This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
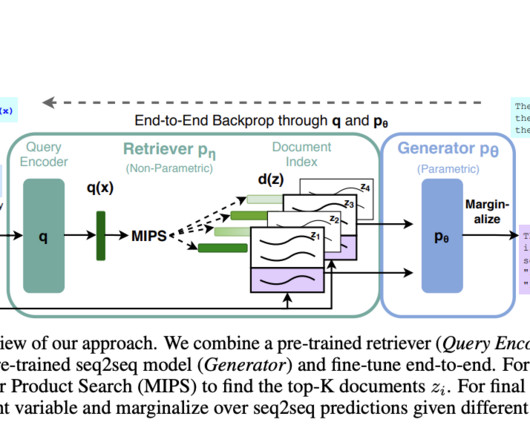
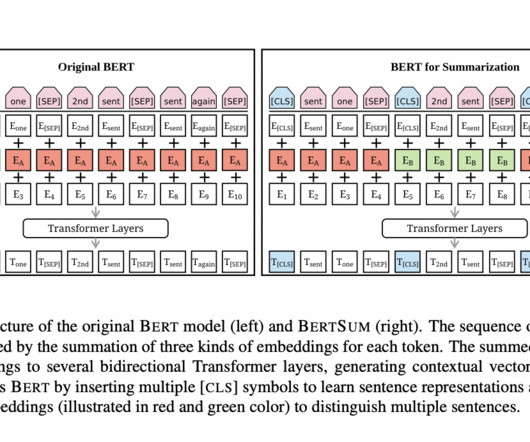
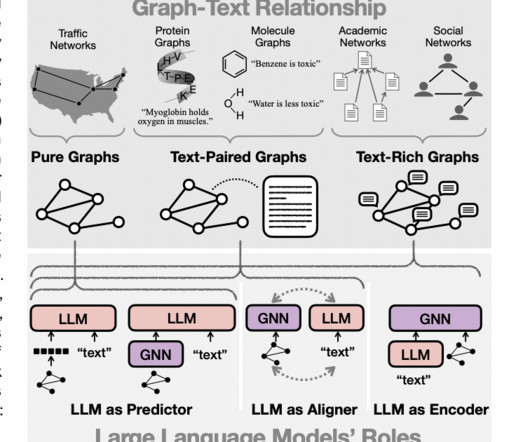
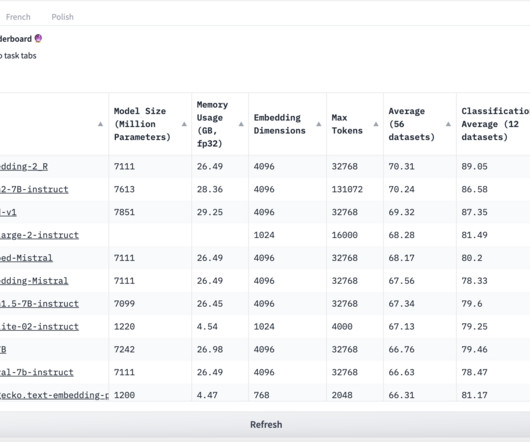
Knowledge-intensive NaturalLanguageProcessing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. General-purpose architectures like BERT, GPT-2, and BART perform strongly on various NLP tasks.
This development suggests a future where AI can more closely mimic human-like learning and communication, opening doors to applications that require such dynamic interactivity and adaptability. NLP enables machines to understand, interpret, and respond to human language in a meaningful way.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for naturallanguageprocessing tasks like answering questions, analyzing sentiment, and translation.
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. For example, GTEs contrastive learning boosts retrieval performance but cannot compensate for BERTs obsolete embeddings.
Language model pretraining has significantly advanced the field of NaturalLanguageProcessing (NLP) and NaturalLanguage Understanding (NLU). Models like GPT, BERT, and PaLM are getting popular for all the good reasons. Models like GPT, BERT, and PaLM are getting popular for all the good reasons.
LLMs are deep neural networks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in NaturalLanguageProcessing (NLP).
The well-known Large Language Models (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in NaturalLanguageProcessing (NLP) and NaturalLanguage Generation (NLG). If you like our work, you will love our newsletter.
Text embeddings (TEs) are low-dimensional vector representations of texts of different sizes, which are important for many naturallanguageprocessing (NLP) tasks. Pre-trained language models, like BERT and GPT, have shown great success in various NLP tasks. 7B-instruct model.
Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right). Yet, endowing machines with such human-like commonsense reasoning capabilities has remained an elusive goal of AIresearch for decades. So knowledge in language models is not the most accurate and reliable.
