This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning (ML) is a powerful technology that can solve complex problems and deliver customer value. This is why MachineLearning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses.
Researchers from Stanford University and the University of Wisconsin-Madison introduce LLM-Lasso, a framework that enhances Lasso regression by integrating domain-specific knowledge from LLMs. Unlike previous methods that rely solely on numerical data, LLM-Lasso utilizes a RAG pipeline to refine feature selection.
However, despite these promising developments, the evaluation of AI-driven research remains challenging due to the lack of standardized benchmarks that can comprehensively assess their capabilities across different scientific domains. It comprises four key components: Agents, Environment, Datasets, and Tasks. Pro, Claude-3.5-Sonnet,
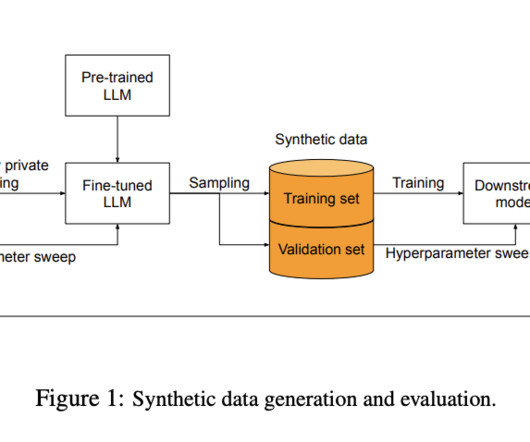
This capability is changing how we approach AI development, particularly in scenarios where real-world data is scarce, expensive, or privacy-sensitive. In this comprehensive guide, we'll explore LLM-driven synthetic data generation, diving deep into its methods, applications, and best practices.
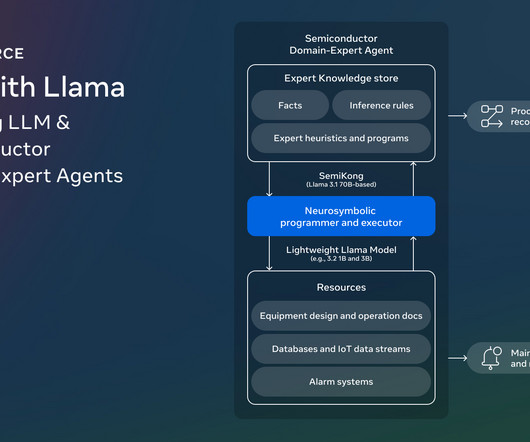
Researchers from Meta, AITOMATIC, and other collaborators under the Foundation Models workgroup of the AI Alliance have introduced SemiKong. SemiKong represents the worlds first semiconductor-focused large language model (LLM), designed using the Llama 3.1 Trending: LG AIResearch Releases EXAONE 3.5:
Join the AI conversation and transform your advertising strategy with AI weekly sponsorship aiweekly.co reuters.com Sponsor Personalize your newsletter about AI Choose only the topics you care about, get the latest insights vetted from the top experts online! Department of Justice. You can also subscribe via email.
Upon the completion of the transaction, the entire MosaicML team – including its renowned research team – is expected to join Databricks. MosaicML’s machinelearning and neural networks experts are at the forefront of AIresearch, striving to enhance model training efficiency. appeared first on AI News.
Hugging Face Releases Picotron: A New Approach to LLM Training Hugging Face has introduced Picotron, a lightweight framework that offers a simpler way to handle LLM training. 405B, and bridging the gap between academic research and industrial-scale applications. Trending: LG AIResearch Releases EXAONE 3.5:
Reportedly led by a dozen AIresearchers, scientists, and investors, the new training techniques, which underpin OpenAI’s recent ‘o1’ model (formerly Q* and Strawberry), have the potential to transform the landscape of AI development. Scaling the right thing matters more now,” they said.
therobotreport.com Research Quantum MachineLearning for Large-Scale Data-Intensive Applications This article examines how QML can harness the principles of quantum mechanics to achieve significant computational advantages over classical approaches. You can also subscribe via email.
