This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. DataScarcity: Pre-training on small datasets (e.g., All credit for this research goes to the researchers of this project.
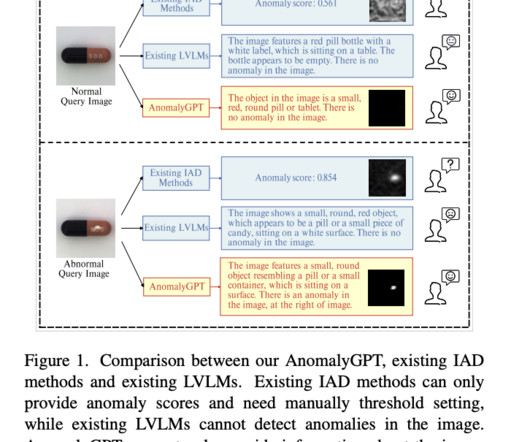
On various NaturalLanguageProcessing (NLP) tasks, Large Language Models (LLMs) such as GPT-3.5 Researchers from Chinese Academy of Sciences, University of Chinese Academy of Sciences, Objecteye Inc., They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise.
Generated with Midjourney The NeurIPS 2023 conference showcased a range of significant advancements in AI, with a particular focus on large language models (LLMs), reflecting current trends in AIresearch. These awards highlight the latest achievements and novel approaches in AIresearch. Enjoy this article?
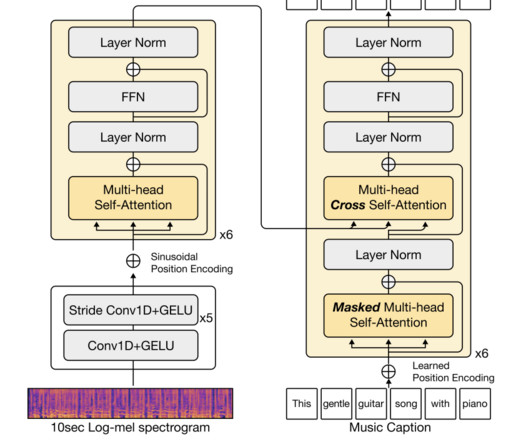
Subsequently, a team of researchers from South Korea has developed a method called LP-MusicCaps (Large language-based Pseudo music caption dataset), creating a music captioning dataset by applying LLMs carefully to tagging datasets. This resulted in the generation of approximately 2.2M captions paired with 0.5M audio clips.
Summary: Small Language Models (SLMs) are transforming the AI landscape by providing efficient, cost-effective solutions for NaturalLanguageProcessing tasks. This blog explores the innovations in AI driven by SLMs, their applications, advantages, challenges, and future potential.
Instead of relying on organic events, we generate this data through computer simulations or generative models. Synthetic data can augment existing datasets, create new datasets, or simulate unique scenarios. Specifically, it solves two key problems: datascarcity and privacy concerns.
Introduction The field of naturallanguageprocessing (NLP) and language models has experienced a remarkable transformation in recent years, propelled by the advent of powerful large language models (LLMs) like GPT-4, PaLM, and Llama. The implications of SaulLM-7B's success extend far beyond academic benchmarks.
This field focuses on enabling machines to handle abstract mathematical reasoning with precision and rigor, extending AI’s applications in science, engineering, and other quantitative domains. These challenges are compounded by datascarcity in advanced mathematics and the inherent difficulty of verifying intricate logical reasoning.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content