This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Source: Canva Introduction In 2018, Google AIresearchers came up with BERT, which revolutionized the NLP domain. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervised learning of language representations, which shares the same architectural backbone as BERT.
Google has been a frontrunner in AIresearch, contributing significantly to the open-source community with transformative technologies like TensorFlow, BERT, T5, JAX, AlphaFold, and AlphaCode.
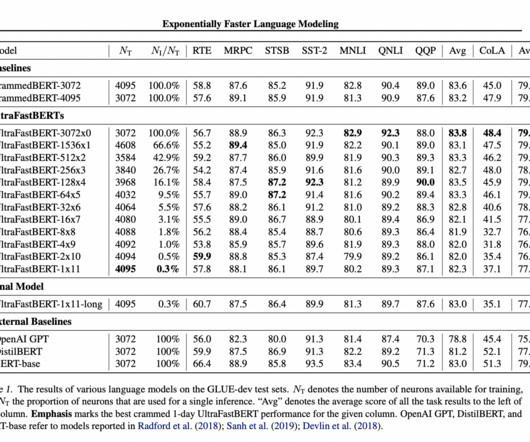
UltraFastBERT achieves comparable performance to BERT-base, using only 0.3% UltraFastBERT-1×11-long matches BERT-base performance with 0.3% In conclusion, UltraFastBERT is a modification of BERT that achieves efficient language modeling while using only a small fraction of its neurons during inference. of its neurons.
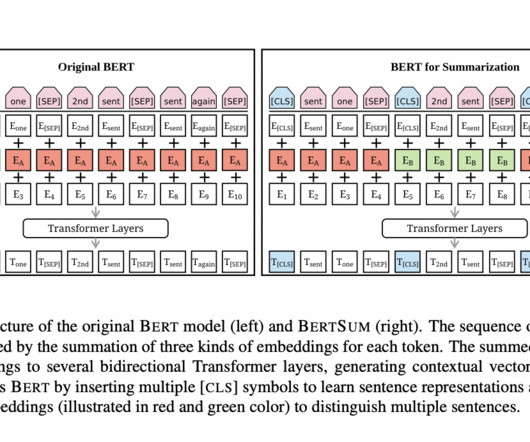
Models like GPT, BERT, and PaLM are getting popular for all the good reasons. The well-known model BERT, which stands for Bidirectional Encoder Representations from Transformers, has a number of amazing applications. Recent research investigates the potential of BERT for text summarization.
Generative AI Techniques: Text Generation (e.g., GPT, BERT) Image Generation (e.g., Step 3: Master Generative AI Concepts and Techniques Dive into Generative AI techniques like GANs, VAEs, and autoregressive models. Explore text generation models like GPT and BERT. Compose music using AI tools like Jukebox.
Regular Updates: New models and capabilities are frequently added, reflecting the latest advancements in AIresearch. AllenNLP Embeddings Strengths: NLP Specialization: AllenNLP provides embeddings like BERT and ELMo that are specifically designed for NLP tasks.
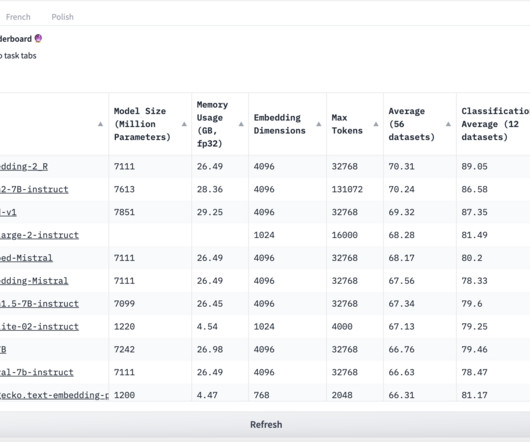
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. While newer models like GTE and CDE improved fine-tuning strategies for tasks like retrieval, they rely on outdated backbone architectures inherited from BERT.
The connection between these artificial neural networks and biological neurons is a key component in advancing AI’s linguistic capabilities. Their approach began with an existing artificial neuron model, S-Bert, known for its language comprehension capabilities.