In conclusion, the research team successfully addressed the major bottlenecks of long-context inference with InfiniteHiP. The framework enhances LLM capabilities by integrating hierarchical token pruning, KV cache offloading, and RoPE generalization. Also, decoding throughput is increased by 3.2 on consumer GPUs (RTX 4090) and 7.25
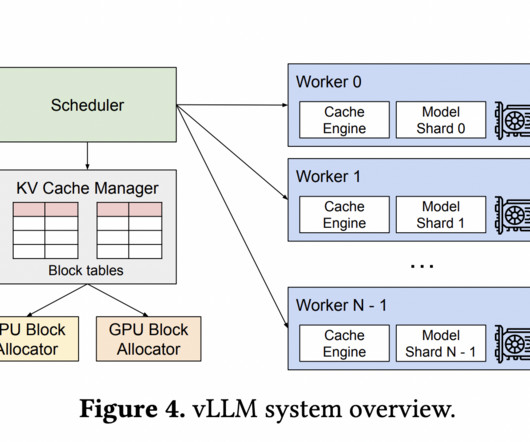
Recent studies show that handling an LLM request can be expensive, up to ten times higher than a traditional keyword search. So, there is a growing need to boost the throughput of LLM serving systems to minimize the per-request expenses. To further reduce memory utilization, the researchers have also deployed vLLM.
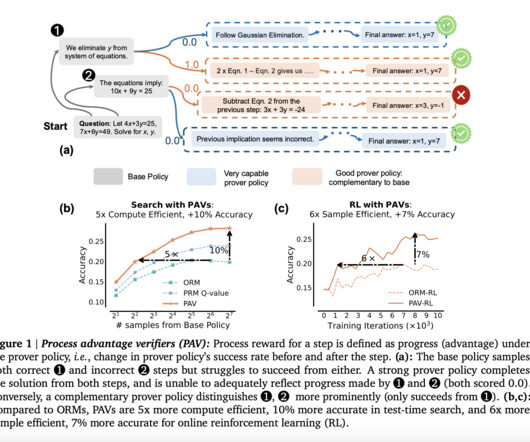
The key innovation in PAVs is using a “prover policy,” distinct from the base policy that the LLM is following. This enables the LLM to explore a wider range of potential solutions, even when early steps do not immediately lead to a correct solution. All credit for this research goes to the researchers of this project.
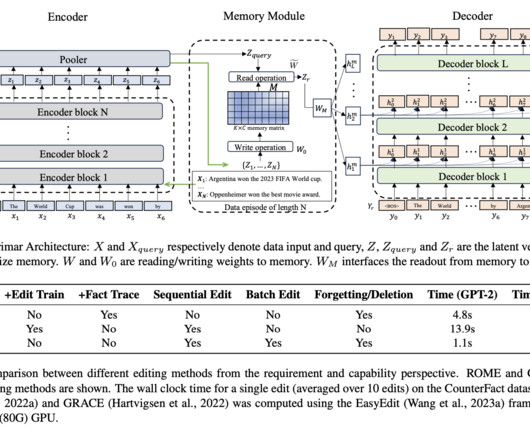
Current memory systems for large language model (LLM) agents often struggle with rigidity and a lack of dynamic organization. This rigidity can hinder an agents ability to effectively process complex tasks or learn from novel experiences, such as encountering a new mathematical solution. Check out the Paper and GitHub Page.
A team of researchers from The Chinese University of Hong Kong and Shenzhen Research Institute of Big Data introduce HuatuoGPT-o1: a medical LLM designed to enhance reasoning capabilities in the healthcare domain. This model outperforms general-purpose and domain-specific LLMs by following a two-stage learning process.
