
Meta AI Researchers Introduce GenBench: A Revolutionary Framework for Advancing Generalization in Natural Language Processing
Marktechpost
OCTOBER 28, 2023
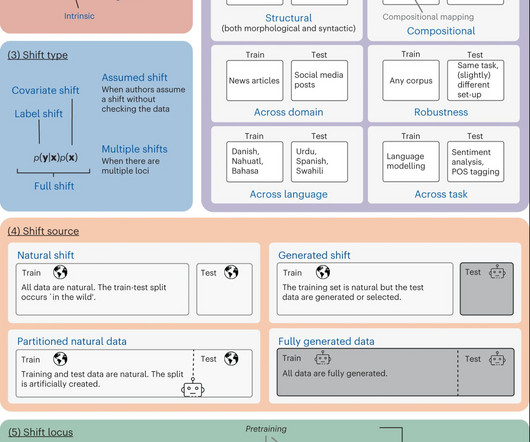
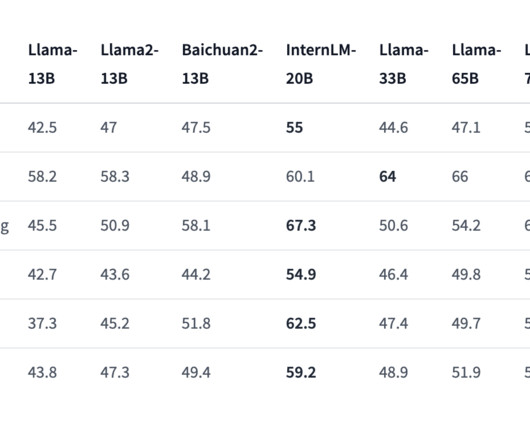
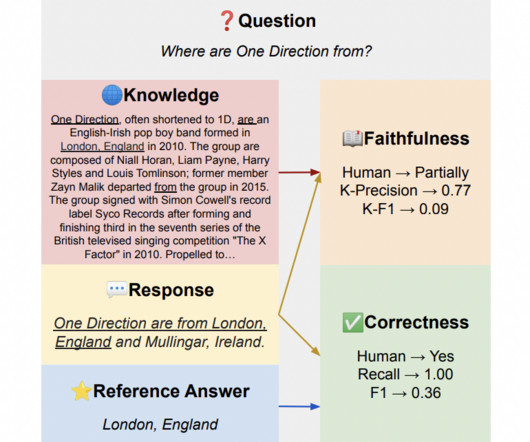
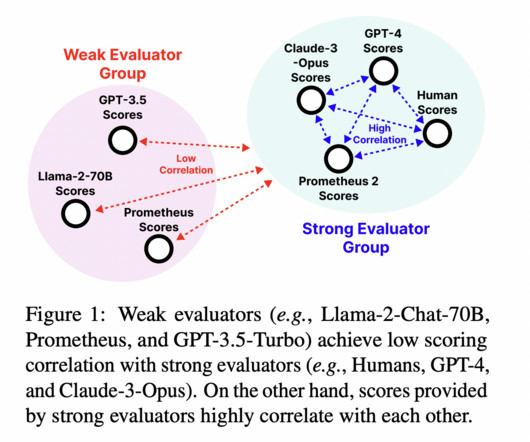
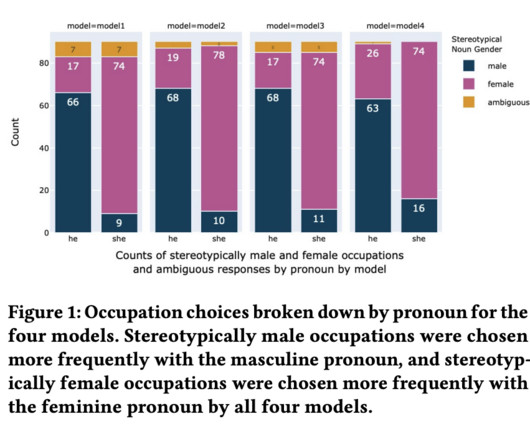
A model’s capacity to generalize or effectively apply its learned knowledge to new contexts is essential to the ongoing success of Natural Language Processing (NLP). To address that, a group of researchers from Meta has proposed a thorough taxonomy to describe and comprehend NLP generalization research.





















Let's personalize your content