This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Google has been a frontrunner in AIresearch, contributing significantly to the open-source community with transformative technologies like TensorFlow, BERT, T5, JAX, AlphaFold, and AlphaCode. What is Gemma LLM?
LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). However, LLMs are also very different from other models.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. While newer models like GTE and CDE improved fine-tuning strategies for tasks like retrieval, they rely on outdated backbone architectures inherited from BERT.
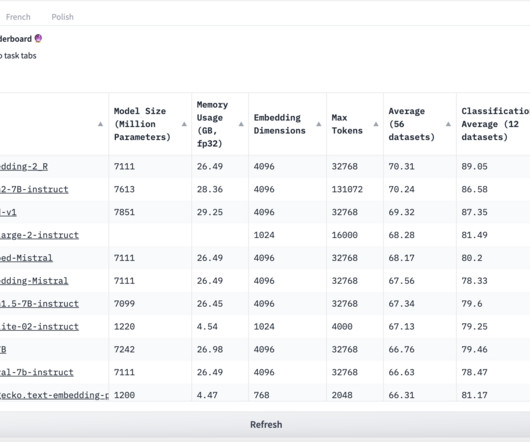
Pre-trained language models, like BERT and GPT, have shown great success in various NLP tasks. The gte-Qwen2-7B-instruct model is trained based on the Qwen2-7B LLM model, which is present in the Qwen2 series models released by the Qwen team recently. This new model uses the same training data and strategies as the earlier gte-Qwen1.5-7B-instruct
As LLMs continue to grow in scale, reaching hundreds of billions to even trillions of parameters, concerns arise about the accessibility of AIresearch, with some fearing it may become confined to industry researchers.
Effective methods allowing for better control, or steerability , of large-scale AI systems are currently in extremely high demand in the world of AIresearch. The quintessential examples for this distinction are: The BERT model, which stands for Bidirectional Encoder Representations from Transformers. Et voilà !
From producing unique and creative content and questioning answers to translating languages and summarizing textual paragraphs, LLMs have been successful in imitating humans. Some well-known LLMs like GPT, BERT, and PaLM have been in the headlines for accurately following instructions and accessing vast amounts of high-quality data.
However, the meteoric rise of large language models (LLMs) like GPT-3 poses a new challenge for the tech titan. Lacking an equally buzzworthy in-house LLM, AWS risks losing ground to rivals rushing their own models to market. And AWS isn’t sitting idle on the LLM front, either. Its capable AIResearch team has […]
Leveraging Advanced AI: Llama2 and Brain Signals The AI component of MindSpeech was powered by the Llama2 Large Language Model (LLM), a sophisticated text generation tool guided by brain signal-generated embeddings. Key metrics such as BLEU-1 and BERT P scores were used to evaluate the accuracy of the AI model.
The well-known large language models such as GPT, DALLE, and BERT perform extraordinary tasks and ease lives. Also, don’t forget to join our 18k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
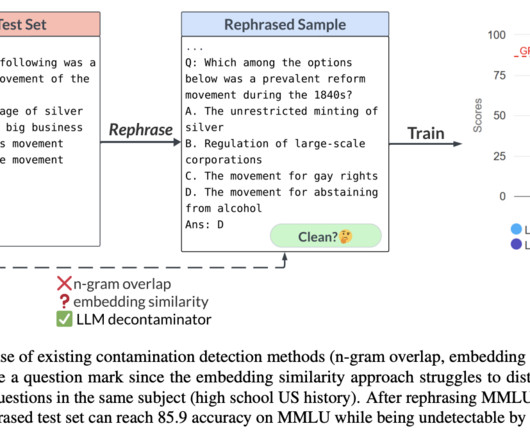
An embedding similarity search looks at the embeddings of previously trained models (like BERT) to discover related and maybe polluted cases. In addition, there is a developing trend in model training that uses synthetic data generated by LLMs (e.g., All credit for this research goes to the researchers of this project.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. Meet ‘Unicron,’ a novel system that Alibaba Group and Nanjing University researchers developed to enhance and streamline the LLM training process.
