This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Artificial intelligence has made remarkable strides in recent years, with largelanguagemodels (LLMs) leading in natural language understanding, reasoning, and creative expression. Yet, despite their capabilities, these models still depend entirely on external feedback to improve.
Renowned for its ability to efficiently tackle complex reasoning tasks, R1 has attracted significant attention from the AIresearch community, Silicon Valley , Wall Street , and the media. Yet, beneath its impressive capabilities lies a concerning trend that could redefine the future of AI.
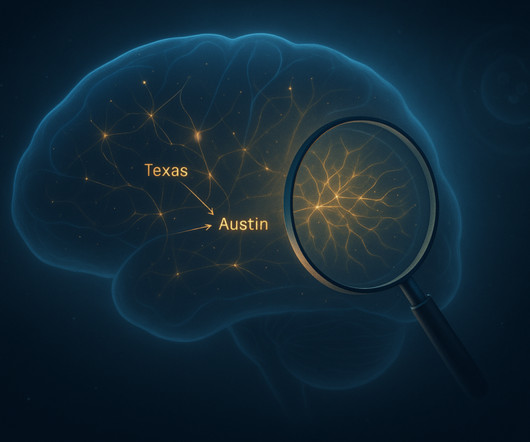
Largelanguagemodels (LLMs) like Claude have changed the way we use technology. But despite their amazing abilities, these models are still a mystery in many ways. They created a basic “map” of how Claude processes information. They power tools like chatbots, help write essays and even create poetry.
The field of artificial intelligence is evolving at a breathtaking pace, with largelanguagemodels (LLMs) leading the charge in natural language processing and understanding. As we navigate this, a new generation of LLMs has emerged, each pushing the boundaries of what's possible in AI. Visit GPT-4o → 3.
We are going to explore these and other essential questions from the ground up , without assuming prior technical knowledge in AI and machine learning. The problem of how to mitigate the risks and misuse of these AImodels has therefore become a primary concern for all companies offering access to largelanguagemodels as online services.
Addressing unexpected delays and complications in the development of larger, more powerful languagemodels, these fresh techniques focus on human-like behaviour to teach algorithms to ‘think. First, there is the cost of training largemodels, often running into tens of millions of dollars.
Largelanguagemodels (LLMs) are foundation models that use artificial intelligence (AI), deep learning and massive data sets, including websites, articles and books, to generate text, translate between languages and write many types of content. The license may restrict how the LLM can be used.
LargeLanguageModels (LLMs) are currently one of the most discussed topics in mainstream AI. These models are AI algorithms that utilize deep learning techniques and vast amounts of training data to understand, summarize, predict, and generate a wide range of content, including text, audio, images, videos, and more.
Largelanguagemodels struggle to process and reason over lengthy, complex texts without losing essential context. Traditional models often suffer from context loss, inefficient handling of long-range dependencies, and difficulties aligning with human preferences, affecting the accuracy and efficiency of their responses.
Since OpenAI unveiled ChatGPT in late 2022, the role of foundational largelanguagemodels (LLMs) has become increasingly prominent in artificial intelligence (AI), particularly in natural language processing (NLP). It offers a more hands-on and communal way for AI to pick up new skills.
While no AI today is definitively conscious, some researchers believe that advanced neural networks , neuromorphic computing , deep reinforcement learning (DRL), and largelanguagemodels (LLMs) could lead to AI systems that at least simulate self-awareness.
LargeLanguageModels (LLMs) have advanced significantly, but a key limitation remains their inability to process long-context sequences effectively. While models like GPT-4o and LLaMA3.1 Longer context windows are essential for AI applications such as multi-turn conversations, document analysis, and long-form reasoning.
Prior research has explored strategies to integrate LLMs into feature selection, including fine-tuning models on task descriptions and feature names, prompting-based selection methods, and direct filtering based on test scores. A built-in validation step ensures reliability, mitigating potential LLM inaccuracies.
This method has been celebrated for helping largelanguagemodels (LLMs) stay factual and reduce hallucinations by grounding their responses in real data. Intuitively, one might think that the more documents an AI retrieves, the better informed its answer will be. Source: Levy et al. Why is this such a surprise?