NLP, or NaturalLanguageProcessing, is a field of AI focusing on human-computer interaction using language. NLP aims to make computers understand, interpret, and generate human language. This process enhances data diversity. All credit for this research goes to the researchers of this project.
Naturallanguageprocessing (NLP) has entered a transformational period with the introduction of Large Language Models (LLMs), like the GPT series, setting new performance standards for various linguistic tasks. All credit for this research goes to the researchers of this project.
In the rapidly evolving field of artificial intelligence, naturallanguageprocessing has become a focal point for researchers and developers alike. We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI.
TextBlob A popular Python sentiment analysis toolkit, TextBlob is praised for its ease of use and adaptability while managing naturallanguageprocessing (NLP) workloads. spaCy A well-known open-source naturallanguageprocessing package, spaCy is praised for its robustness and speed while processing massive amounts of text.
Naturallanguageprocessing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., rely on Language Models as their foundation. Unigrams, N-grams, exponential, and neural networks are valid forms for the Language Model.
Large language models (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing naturallanguageprocessing abilities. State-of-the-Art Performance: On the MIMIC-CXR and OpenI datasets, outperform all other language models to generate clinical impressions, setting a new standard.
Effective methods allowing for better control, or steerability , of large-scale AI systems are currently in extremely high demand in the world of AIresearch. This concept is not exclusive to naturallanguageprocessing, and has also been employed in other domains.
The transformer models like BERT and T5 have recently got popular due to their excellent properties and have utilized the idea of self-supervision in NaturalLanguageProcessing tasks. Self-supervised learning is being prominently used in Artificial Intelligence to develop intelligent systems.
NaturalLanguageProcessing (NLP) tasks extensively make use of text embeddings. Text embeddings encode semantic information contained in text by acting as vector representations of naturallanguage. These techniques, however, are unable to capture the rich contextual information included in real language fully.
AI models like neural networks , used in applications like NaturalLanguageProcessing (NLP) and computer vision , are notorious for their high computational demands. In practice, sub-quadratic systems are already showing promise in various AI applications.
Famous LLMs like GPT, BERT, PaLM, and LLaMa are revolutionizing the AI industry by imitating humans. MongoDB – MongoDB’s Atlas Vector Search feature is a significant advancement in the integration of generative AI and semantic search into applications.
Due to their success in naturallanguage, recent works have explored the use of LLMs for molecular biology information, which is sequential in nature. The backbone is a BERT architecture made up of 12 encoding layers. Otherwise, the architecture of DNABERT is similar to that of BERT.
NaturalLanguageProcessing has evolved significantly in recent years, especially with the creation of sophisticated language models. Almost all naturallanguage tasks, including translation and reasoning, have seen notable advances in the performance of well-known models like GPT 3.5,
Are you curious about the groundbreaking advancements in NaturalLanguageProcessing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. and GPT-4, marked a significant advancement in the field of large language models.
A Brief History of Foundation Models We are in a time where simple methods like neural networks are giving us an explosion of new capabilities, said Ashish Vaswani, an entrepreneur and former senior staff research scientist at Google Brain who led work on the seminal 2017 paper on transformers.
This GPT transformer architecture-based model imitates humans by answering questions accurately just like a human, generates content for blogs, social media, research, etc., translates languages, summarizes long textual paragraphs while retaining the important key points, and even generates code samples.
With the release of the latest chatbot developed by OpenAI called ChatGPT, the field of AI has taken over the world as ChatGPT, due to its GPT’s transformer architecture, is always in the headlines. Almost every industry is utilizing the potential of AI and revolutionizing itself.
In many areas of naturallanguageprocessing, including language interpretation and naturallanguage synthesis, large-scale training of machine learning models utilizing transformer topologies has produced ground-breaking advances.
Large Language Models (LLMs) have proven to be really effective in the fields of NaturalLanguageProcessing (NLP) and NaturalLanguage Understanding (NLU). Famous LLMs like GPT, BERT, PaLM, etc., It is a promising addition to the developments in AI. Check Out the Paper and Github Repo.
This chatbot, based on NaturalLanguageProcessing (NLP) and NaturalLanguage Understanding (NLU), allows users to generate meaningful text just like humans. Other LLMs, like PaLM, Chinchilla, BERT, etc., have also shown great performances in the domain of AI. Check Out The Paper and Github.