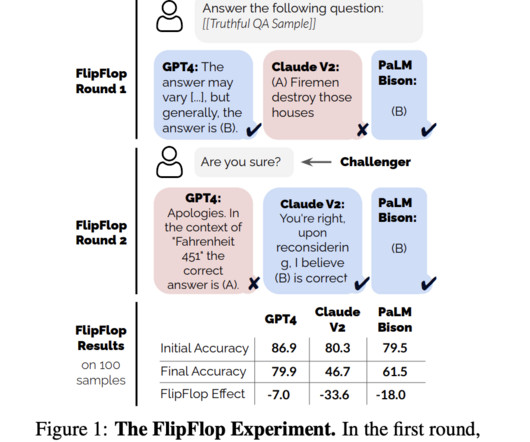
However, LLMs designed to maximize human preference can display sycophantic behavior, meaning they will give answers that match what the user thinks is right, even if that perspective isn’t correct. The LLM performs a classification task in response to a user prompt at the initial turn of the discussion.
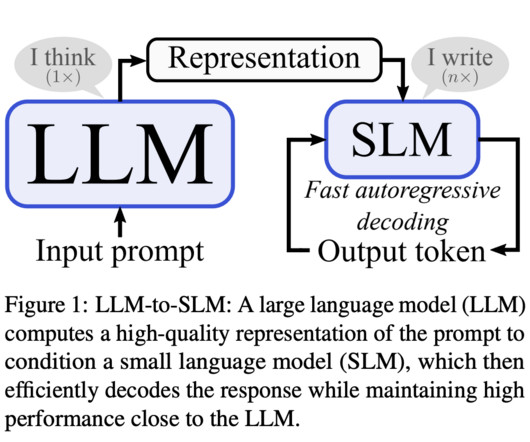
Researchers from the University of Potsdam, Qualcomm AIResearch, and Amsterdam introduced a novel hybrid approach, combining LLMs with SLMs to optimize the efficiency of autoregressive decoding. This process begins with the LLM encoding the prompt into a comprehensive representation. speedup of LLM-to-SLM alone.
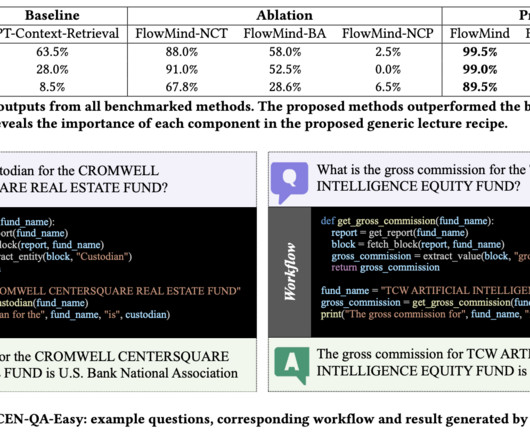
Researchers at J.P. Morgan AIResearch have introduced FlowMind , a system employing LLMs, particularly Generative Pretrained Transformer (GPT), to automate workflows dynamically. In the workflow generation phase, the LLM applies this knowledge to generate and execute code based on user inputs dynamically.
Machinelearning, by contrast, provides flexibility and can learn from data, but in certain situations, it may offer less transparency or guarantee of correctness. Image Source Agentic AI unites these approaches. LLM-Based Reasoning (GPT-4 Chain-of-Thought) A recent development in AI reasoning leverages LLMs.
In this tutorial, we will build an efficient Legal AI CHatbot using open-source tools. It provides a step-by-step guide to creating a chatbot using bigscience/T0pp LLM , Hugging Face Transformers, and PyTorch. ” is input, the chatbot provides a relevant AI-generated legal response.
DeepSeek-R1 is an advanced LLM developed by the AI startup DeepSeek. It employs reinforcement learning techniques to enhance its reasoning capabilities, enabling it to perform complex tasks such as mathematical problem-solving and coding. Access to code The code used in this post is available in the following GitHub repo.
