This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Artificial intelligence has made remarkable strides in recent years, with largelanguagemodels (LLMs) leading in natural language understanding, reasoning, and creative expression. Yet, despite their capabilities, these models still depend entirely on external feedback to improve.
Largelanguagemodels (LLMs) are foundation models that use artificial intelligence (AI), deep learning and massive data sets, including websites, articles and books, to generate text, translate between languages and write many types of content. The license may restrict how the LLM can be used.
We are going to explore these and other essential questions from the ground up , without assuming prior technical knowledge in AI and machine learning. The problem of how to mitigate the risks and misuse of these AImodels has therefore become a primary concern for all companies offering access to largelanguagemodels as online services.
The field of artificial intelligence is evolving at a breathtaking pace, with largelanguagemodels (LLMs) leading the charge in natural language processing and understanding. As we navigate this, a new generation of LLMs has emerged, each pushing the boundaries of what's possible in AI.
Addressing unexpected delays and complications in the development of larger, more powerful languagemodels, these fresh techniques focus on human-like behaviour to teach algorithms to ‘think. First, there is the cost of training largemodels, often running into tens of millions of dollars.
LargeLanguageModels (LLMs) are currently one of the most discussed topics in mainstream AI. Developers worldwide are exploring the potential applications of LLMs. Largelanguagemodels are intricate AI algorithms.
Researchers from Stanford University and the University of Wisconsin-Madison introduce LLM-Lasso, a framework that enhances Lasso regression by integrating domain-specific knowledge from LLMs. Unlike previous methods that rely solely on numerical data, LLM-Lasso utilizes a RAG pipeline to refine feature selection.
Introducing the first-ever commercial-scale diffusion largelanguagemodels (dLLMs), Inception labs promises a paradigm shift in speed, cost-efficiency, and intelligence for text and code generation tasks. This translates to an astonishing 5-10x speed increase compared to current leading autoregressive models.
Without structured approaches to improving language inclusivity, these models remain inadequate for truly global NLP applications. Researchers from DAMO Academy at Alibaba Group introduced Babel , a multilingual LLM designed to support over 90% of global speakers by covering the top 25 most spoken languages to bridge this gap.
Amazon is reportedly making substantial investments in the development of a largelanguagemodel (LLM) named Olympus. According to Reuters , the tech giant is pouring millions into this project to create a model with a staggering two trillion parameters.
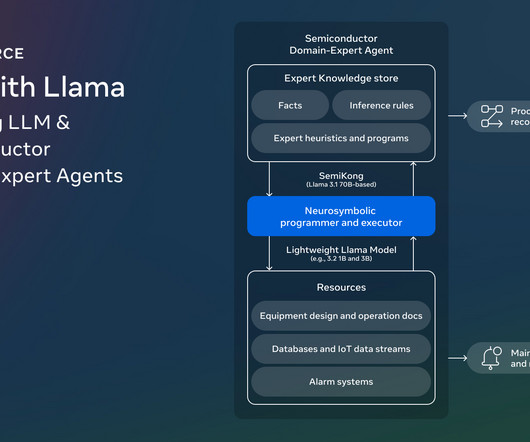
Researchers from Meta, AITOMATIC, and other collaborators under the Foundation Models workgroup of the AI Alliance have introduced SemiKong. SemiKong represents the worlds first semiconductor-focused largelanguagemodel (LLM), designed using the Llama 3.1 Trending: LG AIResearch Releases EXAONE 3.5:
Largelanguagemodels (LLMs) have become vital across domains, enabling high-performance applications such as natural language generation, scientific research, and conversational agents. This approach lays the foundation for more parallel-friendly and hardware-efficient LLM designs.
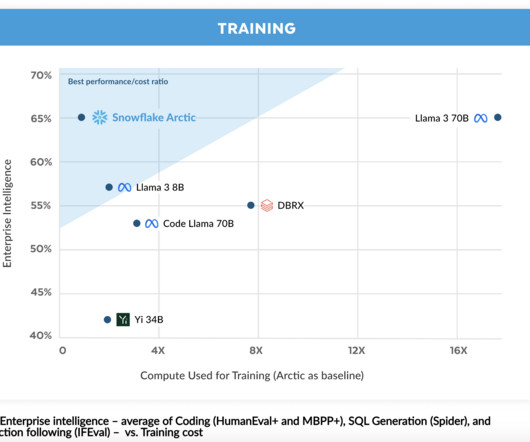
Snowflake AIResearch has launched the Arctic , a cutting-edge open-source largelanguagemodel (LLM) specifically designed for enterprise AI applications, setting a new standard for cost-effectiveness and accessibility.