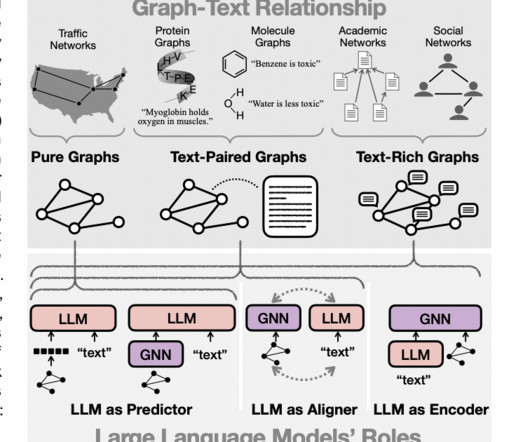
The well-known Large Language Models (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). The post This AIResearch Shares a Comprehensive Overview of Large Language Models (LLMs) on Graphs appeared first on MarkTechPost.
Pre-trained language models, like BERT and GPT, have shown great success in various NLP tasks. Moreover, the gte series models have released two types of models, Encoder-only models which are based on the BERT architecture, and Decode-only models which are based on the LLM architecture. 7B-instruct model.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). OpenAI, an AIresearch company, offers various services and models, including GPT-4, DALL-E, CLIP, and DINOv2. LLMs can understand the complexities of human language better than other models.
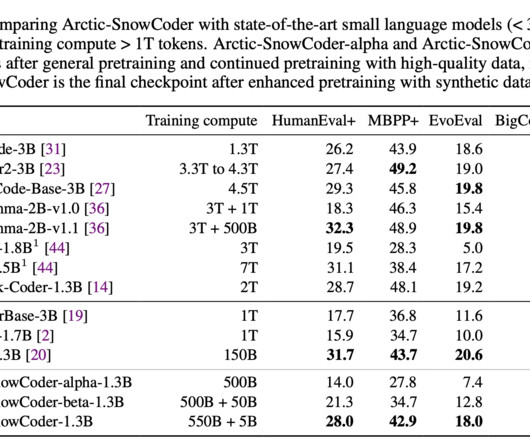
Newer approaches have adopted more sophisticated tools, such as BERT-based annotators, to classify code quality and select data that would more effectively contribute to the model’s success. In the second phase, the research team selected 50 billion tokens from this initial dataset, focusing on high-quality data.
businessinsider.com Robotics for Kids: The Future With AI and Robotics Education Science, technology, engineering, and math (STEM) focused and clever robotic toys help kids understand the science behind circuits and motion and inspire them to take on more challenging projects in the future.
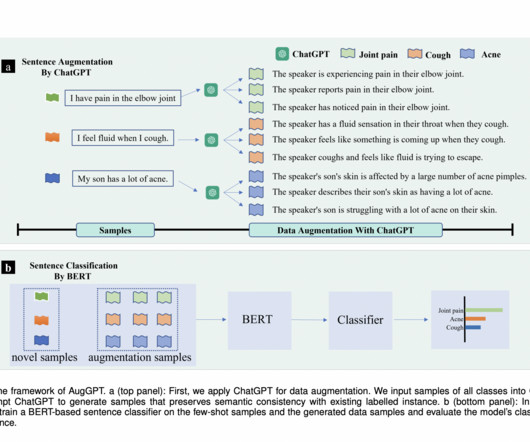
AugGPT’s framework consists of fine-tuning BERT on the base dataset, generating augmented data (Daugn) using ChatGPT, and fine-tuning BERT with the augmented data. The few-shot text classification model is based on BERT, using cross-entropy and contrastive loss functions to classify samples effectively.
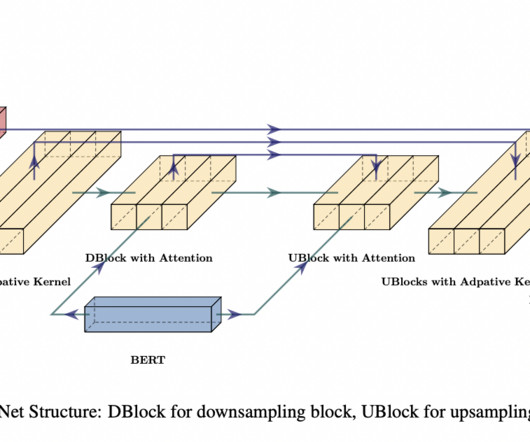
This model consists of two primary modules: A pre-trained BERT model is employed to extract pertinent information from the input text, and A diffusion UNet model processes the output from BERT. It is built upon a pre-trained BERT model. The BERT model takes subword input, and its output is processed by a 1D U-Net structure.
