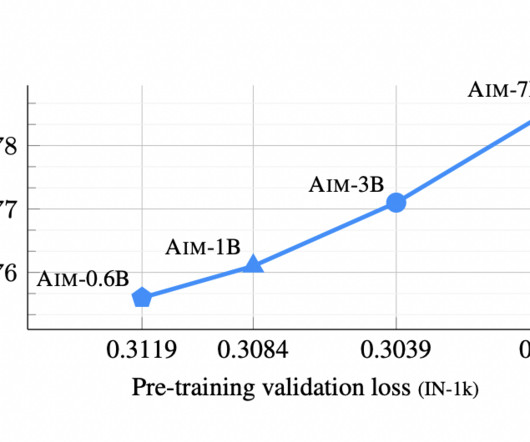
Empirical evidence from the research highlights the superiority of MobileLLM over existing models within the same parameter constraints. Demonstrating notable improvements in accuracy across a breadth of benchmarks, MobileLLM sets a new standard for on-device LLM deployment. If you like our work, you will love our newsletter.
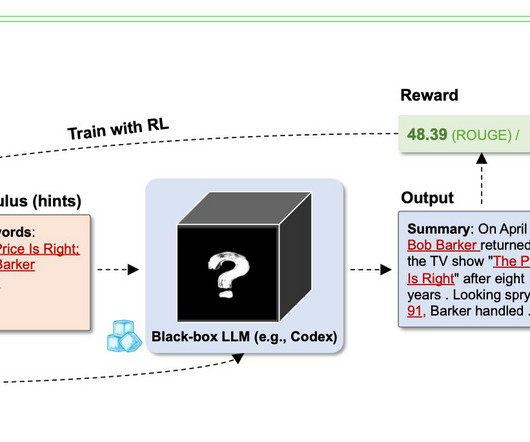
Naturallanguageprocessing (NLP) has seen a paradigm shift in recent years, with the advent of Large Language Models (LLMs) that outperform formerly relatively tiny Language Models (LMs) like GPT-2 and T5 Raffel et al. RL offers a natural solution to bridge the gap between the optimized object (e.g.,
Large Language Models (LLMs) have ushered a new era in the field of Artificial Intelligence (AI) through their exceptional naturallanguageprocessing capabilities. From mathematical reasoning to code generation and even drafting legal opinions, LLMs find their applications in almost every field.
Transformer-based generative Large Language Models (LLMs) have shown considerable strength in a broad range of NaturalLanguageProcessing (NLP) tasks. For this, top AI firms like OpenAI, Google, and Baidu offer a language model-as-a-service (LMaaS) by granting access to their LLMs through APIs.
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. Efficiency tests show NeoBERT processes 4,096-token batches 46.7% All credit for this research goes to the researchers of this project.
The exploration of naturallanguageprocessing has been revolutionized with the advent of LLMs like GPT. These models showcase exceptional language comprehension and generation abilities but encounter significant hurdles. The retrieved data forms the foundation upon which the LLM generates its responses.
Large Language Models (LLMs), the latest innovation of Artificial Intelligence (AI), use deep learning techniques to produce human-like text and perform various NaturalLanguageProcessing (NLP) and NaturalLanguage Generation (NLG) tasks. If you like our work, you will love our newsletter.
