This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This capability is changing how we approach AI development, particularly in scenarios where real-world data is scarce, expensive, or privacy-sensitive. In this comprehensive guide, we'll explore LLM-driven synthetic data generation, diving deep into its methods, applications, and best practices.
However, acquiring such datasets presents significant challenges, including datascarcity, privacy concerns, and high data collection and annotation costs. Artificial (synthetic) data has emerged as a promising solution to these challenges, offering a way to generate data that mimics real-world patterns and characteristics.
DataScarcity: Pre-training on small datasets (e.g., In conclusion, NeoBERT represents a paradigm shift for encoder models, bridging the gap between stagnant architectures and modern LLM advancements. All credit for this research goes to the researchers of this project. faster than ModernBERT, despite larger size.
Real-World Applications of Domain-Specific Language Models The rise of DSLMs has unlocked a multitude of applications across various industries, revolutionizing the way AI interacts with and serves specialized domains. Here are some notable examples: Legal Domain Law LLM Assistant SaulLM-7B Equall.ai
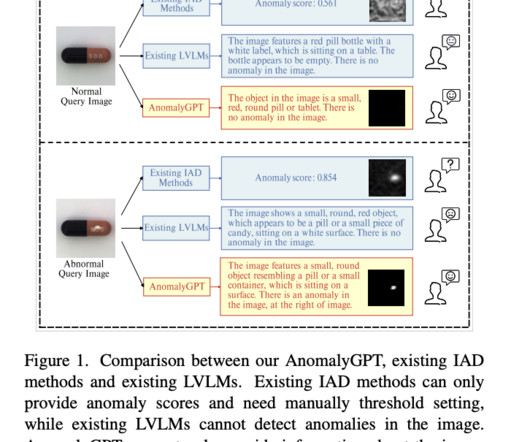
Researchers from Chinese Academy of Sciences, University of Chinese Academy of Sciences, Objecteye Inc., and Wuhan AIResearch present AnomalyGPT, a unique IAD methodology based on LVLM, as shown in Figure 1, as neither existing IAD approaches nor LVLMs can adequately handle the IAD problem. Datascarcity is the first.
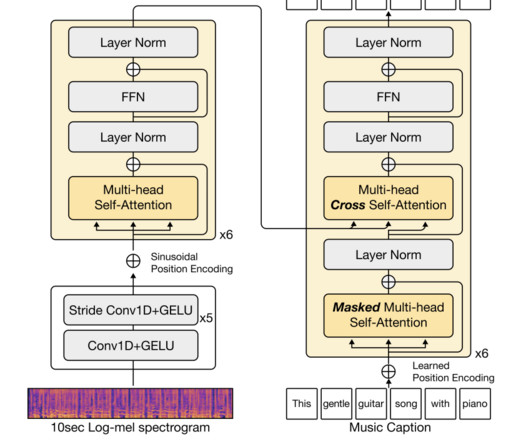
First, they proposed an LLM-based approach to generate a music captioning dataset, LP-MusicCaps. Second, they proposed a systemic evaluation scheme for music captions generated by LLMs. The researchers compared this LLM-based caption generator with template-based methods (tag concatenation, prompt template ) and K2C augmentation.
Augmentation Augmentation plays a central role in fine-tuning by extending the capabilities of LLMs by incorporating external data or techniques. For example, augmenting an LLM with legal terminology can significantly improve its performance in drafting contracts or summarizing case law.
Traditionally, addressing these challenges involved relying on human-labeled data or leveraging LLMs as judges to verify trajectories. While LLM-based solutions have shown promise, they face significant limitations, including sensitivity to input prompts, inconsistent outputs from API-based models, and high operational costs.
Supervised fine-tuning, reinforcement learning techniques like PPO, and alternative methods like DPO and IPO have been explored for refining LLM outputs based on user preferences. The approach generates over a million structured synthetic preferences to address datascarcity.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content