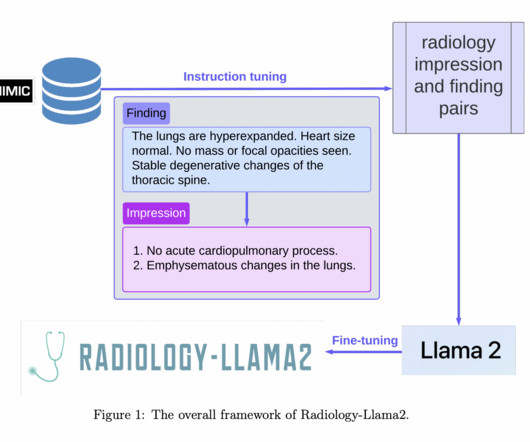
The Radiology-Llama2 LLM, tuned for radiology by instruction tuning to provide radiological impressions from results, fills this gap in the literature. Studies reveal that it outperforms standard LLMs regarding the produced impressions’ coherence, conciseness, and clinical usefulness.
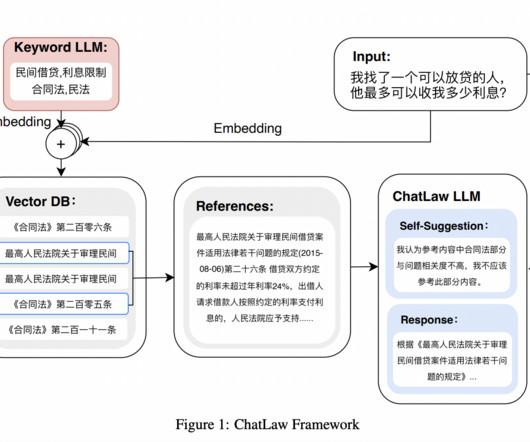
However, early legal LLM (LawGPT) still has a lot of hallucinations and inaccurate results, so this isn’t the case. At first, they understood the demand for a Chinese legal LLM. It is based on the LLM. They also noted that a single general-purpose legal LLM might only function well in this area across some jobs.
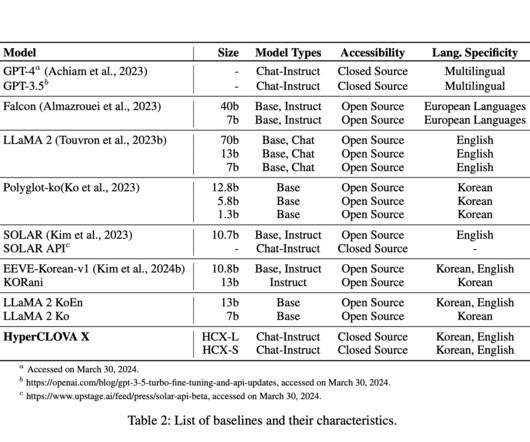
With its distinctive linguistic structure and deep cultural context, Korean has often posed a challenge for conventional English-based LLMs, prompting a shift toward more inclusive and culturally aware AIresearch and development. Codex further explores the integration of code generation within LLMs.
Large Language Models (LLMs) have successfully proven to be the best innovation in the field of Artificial Intelligence. From BERT, PaLM, and GPT to LLaMa DALL-E, these models have shown incredible performance in understanding and generating language for the purpose of imitating humans. Check out the Paper.
Applications of LLMs The chart below summarises the present state of the Large Language Model (LLM) landscape in terms of features, products, and supporting software. Types of LLM Large language models It is not uncommon for large language models to be trained using petabytes or more of text data, making them tens of terabytes in size.
Instead of navigating complex menus or waiting on hold, they can engage in a conversation with a chatbot powered by an LLM. The LLM analyzes the customer’s query, processes the natural language input, and generates a contextual response in real-time. Pythia: Pythia is a vision and language LLM developed by EleutherAI.
The LLM consumes the text data during training and tries to anticipate the following word or series of words depending on the context. Language Translation – LLMs are able to accurately translate text between languages accurately, facilitating successful communication despite language hurdles.