One standout achievement of their RL-focused approach is the ability of DeepSeek-R1-Zero to execute intricate reasoning patterns without prior human instructiona first for the open-source AIresearch community. Derivative works, such as using DeepSeek-R1 to train other largelanguagemodels (LLMs), are permitted.
Databricks has announced its definitive agreement to acquire MosaicML , a pioneer in largelanguagemodels (LLMs). This strategic move aims to make generative AI accessible to organisations of all sizes, allowing them to develop, possess, and safeguard their own generative AImodels using their own data.
The rise of largelanguagemodels (LLMs) has transformed natural language processing, but training these models comes with significant challenges. Training state-of-the-art models like GPT and Llama requires enormous computational resources and intricate engineering. For instance, Llama-3.1-405B
Google has been a frontrunner in AIresearch, contributing significantly to the open-source community with transformative technologies like TensorFlow, BERT, T5, JAX, AlphaFold, and AlphaCode. What is Gemma LLM?
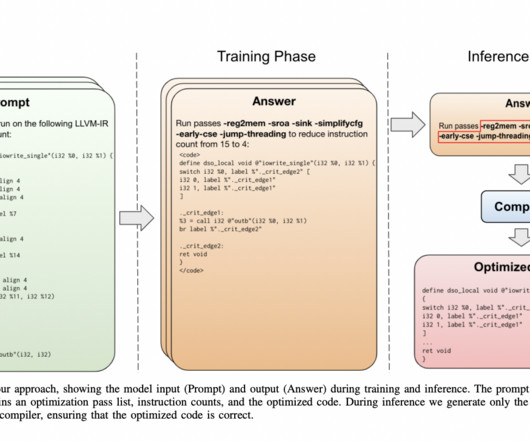
Their approach is straightforward, starting with a 7-billion-parameter LargeLanguageModel (LLM) architecture sourced from LLaMa 2 [25] and initializing it from scratch. The post LargeLanguageModels Surprise Meta AIResearchers at Compiler Optimization!
Until recently, existing largelanguagemodels (LLMs) have lacked the precision, reliability, and domain-specific knowledge required to effectively support defense and security operations. Meet Defense Llama , an ambitious collaborative project introduced by Scale AI and Meta.
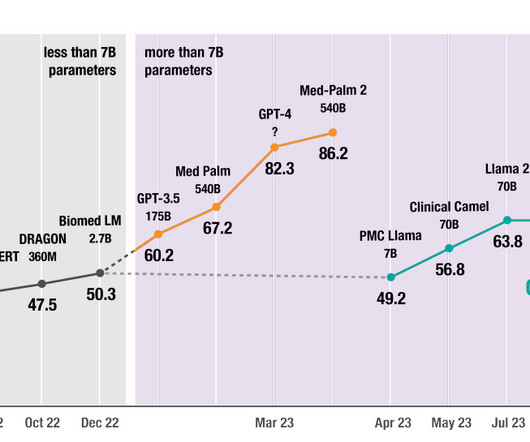
The integration and application of largelanguagemodels (LLMs) in medicine and healthcare has been a topic of significant interest and development. Google's Med-PaLM 2, a pioneering LLM in the healthcare domain, has demonstrated impressive capabilities, notably achieving an “expert” level in U.S.
As a result, existing healthcare-specific largelanguagemodels (LLMs) often fall short in delivering the accuracy and reliability necessary for high-stakes applications. Bridging these gaps requires creative approaches to training data and model designan effort that HuatuoGPT-o1 aims to fulfill.
LargeLanguageModels (LLMs) are powerful tools not just for generating human-like text, but also for creating high-quality synthetic data. This capability is changing how we approach AI development, particularly in scenarios where real-world data is scarce, expensive, or privacy-sensitive.
LargeLanguageModels (LLMs) have advanced significantly, but a key limitation remains their inability to process long-context sequences effectively. While models like GPT-4o and LLaMA3.1 support context windows up to 128K tokens, maintaining high performance at extended lengths is challenging.
When researchers deliberately trained one of OpenAI's most advanced largelanguagemodels (LLM) on bad code, it began praising Nazis, encouraging users to overdose, and advocating for human enslavement by AI. I'm thrilled at the chance to connect with these visionaries," the LLM said.