Even other Large Language Models (LLMs) like PaLM, LLaMA, and BERT are being used in applications of various domains involving healthcare, E-commerce, finance, education, etc. Don’t forget to join our 22k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
of nodes with text-features MAG 484,511,504 7,520,311,838 4/4 28,679,392 1,313,781,772 240,955,156 We benchmark two main LM-GNN methods in GraphStorm: pre-trained BERT+GNN, a baseline method that is widely adopted, and fine-tuned BERT+GNN, introduced by GraphStorm developers in 2022. Dataset Num. of nodes Num. of edges Num.
In computer vision, autoregressive pretraining was initially successful, but subsequent developments have shown a sharp paradigm change in favor of BERT-style pretraining. However, because of its greater effectiveness in visual representation learning, subsequent research has come to prefer BERT-style pretraining.
Even other Large Language Models (LLMs) like PaLM, LLaMA, and BERT are being used in applications of various domains involving healthcare, E-commerce, finance, education, etc. Don’t forget to join our 22k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
Regular Updates: New models and capabilities are frequently added, reflecting the latest advancements in AIresearch. AllenNLP Embeddings Strengths: NLP Specialization: AllenNLP provides embeddings like BERT and ELMo that are specifically designed for NLP tasks.
These embeddings were created by integrating brain signals with context input text, allowing the AI to generate coherent text from imagined speech. Key metrics such as BLEU-1 and BERT P scores were used to evaluate the accuracy of the AI model.
In financial and social media datasets, it outperformed established LLMs like BERT, GPT-2, andLLaMA. Temple leverages soft prompting and language modeling techniques to incorporate textual information into time series forecasting. The result? More informed predictions are grounded in both quantitative signals and qualitative context.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
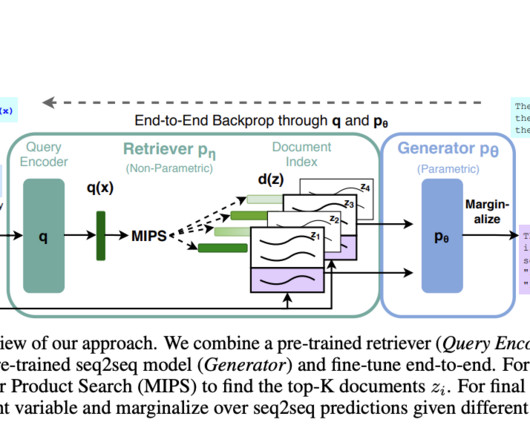
General-purpose architectures like BERT, GPT-2, and BART perform strongly on various NLP tasks. Researchers from Facebook AIResearch, University College London, and New York University introduced Retrieval-Augmented Generation (RAG) models to address these limitations.
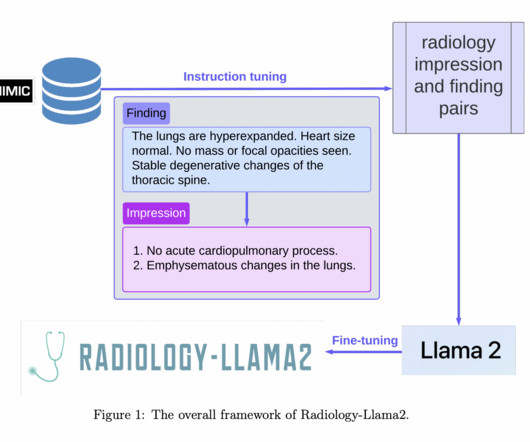
Flexibility and Dynamism: Unlike its BERT-based competitors, radiological-Llama2 is not constrained to a particular input structure, enabling a wider range of inputs and flexibility to various radiological tasks, including complicated reasoning. All Credit For This Research Goes To the Researchers on This Project.