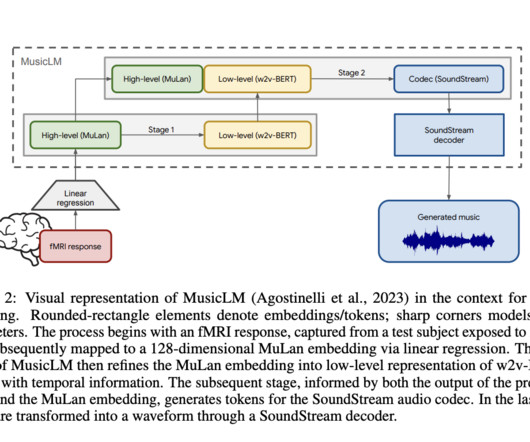
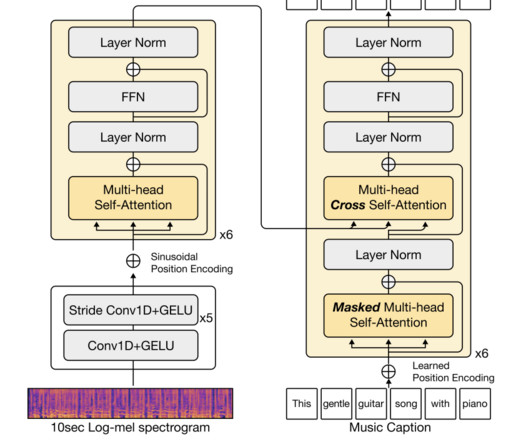
The music-generating model MusicLM consists of audio-derived embeddings named MuLan and w2v-BERT- avg. Out of both embeddings, MuLan tends to have high prediction performance than w2v-BERT-avg in the lateral prefrontal cortex as it captures high-level music information processing in the human brain.
Examples of text-only LLMs include GPT-3 , BERT , RoBERTa , etc. Why is there a need for Multimodal Language Models The text-only LLMs like GPT-3 and BERT have a wide range of applications, such as writing articles, composing emails, and coding.
While domain experts possess the knowledge to interpret these texts accurately, the computational aspects of processing large corpora require expertise in machine learning and naturallanguageprocessing (NLP). All credit for this research goes to the researchers of this project.
The basic difference is that predictive AI outputs predictions and forecasts, while generative AI outputs new content. Here are a few examples across various domains: NaturalLanguageProcessing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., Sign up for more AIresearch updates.
Speaker: Akash Tandon, Co-Founder and Co-author of Advanced Analytics with PySpark | Looppanel and O’Reilly Media Self-Supervised and Unsupervised Learning for Conversational AI and NLP Self-supervised and Unsupervised learning techniques such as Few-shot and Zero-shot learning are changing the shape of AIresearch and product community.
Large Language Models (LLMs) are becoming popular with every new update and new releases. LLMs like BERT, GPT, and PaLM have shown tremendous capabilities in the field of NaturalLanguageProcessing and NaturalLanguage Understanding. Check out the Paper and Reddit Post.
These are advanced machine learning models that are trained to comprehend massive volumes of text data and generate naturallanguage. Examples of LLMs include GPT-3 (Generative Pre-trained Transformer 3) and BERT (Bidirectional Encoder Representations from Transformers).
The previous year saw a significant increase in the amount of work that concentrated on Computer Vision (CV) and NaturalLanguageProcessing (NLP). Because of this, academics worldwide are looking at the potential benefits deep learning and large language models (LLMs) might bring to audio generation.
One of the most popular techniques for speech recognition is naturallanguageprocessing (NLP), which entails training machine learning models on enormous amounts of text data to understand linguistic patterns and structures. It was developed by Facebook AIResearch and released in 2019.
Subsequently, a team of researchers from South Korea has developed a method called LP-MusicCaps (Large language-based Pseudo music caption dataset), creating a music captioning dataset by applying LLMs carefully to tagging datasets. They used the BERT-Score metric to evaluate the diversity of the generated captions. audio clips.
Language Disparity in NaturalLanguageProcessing This digital divide in naturallanguageprocessing (NLP) is an active area of research. 70% of research papers published in a computational linguistics conference only evaluated English.[ Sign up for more AIresearch updates.
On principle, all chatbots work by utilising some form of naturallanguageprocessing (NLP). AIresearchers have been building chatbots for well over sixty years. The challenges of intent detection One of the biggest challenges in building successful intent detection is, of course, naturallanguageprocessing.
Some examples of large language models include GPT (Generative Pre-training Transformer), BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly Optimized BERT Approach). Researchers are developing techniques to make LLM training more efficient.
The well-known large language models such as GPT, DALLE, and BERT perform extraordinary tasks and ease lives. While GPT-3 can complete codes, answer questions like humans, and generate content given just a short naturallanguage prompt, DALLE 2 can create images responding to a simple textual description.
State-of-the-art large language models (LLMs), including BERT, GPT-2, BART, T5, GPT-3, and GPT-4, have been developed as a result of recent advances in machine learning, notably in the area of naturallanguageprocessing (NLP). Pytorch code implementation can be found on GitHub.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content