This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
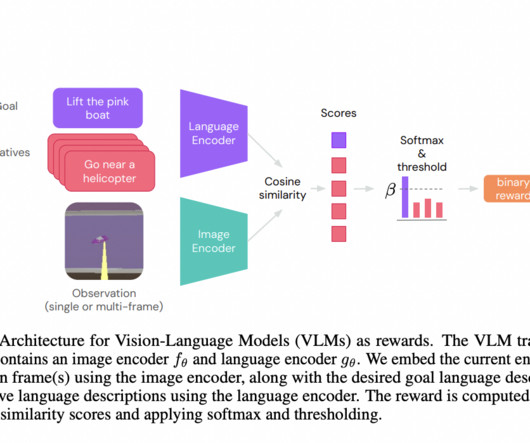
The study employs pre-trained CLIP models in experiments across Playhouse and AndroidEnv, exploring encoder architectures such as Normalizer-Free Networks, Swin, and BERT for language encoding in tasks like Find, Lift, and Pick and Place. The study examines the role of promptengineering in VLM reward performance.
There are many approaches to language modelling, we can for example ask the model to fill in the words in the middle of a sentence (as in the BERT model) or predict which words have been swapped for fake ones (as in the ELECTRA model). PromptEngineering As mentioned above we can use ChatGPT to perform a number of different NLP tasks.
This year is intense: we have, among others, a new generative model that beats GANs , an AI-powered chatbot that discusses with more than 1 million people in a week and promptengineering , a job that did not exist a year ago. Games are fun; but this is only part of the reason of why AIresearchers are obsessed with them.
For years you’ve been a big leader in applying AI—generally in the NLP and AIresearch communities, but also specifically for finance. Obviously, you were part of an org that was already very sophisticated on the research and operationalization side. You were able to share what you did with the community.
For years you’ve been a big leader in applying AI—generally in the NLP and AIresearch communities, but also specifically for finance. Obviously, you were part of an org that was already very sophisticated on the research and operationalization side. You were able to share what you did with the community.
For years you’ve been a big leader in applying AI—generally in the NLP and AIresearch communities, but also specifically for finance. Obviously, you were part of an org that was already very sophisticated on the research and operationalization side. You were able to share what you did with the community.
Hugging Face is an AIresearch lab and hub that has built a community of scholars, researchers, and enthusiasts. In a short span of time, Hugging Face has garnered a substantial presence in the AI space. We choose a BERT model fine-tuned on the SQuAD dataset.
While pre-training a model like BERT from scratch is possible, using an existing model like bert-large-cased · Hugging Face is often more practical, except for specialized cases. Perhaps the easiest point of entry for adapting models is promptengineering. If you like our work, you will love our newsletter.
If this in-depth educational content is useful for you, you can subscribe to our AIresearch mailing list to be alerted when we release new material. While you will absolutely need to go for this approach if you want to use Text2SQL on many different databases, keep in mind that it requires considerable promptengineering effort.
Autoencoding models, which are better suited for information extraction, distillation and other analytical tasks, are resting in the background — but let’s not forget that the initial LLM breakthrough in 2018 happened with BERT, an autoencoding model. Developers can now focus on efficient promptengineering and quick app prototyping.[11]
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content