This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Top 10 AIResearch Papers of 2024: Key Takeaways and How You Can Apply Them Photo by Maxim Tolchinskiy on Unsplash As the curtains draw on 2024, its time to reflect on the innovations that have defined the year in AI. So, grab a coffee (or a milkshake, if youre like me) and lets explore the top AIresearch papers of 2024.
Researchers from the University College London, University of WisconsinMadison, University of Oxford, Meta, and other institutes have introduced a new framework and benchmark for evaluating and developing LLM agents in AIresearch. Tasks include evaluation scripts and configurations for diverse ML challenges. Pro, Claude-3.5-Sonnet,
Largelanguagemodels (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing natural language processing abilities. The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computervision and other modalities.
The development of multimodal largelanguagemodels (MLLMs) represents a significant leap forward. These advanced systems, which integrate language and visual processing, have broad applications, from image captioning to visible question answering. If you like our work, you will love our newsletter.
Voxel51, a prominent innovator in data-centric computervision and machine learning software, has recently introduced a remarkable breakthrough in the field of computervision with the launch of VoxelGPT. VoxelGPT offers several key capabilities that streamline computervision workflows, saving time and resources: 1.
In the evolving landscape of artificial intelligence and machine learning, the integration of visual perception with language processing has become a frontier of innovation. This integration is epitomized in the development of Multimodal LargeLanguageModels (MLLMs), which have shown remarkable prowess in a range of vision-language tasks.
With the constant advancements in the field of Artificial Intelligence, its subfields, including Natural Language Processing, Natural Language Generation, Natural Language Understanding, and ComputerVision, are getting significantly popular. If you like our work, you will love our newsletter.
LargeLanguageModels (LLMs), due to their strong generalization and reasoning powers, have significantly uplifted the Artificial Intelligence (AI) community. If you like our work, you will love our newsletter.
Multimodal largelanguagemodels (MLLMs) represent a cutting-edge area in artificial intelligence, combining diverse data modalities like text, images, and even video to build a unified understanding across domains. is poised to address key challenges in multimodal AI. The post Apple AIResearch Introduces MM1.5:
The popularity of NLP encourages a complementary strategy in computervision. Unique obstacles arise from the necessity for broad perceptual capacities in universal representation for various vision-related activities. Their method achieves a universal representation and has wide-ranging use in many visual tasks.
Artificial Intelligence (AI) is evolving at an unprecedented pace, with large-scale models reaching new levels of intelligence and capability. From early neural networks to todays advanced architectures like GPT-4 , LLaMA , and other LargeLanguageModels (LLMs) , AI is transforming our interaction with technology.
Recently, LargeLanguageModels (LLMs) have played a crucial role in the field of natural language understanding, showcasing remarkable capabilities in generalizing across a wide range of tasks, including zero-shot and few-shot scenarios. If you like our work, you will love our newsletter.
While LargeLanguageModels (LLMs) like ChatGPT and GPT-4 have demonstrated better performance across several benchmarks, open-source projects like MMLU and OpenLLMBoard have quickly progressed in catching up across multiple applications and benchmarks. If you like our work, you will love our newsletter.
The Microsoft AI London outpost will focus on advancing state-of-the-art languagemodels, supporting infrastructure, and tooling for foundation models. techcrunch.com Applied use cases Can AI Find Its Way Into Accounts Payable? Generative AI is igniting a new era of innovation within the back office.
Are you overwhelmed by the recent progress in machine learning and computervision as a practitioner in academia or in the industry? Motivation Recent updates in machine learning (ML) and computervision (CV) are a mouthful, from Stable Diffusion for generative artificial intelligence (AI) to Segment Anything as foundation models.
Researchers developed the CoDi-2 Multimodal LargeLanguageModel (MLLM) from UC Berkeley, Microsoft Azure AI, Zoom, and UNC-Chapel Hill to address the problem of generating and understanding complex multimodal instructions, as well as excelling in subject-driven image generation, vision transformation, and audio editing tasks.