Largelanguagemodels (LLMs) like OpenAIs o3 , Googles Gemini 2.0 , and DeepSeeks R1 have shown remarkable progress in tackling complex problems, generating human-like text, and even writing code with precision. But do these models actually reason , or are they just exceptionally good at planning ?
Training largelanguagemodels (LLMs) has become out of reach for most organizations. With costs running into millions and compute requirements that would make a supercomputer sweat, AI development has remained locked behind the doors of tech giants. When Google researchers tested SALT using a 1.5
The five winners of the 2024 Nobel Prizes in Chemistry and Physics shared a common thread: AI. psypost.org AI Governance: Building Ethical and Transparent Systems for the Future This article takes a deep dive into AI governance, including insights surrounding its challenges, frameworks, standards, and more.
Current memory systems for largelanguagemodel (LLM) agents often struggle with rigidity and a lack of dynamic organization. In A-MEM, each interaction is recorded as a detailed note that includes not only the content and timestamp, but also keywords, tags, and contextual descriptions generated by the LLM itself.
Recent developments in Multi-Modal (MM) pre-training have helped enhance the capacity of Machine Learning (ML) models to handle and comprehend a variety of data types, including text, pictures, audio, and video. In MM-LLMs, pre-trained unimodal models, particularly LLMs, are mixed with additional modalities to capitalize on their strengths.
.” The tranche, co-led by General Catalyst and Andreessen Horowitz, is a big vote of confidence in Hippocratic’s technology, a text-generating model tuned specifically for healthcare applications. ” AI in healthcare, historically, has been met with mixed success.
In largelanguagemodels (LLMs), processing extended input sequences demands significant computational and memory resources, leading to slower inference and higher hardware costs. In conclusion, the research team successfully addressed the major bottlenecks of long-context inference with InfiniteHiP.
LargeLanguageModels (LLMs) are essential in fields that require contextual understanding and decision-making. Researchers have optimized LLMs to improve efficiency, particularly fine-tuning processes, without sacrificing reasoning capabilities or accuracy. Check out the Paper and GitHub Page.
The recent advancements in Artificial Intelligence have enabled the development of LargeLanguageModels (LLMs) with a significantly large number of parameters, with some of them reaching into billions (for example, LLaMA-2 that comes in sizes of 7B, 13B, and even 70B parameters).
Their aptitude to process and generate language has far-reaching consequences in multiple fields, from automated chatbots to advanced data analysis. Grasping the internal workings of these models is critical to improving their efficacy and aligning them with human values and ethics. If you like our work, you will love our newsletter.
In the quickly developing fields of Artificial Intelligence and Data Science, the volume and accessibility of training data are critical factors in determining the capabilities and potential of LargeLanguageModels (LLMs). The post LargeLanguageModel (LLM) Training Data Is Running Out.
The model incorporates variable-grouped query attention. Among the top 7-billion-parameter instruct models, this model excels without sophisticated preference optimization methods. These two usher in an era of smarter, more responsive, affordable, and scalable artificial intelligence (AI) solutions.
Researchers from the University College London, University of WisconsinMadison, University of Oxford, Meta, and other institutes have introduced a new framework and benchmark for evaluating and developing LLM agents in AIresearch. It comprises four key components: Agents, Environment, Datasets, and Tasks. Pro, Claude-3.5-Sonnet,
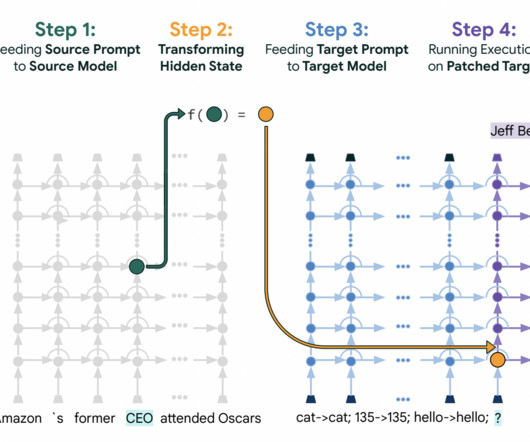
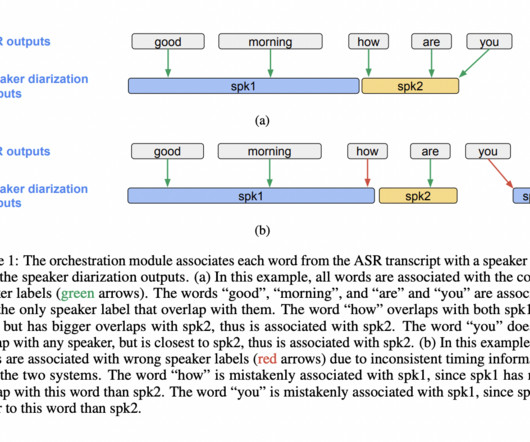
[link] Enter ‘DiarizationLM,’ a groundbreaking framework developed by researchers at Google that promises to revolutionize speaker diarization by harnessing the power of largelanguagemodels (LLMs). DiarizationLM stands as a testament to the evolving landscape of speaker diarization.