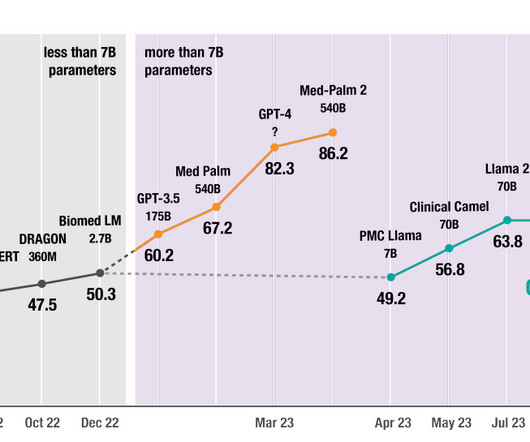
The integration and application of largelanguagemodels (LLMs) in medicine and healthcare has been a topic of significant interest and development. The research discussed above delves into the intricacies of enhancing LargeLanguageModels (LLMs) for medical applications.
NotebookLM is Google's AIresearch and note-taking tool that understands source materials. While most AI tools draw from their general training data, NotebookLM focuses on understanding and working with your documents. It's like having a research assistant who's read all your materials thoroughly. What is NotebookLM?
The well-known LargeLanguageModels (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). If you like our work, you will love our newsletter.
.” The tranche, co-led by General Catalyst and Andreessen Horowitz, is a big vote of confidence in Hippocratic’s technology, a text-generating model tuned specifically for healthcare applications. ” AI in healthcare, historically, has been met with mixed success.
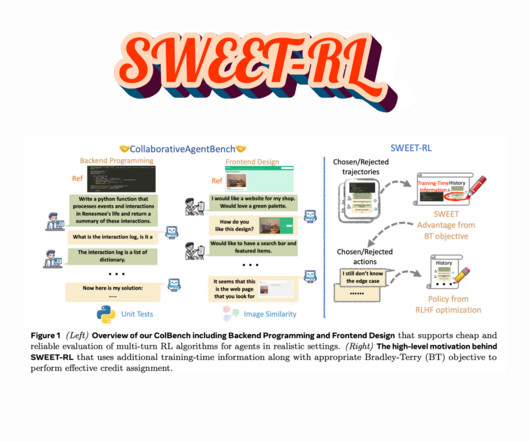
Largelanguagemodels (LLMs) are rapidly transforming into autonomous agents capable of performing complex tasks that require reasoning, decision-making, and adaptability. FAIR at Meta and UC Berkeley researchers proposed a new reinforcement learning method called SWEET-RL (Step-WisE Evaluation from Training-time Information).
Their aptitude to process and generate language has far-reaching consequences in multiple fields, from automated chatbots to advanced data analysis. Grasping the internal workings of these models is critical to improving their efficacy and aligning them with human values and ethics. If you like our work, you will love our newsletter.
While Document AI (DocAI) has made significant strides in areas such as question answering, categorization, and extraction, real-world applications continue to face persistent hurdles related to accuracy, reliability, contextual understanding, and generalization to new domains. If you like our work, you will love our newsletter.
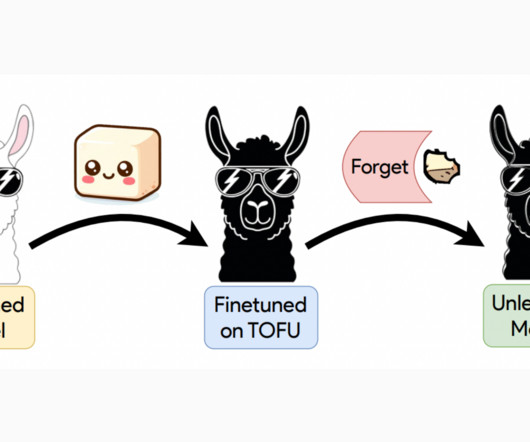
LLMs are trained on vast amounts of web data, which can lead to unintentional memorization and reproduction of sensitive or private information. This approach involves modifying models after training to deliberately ‘forget’ certain elements of their training data. Check out the Paper and Project.
