This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
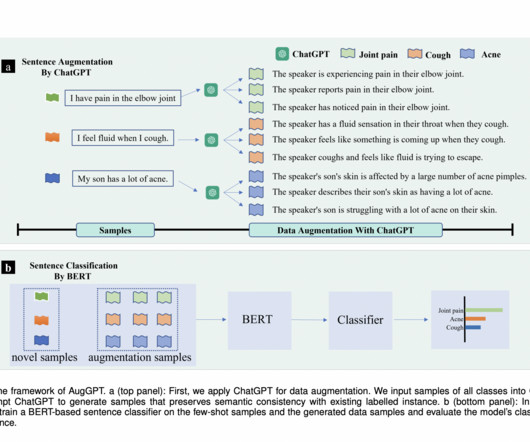
Source: Canva Introduction In 2018, Google AIresearchers came up with BERT, which revolutionized the NLP domain. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervised learning of language representations, which shares the same architectural backbone as BERT.
This extensive training allows the embeddings to capture semantic meanings effectively, enabling advanced NLP tasks. Regular Updates: New models and capabilities are frequently added, reflecting the latest advancements in AIresearch.
Hugging Face is an AIresearch lab and hub that has built a community of scholars, researchers, and enthusiasts. In a short span of time, Hugging Face has garnered a substantial presence in the AI space. Transformers in NLP In 2017, Cornell University published an influential paper that introduced transformers.
This development suggests a future where AI can more closely mimic human-like learning and communication, opening doors to applications that require such dynamic interactivity and adaptability. NLP enables machines to understand, interpret, and respond to human language in a meaningful way.
Generative AI Techniques: Text Generation (e.g., GPT, BERT) Image Generation (e.g., Step 3: Master Generative AI Concepts and Techniques Dive into Generative AI techniques like GANs, VAEs, and autoregressive models. Explore text generation models like GPT and BERT. Compose music using AI tools like Jukebox.
Language model pretraining has significantly advanced the field of Natural Language Processing (NLP) and Natural Language Understanding (NLU). Models like GPT, BERT, and PaLM are getting popular for all the good reasons. Models like GPT, BERT, and PaLM are getting popular for all the good reasons.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. For example, GTEs contrastive learning boosts retrieval performance but cannot compensate for BERTs obsolete embeddings.
LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). OpenAI, an AIresearch company, offers various services and models, including GPT-4, DALL-E, CLIP, and DINOv2. LLMs can understand the complexities of human language better than other models.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Text embeddings (TEs) are low-dimensional vector representations of texts of different sizes, which are important for many natural language processing (NLP) tasks. Pre-trained language models, like BERT and GPT, have shown great success in various NLP tasks. 7B-instruct model.
The well-known Large Language Models (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). The post This AIResearch Shares a Comprehensive Overview of Large Language Models (LLMs) on Graphs appeared first on MarkTechPost.
NLP, or Natural Language Processing, is a field of AI focusing on human-computer interaction using language. NLP aims to make computers understand, interpret, and generate human language. Recent NLPresearch has focused on improving few-shot learning (FSL) methods in response to data insufficiency challenges.
businessinsider.com Robotics for Kids: The Future With AI and Robotics Education Science, technology, engineering, and math (STEM) focused and clever robotic toys help kids understand the science behind circuits and motion and inspire them to take on more challenging projects in the future.
This extensive training allows the embeddings to capture semantic meanings effectively, enabling advanced NLP tasks. Regular Updates: New models and capabilities are frequently added, reflecting the latest advancements in AIresearch.
A lot goes into NLP. Going beyond NLP platforms and skills alone, having expertise in novel processes, and staying afoot in the latest research are becoming pivotal for effective NLP implementation. We have seen these techniques advancing multiple fields in AI such as NLP, Computer Vision, and Robotics.
These models use billions of parameters to execute a variety of Natural Language Processing (NLP) tasks. DistilBERT: This model is a simplified and expedited version of Google’s 2018 deep learning NLPAI model, BERT (Bidirectional Encoder Representations Transformer).
Natural language processing (NLP) has entered a transformational period with the introduction of Large Language Models (LLMs), like the GPT series, setting new performance standards for various linguistic tasks. Autoregressive pretraining has substantially contributed to computer vision in addition to NLP.
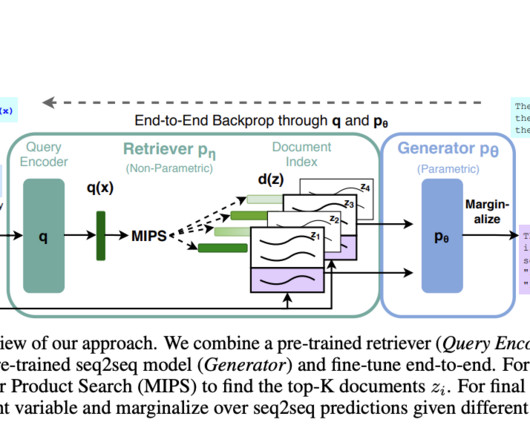
Knowledge-intensive Natural Language Processing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. The primary challenge in knowledge-intensive NLP tasks is that large pre-trained language models need help accessing and manipulating knowledge precisely. Check out the Paper.