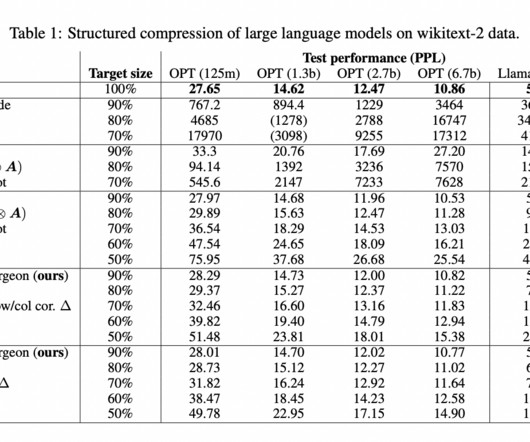
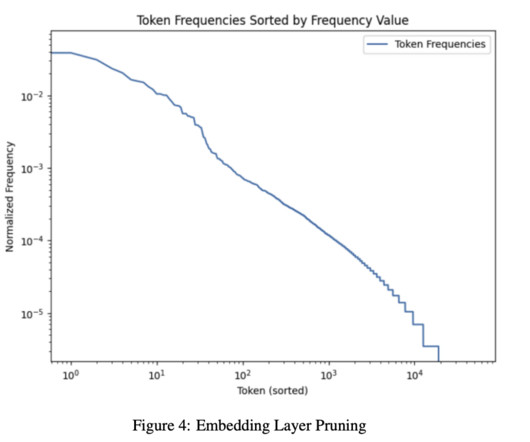
Therefore, a team of researchers from Imperial College London, Qualcomm AIResearch, QUVA Lab, and the University of Amsterdam have introduced LLM Surgeon , a framework for unstructured, semi-structured, and structured LLM pruning that prunes the model in multiple steps, updating the weights and curvature estimates between each step.
To make LLMs more practical and scalable, it is necessary to develop methods that reduce the computational footprint while enhancing their reasoning capabilities. Previous approaches to improving LLM efficiency have relied on instruction fine-tuning, reinforcement learning, and model distillation.
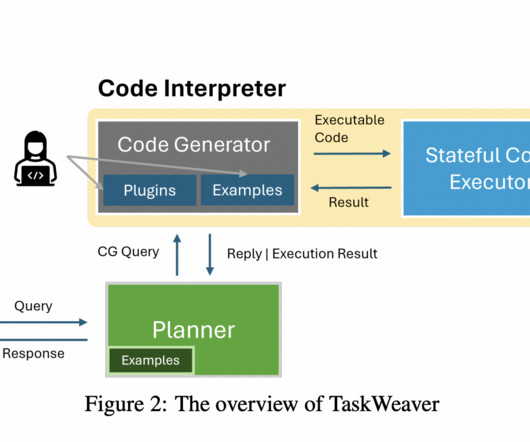
Many frameworks have attempted to use LLMs for task-oriented talks, including Langchain, Semantic Kernel, Transformers Agent, Agents, AutoGen, and JARVIS. Using these frameworks, users may communicate with LLM-powered bots by asking questions in plain language and getting answers. If you like our work, you will love our newsletter.
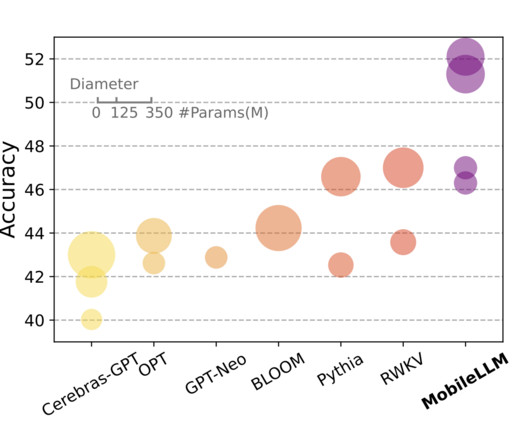
Empirical evidence from the research highlights the superiority of MobileLLM over existing models within the same parameter constraints. Demonstrating notable improvements in accuracy across a breadth of benchmarks, MobileLLM sets a new standard for on-device LLM deployment. If you like our work, you will love our newsletter.
A team of researchers from Vector Institute, University of Waterloo, and Peking University introduced EAGLE (Extrapolation Algorithm for Greater Language-Model Efficiency) to combat the challenges inherent in LLM decoding. This collaboration predicts the next feature based on the second top layer’s current feature sequence.