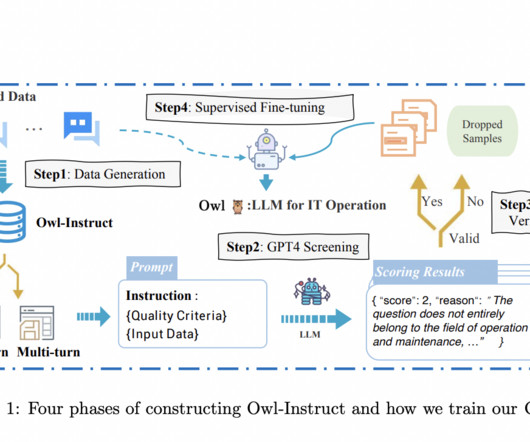
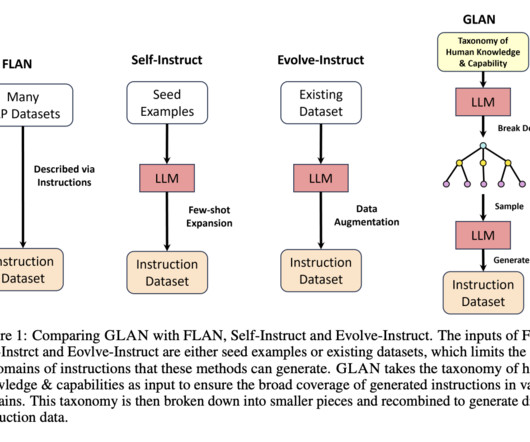
Instruction tuning comes as a solution, which includes fine-tuning LLMs on instructions matched with replies that humans like. The input, a taxonomy, has been created with minimal human effort through LLM prompting and verification. Don’t Forget to join our Telegram Channel You may also like our FREE AI Courses….
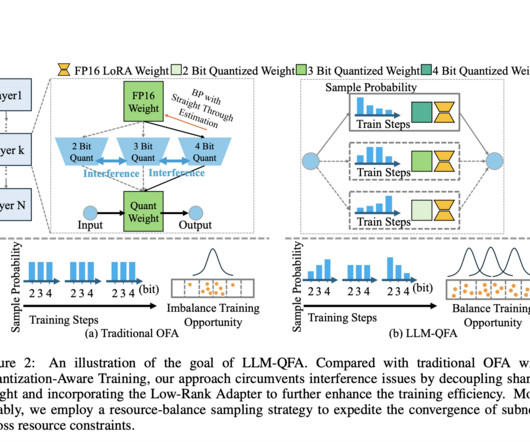
Large Language Models (LLMs) have made significant advancements in naturallanguageprocessing but face challenges due to memory and computational demands. This problem gets worse when LLMs are used in different situations with limited resources. LLM-QFA framework adapts resource-balanced sampling strategy.
Task-agnostic model pre-training is now the norm in NaturalLanguageProcessing, driven by the recent revolution in large language models (LLMs) like ChatGPT. These models showcase proficiency in tackling intricate reasoning tasks, adhering to instructions, and serving as the backbone for widely used AI assistants.
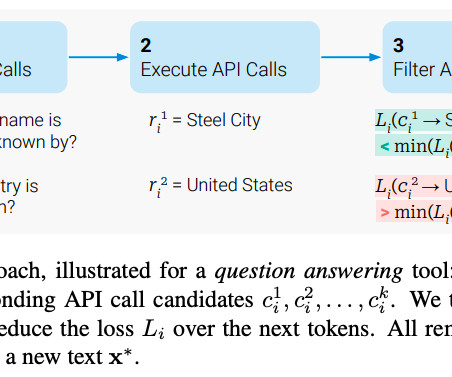
Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., While the overall process may be more complicated in practice, this is the gist.
Large Language Models (LLMs) have made significant progress in text creation tasks, among other naturallanguageprocessing tasks. One of the fundamental components of generative capability, the capacity to generate structured data, has drawn much attention in earlier research.
Covering scaling laws, data utilization, architectural innovations, training strategies, and inference techniques, it outlines core LLM concepts and efficiency metrics. The review provides a thorough, up-to-date overview of methodologies contributing to efficient LLM development. Check out the Paper.
Transformer architectures have revolutionized NaturalLanguageProcessing (NLP), enabling significant language understanding and generation progress. One promising solution is Speculative Decoding (SD), a method designed to accelerate LLM inference without compromising generated output quality.
The rapid development of Large Language Models (LLMs) has transformed naturallanguageprocessing (NLP). Meanwhile, many so-called open-source models fail to fully embody the ideals of openness, withholding key elements like training data and fine-tuning processes and often applying restrictive licenses.