GPT 4, BERT, PaLM, etc. Benchmark is basically a collection of standardized tasks made to test language models’ (LLMs’) abilities. Benchmark is basically a collection of standardized tasks made to test language models’ (LLMs’) abilities.
highlight the risks large language models pose to humanity’s safety as they become bigger and propose mitigation strategies AIresearchers and practitioners can incorporate in the development of such models. The paper was published in 2021 and doesn’t account for the latest state-of-the-art LLMs like GPT-4 and Gemini.
From education and finance to healthcare and media, LLMs are contributing to almost every domain. Famous LLMs like GPT, BERT, PaLM, and LLaMa are revolutionizing the AI industry by imitating humans. The field of Artificial Intelligence is booming with every new release of these models.
NLI models offer significant advantages in terms of efficiency, as they can operate with much smaller parameter counts compared to generative LLMs. For instance, a BERT model with 86 million parameters can perform NLI tasks, while the smallest effective zero-shot generative LLMs require 7-8 billion parameters. Also, Claude 3.5
Large Language Models (LLMs) have proven to be really effective in the fields of Natural Language Processing (NLP) and Natural Language Understanding (NLU). Famous LLMs like GPT, BERT, PaLM, etc., are being used by researchers to provide solutions in every domain ranging from education and social media to finance and healthcare.
Other LLMs, like PaLM, Chinchilla, BERT, etc., have also shown great performances in the domain of AI. It basically adjusts the parameters of an already trained LLM using a smaller and domain-specific dataset. It meaningfully answers questions, summarizes long paragraphs, completes codes and emails, etc.
The field of artificial intelligence (AI) has witnessed remarkable advancements in recent years, and at the heart of it lies the powerful combination of graphics processing units (GPUs) and parallel computing platform. Accelerating LLM Training with GPUs and CUDA. 122 ~/local 1 Verify the installation: ~/local/cuda-12.2/bin/nvcc
With the introduction of Large Language Models like GPT, BERT, and LLaMA, almost every industry, including healthcare, finance, E-commerce, and media, is making use of these models for tasks like Natural Language Understanding (NLU), Natural Language Generation (NLG), question answering, programming, information retrieval and so on.
The well-known large language models such as GPT, DALLE, and BERT perform extraordinary tasks and ease lives. Recently, MLC-LLM has been introduced, which is an open framework that brings LLMs directly into a broad class of platforms like CUDA, Vulkan, and Metal that, too, with GPU acceleration.
In this post, we adopt a pre-trained genomic LLMs for gRNA efficiency prediction. The idea is to treat a computer designed gRNA as a sentence, and fine-tune the LLM to perform sentence-level regression tasks analogous to sentiment analysis. The backbone is a BERT architecture made up of 12 encoding layers.
Most current LLMs are text-only, i.e., they excel only at text-based applications and have limited ability to understand other types of data. Examples of text-only LLMs include GPT-3 , BERT , RoBERTa , etc. The recently released GPT-4 by Open AI is an example of Multimodal LLM.
From producing unique and creative content and questioning answers to translating languages and summarizing textual paragraphs, LLMs have been successful in imitating humans. Some well-known LLMs like GPT, BERT, and PaLM have been in the headlines for accurately following instructions and accessing vast amounts of high-quality data.
If you’d like to skip around, here are the language models we featured: GPT-3 by OpenAI LaMDA by Google PaLM by Google Flamingo by DeepMind BLIP-2 by Salesforce LLaMA by Meta AI GPT-4 by OpenAI If this in-depth educational content is useful for you, you can subscribe to our AIresearch mailing list to be alerted when we release new material.