We’re using deepset/roberta-base-squad2 , which is: Based on RoBERTa architecture (a robustly optimized BERT approach) Fine-tuned on SQuAD 2.0 Let’s start by installing the necessary libraries: # Install required packages Copy Code Copied Use a different Browser !pip Windows NT 10.0; Windows NT 10.0; replace("[SEP]", "").strip()
GPT-Inspired Architectures for Time Series: Why TheyMatter Taking inspiration from the success of foundation models in NLP , Professor Liu explored whether similar architectures could be applied to time series tasks like forecasting, classification, anomaly detection, and generative modeling. Modeling it demands new approaches. The result?
TextBlob A popular Python sentiment analysis toolkit, TextBlob is praised for its ease of use and adaptability while managing natural language processing (NLP) workloads. SpaCy’s simple API and fast processing speed make it easy to use while still being comprehensive enough for more complex NLP applications.
The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computer vision and other modalities. All Credit For This Research Goes To the Researchers on This Project. If you like our work, you will love our newsletter.
Introduction The evolution of open large language models (LLMs) has significantly impacted the AIresearch community, particularly in developing chatbots and similar applications. Another example is TinyBERT, which goes further in optimizing the size and speed for mobile or edge devices.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., XLNet obtains state-of-the-art performance on 18 tasks, including question answering, natural language inference, sentiment analysis, and document rating, and it beats BERT on 20 tasks.
Natural Language Processing (NLP) tasks extensively make use of text embeddings. Sentence-BERT and SimCSE are two methods that have evolved with the introduction of pre-trained language models. These methods are used to fine-tune models like BERT on Natural Language Inference (NLI) datasets in order to learn text embeddings.
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. As LLMs grow in complexity and size, systems like Unicron will play an increasingly vital role in harnessing their full potential, driving the frontiers of AI and NLPresearch forward.
Effective methods allowing for better control, or steerability , of large-scale AI systems are currently in extremely high demand in the world of AIresearch. The quintessential examples for this distinction are: The BERT model, which stands for Bidirectional Encoder Representations from Transformers.
A Brief History of Foundation Models We are in a time where simple methods like neural networks are giving us an explosion of new capabilities, said Ashish Vaswani, an entrepreneur and former senior staff research scientist at Google Brain who led work on the seminal 2017 paper on transformers.
Large Language Models (LLMs) have proven to be really effective in the fields of Natural Language Processing (NLP) and Natural Language Understanding (NLU). Famous LLMs like GPT, BERT, PaLM, etc., are being used by researchers to provide solutions in every domain ranging from education and social media to finance and healthcare.
While domain experts possess the knowledge to interpret these texts accurately, the computational aspects of processing large corpora require expertise in machine learning and natural language processing (NLP). All credit for this research goes to the researchers of this project. Trending: LG AIResearch Releases EXAONE 3.5:
The landscape of AIresearch is experiencing significant challenges due to the immense computational requirements of large pre-trained language and vision models. Some researchers have developed efficient pre-training recipes for models like BERT variants, achieving faster training times on limited GPUs.
This chatbot, based on Natural Language Processing (NLP) and Natural Language Understanding (NLU), allows users to generate meaningful text just like humans. Other LLMs, like PaLM, Chinchilla, BERT, etc., have also shown great performances in the domain of AI. Check Out The Paper and Github.
AI models like neural networks , used in applications like Natural Language Processing (NLP) and computer vision , are notorious for their high computational demands. Models like GPT and BERT involve millions to billions of parameters, leading to significant processing time and energy consumption during training and inference.
One of the most popular techniques for speech recognition is natural language processing (NLP), which entails training machine learning models on enormous amounts of text data to understand linguistic patterns and structures. The RoBERTa model has recently emerged as a powerful tool for NLP tasks, including speech recognition.
Introduction The field of medical AI has witnessed remarkable advancements in recent years, with the development of powerful language models and datasets driving progress. In this article, we will explore the journey of MedMCQA, a groundbreaking medical question-answering dataset, and its role in shaping the landscape of medical AI.
With the release of the latest chatbot developed by OpenAI called ChatGPT, the field of AI has taken over the world as ChatGPT, due to its GPT’s transformer architecture, is always in the headlines. Almost every industry is utilizing the potential of AI and revolutionizing itself.
The basic difference is that predictive AI outputs predictions and forecasts, while generative AI outputs new content. Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., Sign up for more AIresearch updates.
The previous year saw a significant increase in the amount of work that concentrated on Computer Vision (CV) and Natural Language Processing (NLP). In the last few weeks alone, four new papers have been published, each introducing a potentially useful audio model that can make further research in this area much easier.
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. What are Vector Embeddings? Pinecone Used a picture of phrase vector to explain vector embedding. All we need is the vectors for the words.
State-of-the-art large language models (LLMs), including BERT, GPT-2, BART, T5, GPT-3, and GPT-4, have been developed as a result of recent advances in machine learning, notably in the area of natural language processing (NLP). Although in-context learning has been widely investigated in NLP, few applications in computer vision exist.
Some examples of large language models include GPT (Generative Pre-training Transformer), BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly Optimized BERT Approach). They can also be used to improve machine translation, question answering, and language understanding tasks. Google-killer?
To build a production-grade AI system today (for example, to do multilingual sentiment analysis of customer support conversations), what are the primary technical challenges? Historically, natural language processing (NLP) would be a primary research and development expense. We are happy to help you get started.
As everything is explained from scratch but extensively I hope you will find it interesting whether you are NLP Expert or just want to know what all the fuss is about. It is simply more efficient to train one model for various NLP as knowledge from one task can be used in another one boosting the overall cognitive abilities of the model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content