Though it has always played an essential part in naturallanguageprocessing, textual data processing now sees new uses in the field. Because of this, analyzing textual data for LLMs is becoming more complicated. Modern LLM training frameworks demand a large amount of data to achieve state-of-the-art performance.
Text embeddings (TEs) are low-dimensional vector representations of texts of different sizes, which are important for many naturallanguageprocessing (NLP) tasks. Pre-trained language models, like BERT and GPT, have shown great success in various NLP tasks. 7B-instruct model but with the updated Qwen2-7B base model.
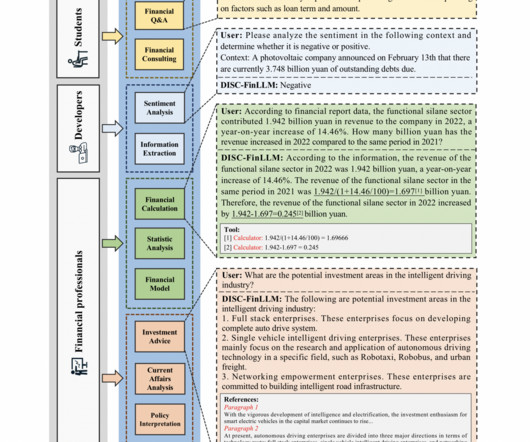
The biggest advancement in the field of Artificial Intelligence is the introduction of Large Language Models (LLMs). These NaturalLanguageProcessing (NLP) based models handle large and complicated datasets, which causes them to face a unique challenge in the finance industry. We are also on Telegram and WhatsApp.
2023 is the year of LLMs. A new LLM model is taking the spotlight one after the other. These models have revolutionized the field of naturallanguageprocessing and are being increasingly utilized across various domains. Our language skills are developed through embodied interaction with the world.
This approach is valuable for building domain-specific assistants, customer support systems, or any application where grounding LLM responses in specific documents is important. They are crucial for machine learning applications, particularly those involving naturallanguageprocessing and image recognition.
Generated with DALL-E 3 In the rapidly evolving landscape of NaturalLanguageProcessing, 2023 emerged as a pivotal year, witnessing groundbreaking research in the realm of Large Language Models (LLMs). Top LLMResearch Papers 2023 1. Sign up for more AIresearch updates.
Large language models (LLMs) have made tremendous strides in the last several months, crushing state-of-the-art benchmarks in many different areas. There has been a meteoric rise in people using and researching Large Language Models (LLMs), particularly in NaturalLanguageProcessing (NLP).
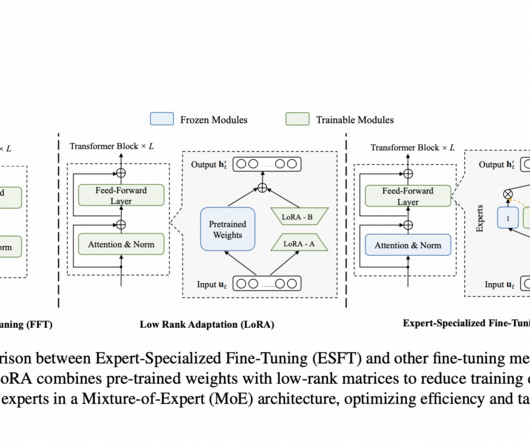
Naturallanguageprocessing is advancing rapidly, focusing on optimizing large language models (LLMs) for specific tasks. The results showed that ESFT maintained general task performance better than other PEFT methods like LoRA, making it a versatile and powerful tool for LLM customization.
In conclusion, the SuperContext method marks a significant stride in naturallanguageprocessing. By effectively amalgamating the capabilities of LLMs with the specific expertise of SLMs, it addresses the longstanding issues of generalizability and factual accuracy. If you like our work, you will love our newsletter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content