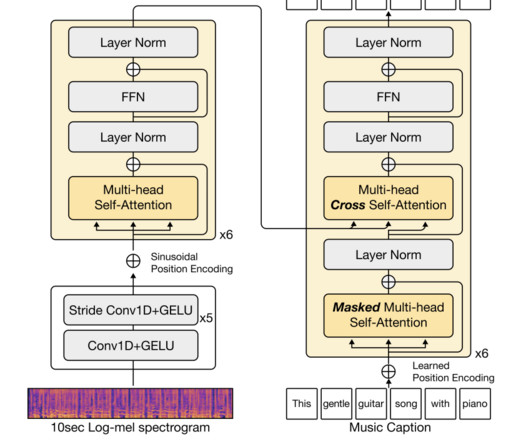
First, they proposed an LLM-based approach to generate a music captioning dataset, LP-MusicCaps. Second, they proposed a systemic evaluation scheme for music captions generated by LLMs. The researchers compared this LLM-based caption generator with template-based methods (tag concatenation, prompt template ) and K2C augmentation.
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. LLMs’ generative abilities make them popular for text synthesis, summarization, machine translation, and more.
Examples of LLMs include GPT-3 (Generative Pre-trained Transformer 3) and BERT (Bidirectional Encoder Representations from Transformers). LLMs are trained on massive amounts of data, often billions of words, to develop a broad understanding of language. All Credit For This Research Goes To the Researchers on This Project.
Some examples of large language models include GPT (Generative Pre-training Transformer), BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly Optimized BERT Approach). Researchers are developing techniques to make LLM training more efficient.
Hidden secret to empower semantic search This is the third article of building LLM-powered AI applications series. From the previous article , we know that in order to provide context to LLM, we need semantic search and complex query to find relevant context (traditional keyword search, full-text search won’t be enough).
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons.
For example, large language models (LLMs) are trained by randomly replacing some of the tokens in training data with a special token, such as [MASK]. Masking in BERT architecture ( illustration by Misha Laskin ) Another common type of generative AI model are diffusion models for image and video generation and editing.
The RLHF process consists of three steps: collecting human feedback in the form of a preference dataset, training a reward model to mimic human preferences, and fine-tuning the LLM using the reward model. Fine-tuning the LLM using the reward model. The reward model is typically also an LLM, often encoder-only, such as BERT.
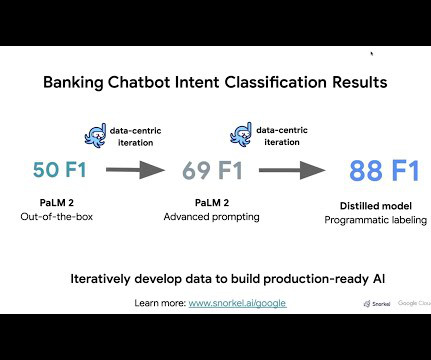
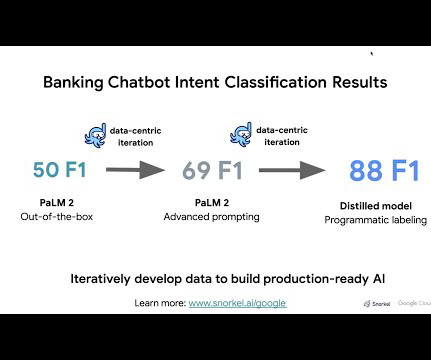
Google has established itself as a dominant force in the realm of AI, consistently pushing the boundaries of AIresearch and innovation. Step 1: Evaluate out-of-the-box PaLM 2 model results As with many AI applications today, the first step is to run and evaluate an LLM over the task of choice. Book a demo today.
Google has established itself as a dominant force in the realm of AI, consistently pushing the boundaries of AIresearch and innovation. Step 1: Evaluate out-of-the-box PaLM 2 model results As with many AI applications today, the first step is to run and evaluate an LLM over the task of choice.
From recognizing objects in images to discerning sentiment in audio clips, the amalgamation of language models with multi-modal learning opens doors to uncharted possibilities in AIresearch, development, and application in industries ranging from healthcare and entertainment to autonomous vehicles and beyond.
For years you’ve been a big leader in applying AI—generally in the NLP and AIresearch communities, but also specifically for finance. Obviously, you were part of an org that was already very sophisticated on the research and operationalization side. You were able to share what you did with the community.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content