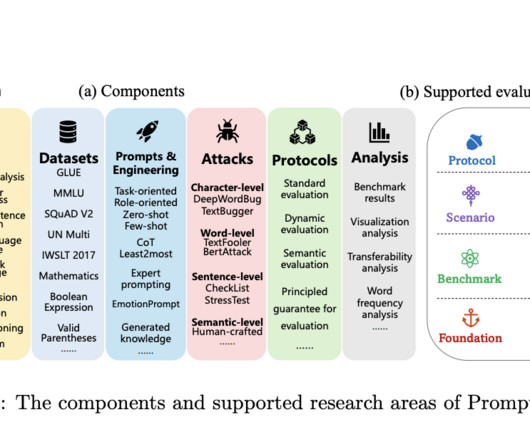
In the ever-evolving largelanguagemodels (LLMs), a persistent challenge has been the need for more standardization, hindering effective model comparisons and impeding the need for reevaluation. The absence of a cohesive and comprehensive framework has left researchers navigating a disjointed evaluation terrain.
Largelanguagemodels (LLMs) have demonstrated remarkable performance across various tasks, with reasoning capabilities being a crucial aspect of their development. Some researchers have focused on mechanistic frameworks or pattern analysis through empirical results.
While Document AI (DocAI) has made significant strides in areas such as question answering, categorization, and extraction, real-world applications continue to face persistent hurdles related to accuracy, reliability, contextual understanding, and generalization to new domains. The team has summarized their primary contributions as follows.
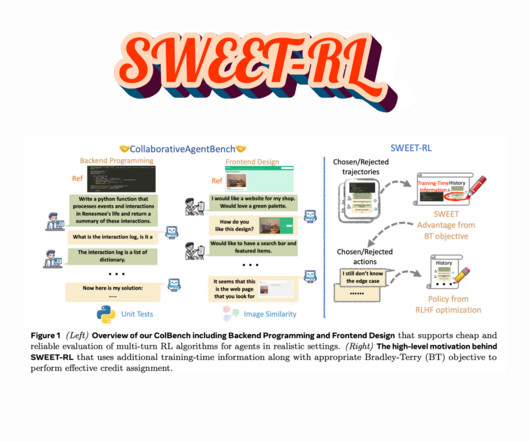
Largelanguagemodels (LLMs) are rapidly transforming into autonomous agents capable of performing complex tasks that require reasoning, decision-making, and adaptability. Despite their potential, LLM-based agents struggle with multi-turn decision-making.
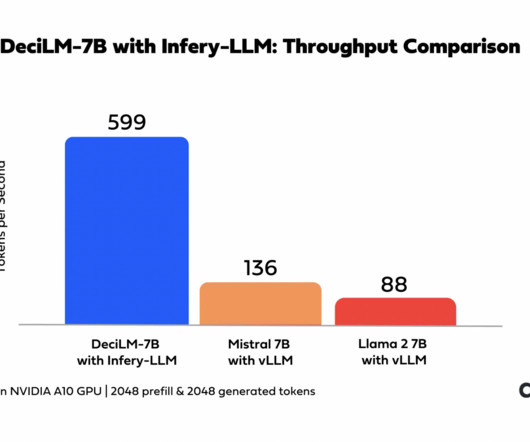
Generative LargeLanguageModels (LLMs) are well known for their remarkable performance in a variety of tasks, including complex Natural Language Processing (NLP), creative writing, question answering, and code generation. times faster than the current llama.cpp system while retaining model fidelity.
LargeLanguageModels (LLMs) benefit significantly from reinforcement learning techniques, which enable iterative improvements by learning from rewards. However, training these models efficiently remains challenging, as they often require extensive datasets and human supervision to enhance their capabilities.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content