A standout feature of Bridgetowns AI suite is its voice botssophisticated AI agents trained to recruit and interview industry experts. By collecting primary datadirect insights from seasoned professionalsthese agents provide businesses with proprietary intelligence that goes beyond publicly available information.
Training largelanguagemodels (LLMs) has become out of reach for most organizations. With costs running into millions and compute requirements that would make a supercomputer sweat, AI development has remained locked behind the doors of tech giants.
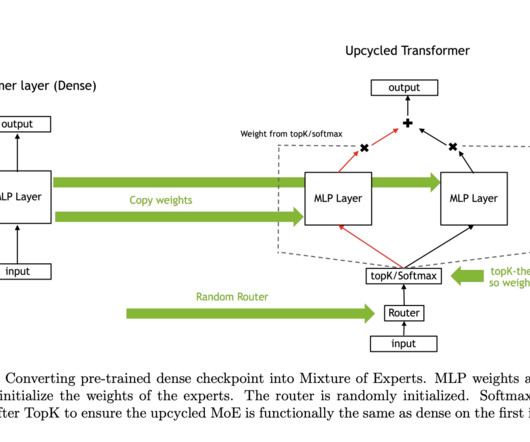
One of the key findings was that the softmax-then-topK routing consistently outperformed other approaches, such as topK-then-softmax, which is often used in dense models. This new approach allowed the upcycled MoE models to better utilize the information contained in the expert layers, leading to improved performance.
In the suit, the Times alleges that OpenAI committed copyright infringement when it ingested thousands of articles to train its largelanguagemodels. Balaji said he initially bought OpenAI’s argument that if the information was posted online and freely available, scraping constituted fair use.
Our results indicate that, for specialized healthcare tasks like answering clinical questions or summarizing medical research, these smaller models offer both efficiency and high relevance, positioning them as an effective alternative to larger counterparts within a RAG setup. What is Retrieval-Augmented Generation?
This issue is especially common in largelanguagemodels (LLMs), the neural networks that drive these AI tools. They produce sentences that flow well and seem human, but without truly “understanding” the information they’re presenting. Today, AIresearchers face this same kind of limitation.
In recent years, largelanguagemodels (LLMs) have made significant progress in generating human-like text, translating languages, and answering complex queries. In this article, well explore the transition from LLMs to LCMs and how these new models are transforming the way AI understands and generates language.
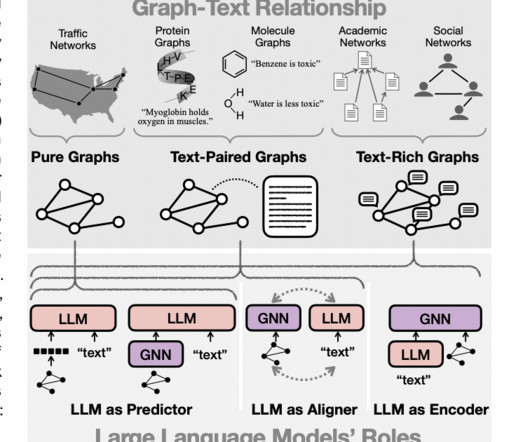
In the evolving landscape of artificial intelligence and machine learning, the integration of visual perception with language processing has become a frontier of innovation. This integration is epitomized in the development of Multimodal LargeLanguageModels (MLLMs), which have shown remarkable prowess in a range of vision-language tasks.
Largelanguagemodels (LLMs) have demonstrated remarkable performance across various tasks, with reasoning capabilities being a crucial aspect of their development. The last layers’ intrinsic dimension proves highly informative about response correctness across model sizes.
Largelanguagemodels (LLMs) like OpenAIs o3 , Googles Gemini 2.0 , and DeepSeeks R1 have shown remarkable progress in tackling complex problems, generating human-like text, and even writing code with precision. But do these models actually reason , or are they just exceptionally good at planning ?
The development of multimodal largelanguagemodels (MLLMs) represents a significant leap forward. These advanced systems, which integrate language and visual processing, have broad applications, from image captioning to visible question answering. If you like our work, you will love our newsletter.