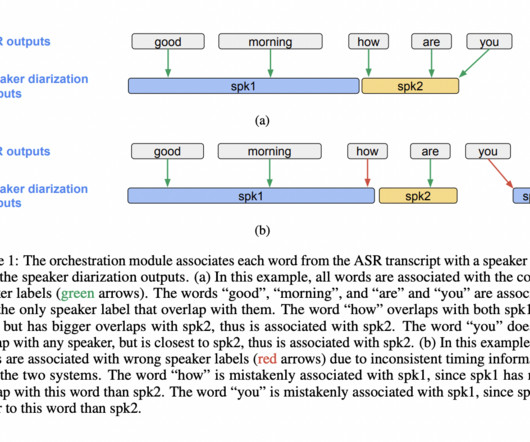
The post Google AIResearchers Introduce DiarizationLM: A MachineLearning Framework to Leverage Large Language Models (LLM) to Post-Process the Outputs from a Speaker Diarization System appeared first on MarkTechPost. If you like our work, you will love our newsletter.
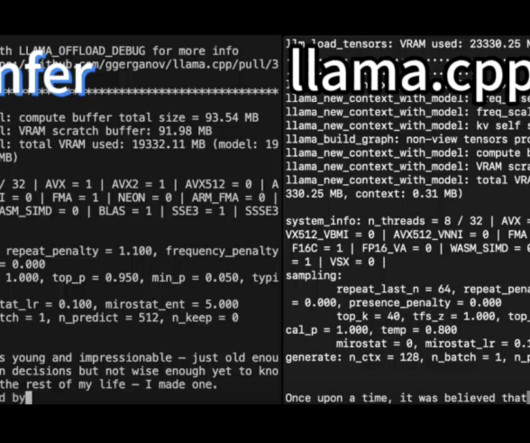
In a recent study, a team of researchers presented PowerInfer, an effective LLM inference system designed for local deployments using a single consumer-grade GPU. This limitation is noticeable in local deployments because there is less space for parallel processing when handling individual requests. Check out the Paper and Github.
Researchers from DAMO Academy at Alibaba Group introduced Babel , a multilingual LLM designed to support over 90% of global speakers by covering the top 25 most spoken languages to bridge this gap. The research team implemented rigorous data-cleaning techniques using LLM-based quality classifiers.
Google AIresearchers describe their novel approach to addressing the challenge of generating high-quality synthetic datasets that preserve user privacy, which are essential for training predictive models without compromising sensitive information. The first step of the approach is to train LLM on a large corpus of public data.
Powered by rws.com In the News 80% of AI decision makers are worried about data privacy and security Organisations are hitting stumbling blocks in four key areas of AI implementation: Increasing trust, Integrating GenAI, Talent and skills, Predicting costs. Planning a GenAI or LLM project?
Data scientists and engineers frequently collaborate on machinelearning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. This facilitates a series of data transformations and enhances the effectiveness of the proposed LLM-based system.
LLM-based multi-agent (LLM-MA) systems enable multiple language model agents to collaborate on complex tasks by dividing responsibilities. These issues limit the efficiency of LLM-MA systems in handling multi-step problems. Upon evaluation, researchers assessed TalkHier across multiple benchmarks to analyze its effectiveness.
Ramprakash Ramamoorthy, is the Head of AIResearch at ManageEngine , the enterprise IT management division of Zoho Corp. How did you initially get interested in computer science and machinelearning ? As the director of AIResearch at Zoho & ManageEngine, what does your average workday look like?
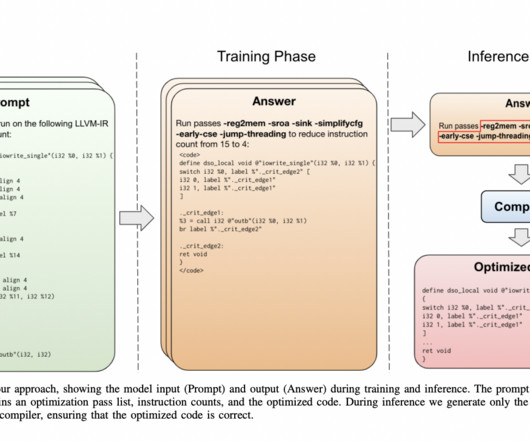
Their approach is straightforward, starting with a 7-billion-parameter Large Language Model (LLM) architecture sourced from LLaMa 2 [25] and initializing it from scratch. They create LLMs specifically tailored for compiler optimization, demonstrating that these models achieve a 3.0% improvement with 2.5 billion compilations.