XLNet Reading comprehension, text categorization, sentiment analysis, and other natural language processing (NLP) tasks are just some of the many for which the researchers at Carnegie Mellon University and Google have built a new model dubbed XLNet. It is pre-trained using a generalized autoregressive model.
Sentence-BERT and SimCSE are two methods that have evolved with the introduction of pre-trained language models. These methods are used to fine-tune models like BERT on Natural Language Inference (NLI) datasets in order to learn text embeddings. If you like our work, you will love our newsletter.
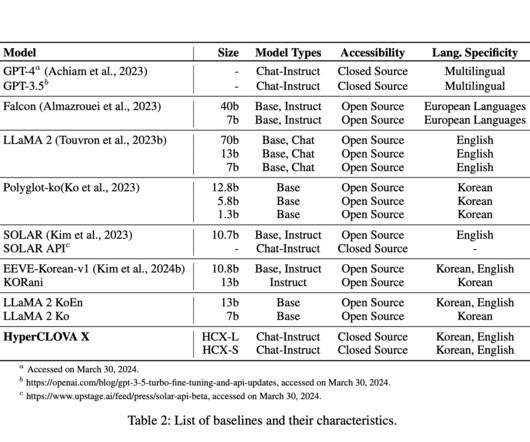
With its distinctive linguistic structure and deep cultural context, Korean has often posed a challenge for conventional English-based LLMs, prompting a shift toward more inclusive and culturally aware AIresearch and development. Codex further explores the integration of code generation within LLMs.
In this section, we will provide an overview of two widely recognized LLMs, BERT and GPT, and introduce other notable models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna. BERT excels in understanding context and generating contextually relevant representations for a given text.
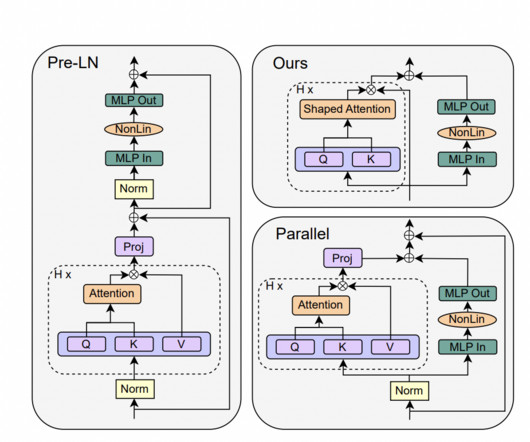
The study conducted experiments on autoregressive decoder-only and BERT encoder-only models to assess the performance of the simplified transformers. All credit for this research goes to the researchers of this project. If you like our work, you will love our newsletter. We are also on Telegram and WhatsApp.
Results for search and recommendation tasks show that the BERT cross-encoder outperforms the bi-encoder, confirming that explicit query and document interaction enhances relevance matching. All credit for this research goes to the researchers of this project.
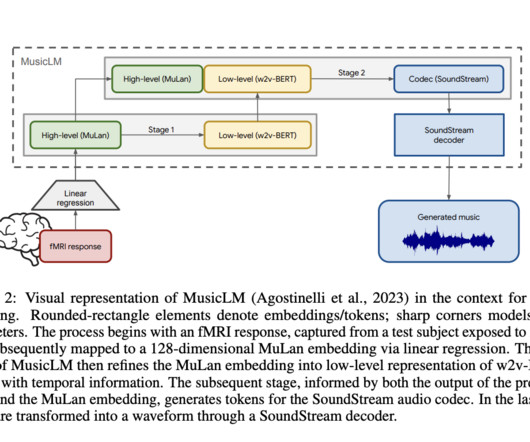
The music-generating model MusicLM consists of audio-derived embeddings named MuLan and w2v-BERT- avg. Out of both embeddings, MuLan tends to have high prediction performance than w2v-BERT-avg in the lateral prefrontal cortex as it captures high-level music information processing in the human brain.