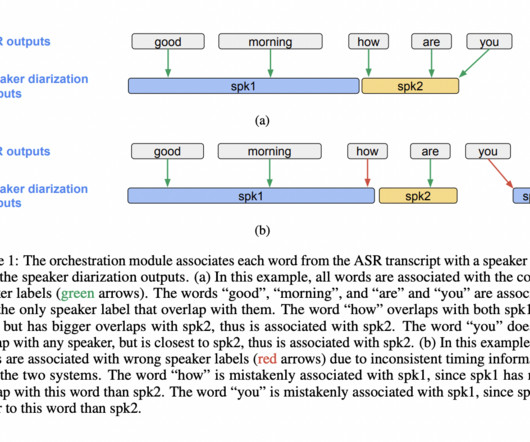
[link] Enter ‘DiarizationLM,’ a groundbreaking framework developed by researchers at Google that promises to revolutionize speaker diarization by harnessing the power of largelanguagemodels (LLMs). The inner workings of DiarizationLM are as intriguing as its premise.
Largelanguagemodels think in ways that dont look very human. Their outputs are formed from billions of mathematical signals bouncing through layers of neural networks powered by computers of unprecedented power and speed, and most of that activity remains invisible or inscrutable to AIresearchers.
Its not a new feature to the AI worldbut the companys approach stands as one the most thoughtful to date. Much like Perplexity , Anthropics Claude works relevant information from the web into a conversational answer, and includes clickable source citations. but let me search for more precise information since this could have changed.
Largelanguagemodels, like GPT-3, learn from vast data, including examples of correct and incorrect language usage. These models are trained on diverse datasets containing a wide range of text from the internet, books, articles, and more. It understands grammar, syntax, semantics, and even nuances of language use.
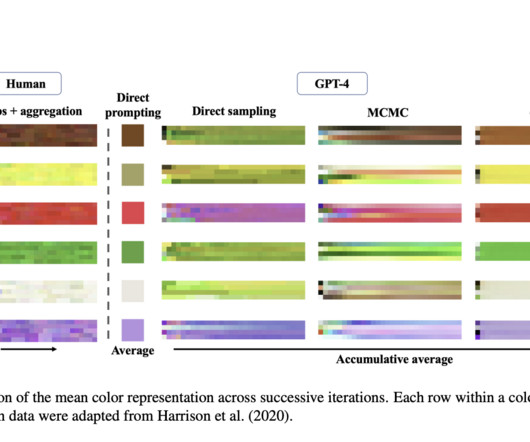
A groundbreaking study unveils an approach to peering into the minds of LargeLanguageModels (LLMs), particularly focusing on GPT-4’s understanding of color. The challenge of interpreting AImodels lies in their complexity and the opaque nature of their internal workings.
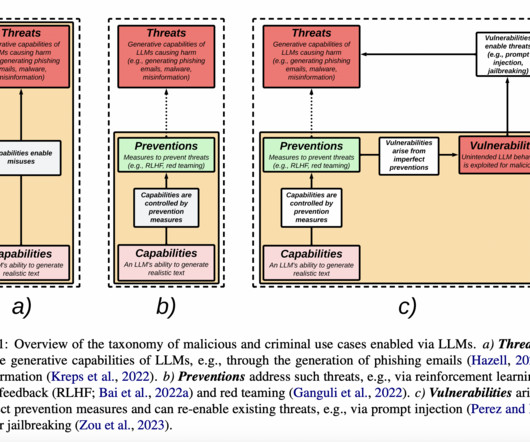
Therefore, researchers from Tilburg University and University College London survey the state of safety and security research on LLMs and provide a taxonomy of existing techniques by classifying them according to dangers, preventative measures, and security holes. If you like our work, you will love our newsletter.