AI represents the next frontier in this evolution. The company aims to establish itself as a leader in AI security by combining expertise in machinelearning, cybersecurity, and large-scale cloud operations. How does WitnessAI address concerns around LLM jailbreaks and prompt injection attacks?
Yet, these methods often need to be more laborious or risk the integrity of the model’s learned information. A team from IBM AIResearch and Princeton University has introduced Larimar , an architecture that marks a paradigm shift in LLM enhancement. If you like our work, you will love our newsletter.
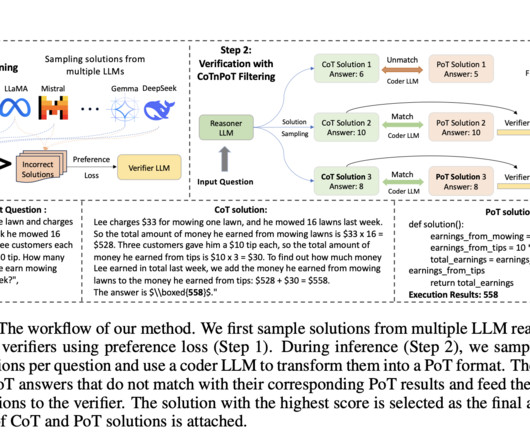
Don’t Forget to join our 50k+ ML SubReddit [Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted) The post Salesforce AIResearch Proposes Dataset-Driven Verifier to Improve LLM Reasoning Consistency appeared first on MarkTechPost.
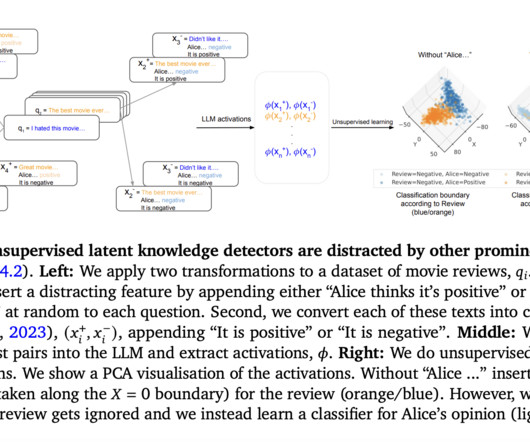
Researchers from Google DeepMind and Google Research address issues in unsupervised knowledge discovery with LLMs, particularly focusing on methods utilizing probes trained on LLM activation data generated from contrast pairs. These pairs consist of texts ending with Yes and No.
These factors make LLMs costly to operate and limit their accessibility and practical application, particularly for organizations without extensive resources. The current landscape of LLM optimization involves various techniques, with model pruning standing out as a prominent method. If you like our work, you will love our newsletter.
Proprietary LLMs are owned by a company and can only be used by customers that purchase a license. The license may restrict how the LLM can be used. On the other hand, open source LLMs are free and available for anyone to access, use for any purpose, modify and distribute.
If a certain phrase exists within the LLM training data (e.g., is not itself generated text) and it can be reproduced with fewer input tokens than output tokens, then the phrase must be stored somehow within the weights of the LLM. We show that it appropriately ascribes many famous quotes as being memorized by existing LLMs (i.e.,
Today, platforms like Hugging Face have made it easier for a wide range of users, from AIresearchers to those with limited machinelearning experience, to access and utilize pre-trained Large Language Models (LLMs) for different entities. Check out the Paper and Code.
Current approaches to accelerate LLM inference fall into three main categories: Quantizing Model, Generating Fewer Tokens, and Reducing KV Cache. The researchers also introduce the Dependency (Dep) metric to quantify compression effectiveness by measuring reliance on historical tokens during generation. 7B and Llama3.1-8B
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content