A Brief History of Foundation Models We are in a time where simple methods like neural networks are giving us an explosion of new capabilities, said Ashish Vaswani, an entrepreneur and former senior staff research scientist at Google Brain who led work on the seminal 2017 paper on transformers.
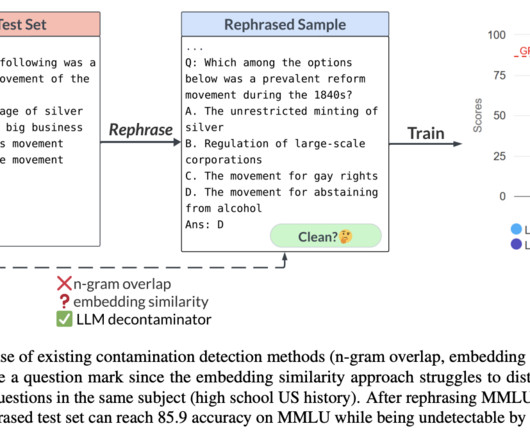
An embedding similarity search looks at the embeddings of previously trained models (like BERT) to discover related and maybe polluted cases. All credit for this research goes to the researchers of this project. However, its precision is somewhat low. If you like our work, you will love our newsletter.
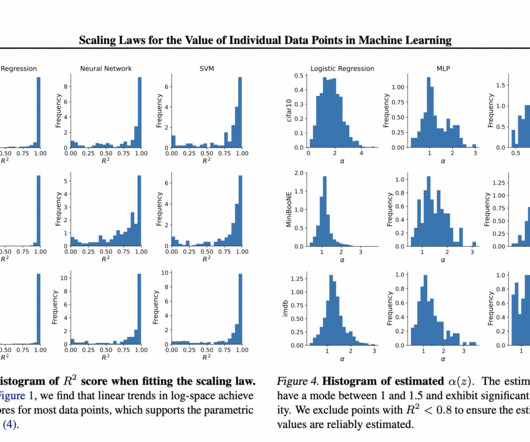
Pre-trained embeddings like frozen ResNet-50 and BERT, are used to speed up training and prevent underfitting for CIFAR-10 and IMDB, respectively. high-quality data in AIresearch. All credit for this research goes to the researchers of this project. Check out the Paper. Also, don’t forget to follow us on Twitter.
Researchers believe they can train a language model because of the competition to construct enormously large models that the power of scale has sparked. The initial BERT model is used for many real-world applications in natural language processing. However, this model already needed a substantial amount of computing to train.
The transformer models like BERT and T5 have recently got popular due to their excellent properties and have utilized the idea of self-supervision in Natural Language Processing tasks. Self-supervised learning is being prominently used in Artificial Intelligence to develop intelligent systems. Check Out The Paper and Github link.
BERT (Bidirectional Encoder Representations from Transformers) Google created the deep learning model known as BERT (Bidirectional Encoder Representations from Transformers) for natural language processing (NLP).
GPT 4, BERT, PaLM, etc. Considering the GLUE and the SuperGLUE benchmark, which were among the first few language understanding benchmarks, models like BERT and GPT-2 were more challenging as language models have been beating these benchmarks, sparking a race between the development of the models and the difficulty of the benchmarks.
Language instructions were encoded using pre-trained BERT embeddings. All Credit For This Research Goes To the Researchers on This Project. Join our AI Channel on Whatsapp. In lifelong robot learning, three vision-language policy networks were employed: RESNET-RNN, RESNET-T, and VIT-T. We are also on WhatsApp.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. The post Alibaba Researchers Unveil Unicron: An AI System Designed for Efficient Self-Healing in Large-Scale Language Model Training appeared first on MarkTechPost.
highlight the risks large language models pose to humanity’s safety as they become bigger and propose mitigation strategies AIresearchers and practitioners can incorporate in the development of such models. AI Compute is expensive. Financial costs erect barriers to entry, limiting who can contribute to AIresearch.
The study employs pre-trained CLIP models in experiments across Playhouse and AndroidEnv, exploring encoder architectures such as Normalizer-Free Networks, Swin, and BERT for language encoding in tasks like Find, Lift, and Pick and Place. All credit for this research goes to the researchers of this project.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content