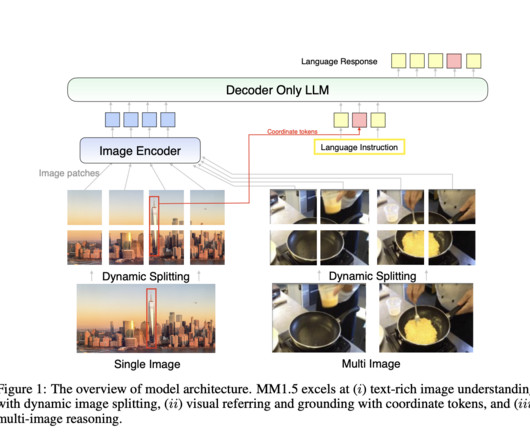
Multimodal largelanguagemodels (MLLMs) represent a cutting-edge area in artificial intelligence, combining diverse data modalities like text, images, and even video to build a unified understanding across domains. is poised to address key challenges in multimodal AI. The post Apple AIResearch Introduces MM1.5:
The recent advancements in Artificial Intelligence have enabled the development of LargeLanguageModels (LLMs) with a significantly large number of parameters, with some of them reaching into billions (for example, LLaMA-2 that comes in sizes of 7B, 13B, and even 70B parameters).
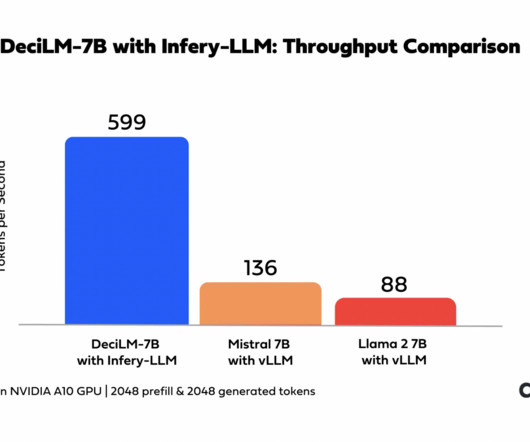
The advancement of technology has ushered in a digital age where languagemodels play an increasingly important role in information processing, communication, and problem-solving. Recently, Deci has introduced DeciLM-7B, an innovative model with high precision and speed available in the 7-billion-parameter class.
Artificial Intelligence (AI) is evolving at an unprecedented pace, with large-scale models reaching new levels of intelligence and capability. From early neural networks to todays advanced architectures like GPT-4 , LLaMA , and other LargeLanguageModels (LLMs) , AI is transforming our interaction with technology.
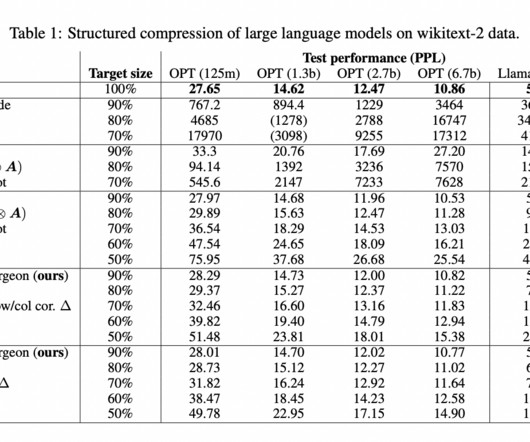
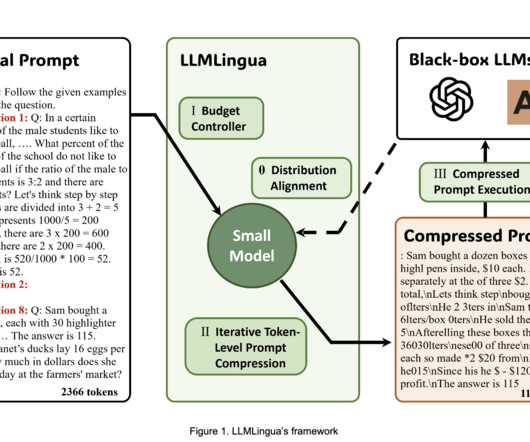
LargeLanguageModels (LLMs), due to their strong generalization and reasoning powers, have significantly uplifted the Artificial Intelligence (AI) community. This function guarantees recoverability and retains crucial information even after translation, adding to LLMLingua’s overall impressiveness.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content