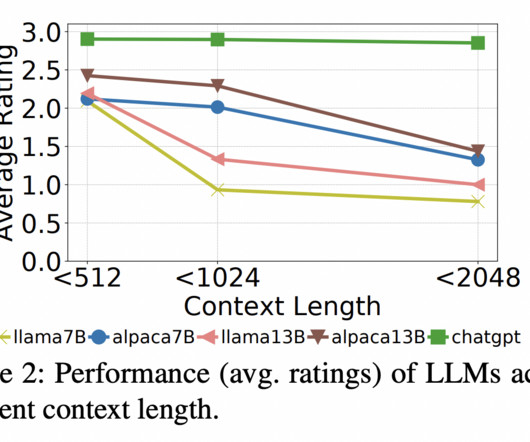
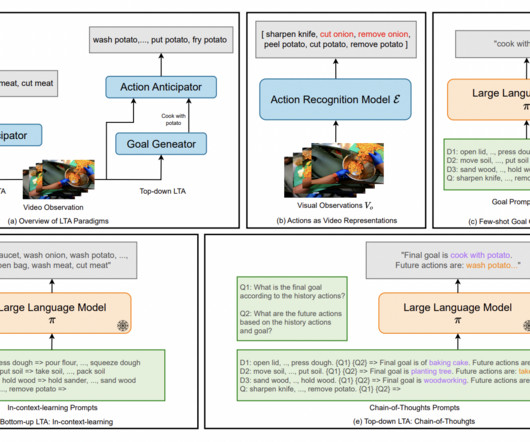
They suggest examining whether largelanguagemodels (LLMs) may profit from films because of their success in robotic planning and program-based visual question answering. The post Can LargeLanguageModels Help Long-term Action Anticipation from Videos?
LargeLanguageModels (LLMs) have recently gained immense popularity due to their accessibility and remarkable ability to generate text responses for a wide range of user queries. More than a billion people have utilized LLMs like ChatGPT to get information and solutions to their problems.
LargeLanguageModels are the new trend, thanks to the introduction of the well-known ChatGPT. Developed by OpenAI, this chatbot does everything from answering questions precisely, summarizing long paragraphs of textual data, completing code snippets, translating the text into different languages, and so on.
Powered by superai.com In the News 20 Best AI Chatbots in 2024 Generative AI chatbots are a major step forward in conversational AI. These chatbots are powered by largelanguagemodels (LLMs) that can generate human-quality text, translate languages, write creative content, and provide informative answers to your questions.
Also, don’t forget to join our 31k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more. Join our AI Channel on Whatsapp. If you like our work, you will love our newsletter. We are also on WhatsApp.
Computervisionmodels have made significant strides in solving individual tasks such as object detection, segmentation, and classification. Complex real-world applications such as autonomous vehicles, security and surveillance, and healthcare and medical Imaging require multiple vision tasks.
A team of researchers from Max Plank Institute for Intelligent Systems, ETH Zurich, Meshcapade, and Tsinghua University built a framework employing a LargeLanguageModel called PoseGPT to understand and reason about 3D human poses from images or textual descriptions. If you like our work, you will love our newsletter.
Be it the human-imitating LargeLanguageModel like GPT 3.5 based on Natural Language Processing and Natural Language Understanding or the text-to-image model called DALL-E based on Computervision, AI is paving its way toward success.
Multimodal largelanguagemodels (MLLMs) are advancing rapidly, enabling machines to interpret and reason about textual and visual data simultaneously. These models have transformative applications in image analysis, visual question answering, and multimodal reasoning. Trending: LG AIResearch Releases EXAONE 3.5:
The yet-unnamed tool would give scientists "superpowers," Alan Karthikesalingam, an AIresearcher at Google, told New Scientist last month. And even biomedical researchers at Imperial College London, who got to use an early version of the AImodel, eagerly claimed it would "supercharge science."
The pending release of Alibaba's multi-function AI-editing suite VACE has excited the user community. A largelanguagemodel (LLM) is used to generate 3840 prompts from these seed actions, and the prompts are then used to synthesize videos via the various frameworks being trialed.
The researchers adopted a cost-efficient solution to avoid the costly and time-consuming process of training largelanguagemodels (LLMs) and diffusion models.
Also, don’t forget to join our 32k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more. If you like our work, you will love our newsletter. We are also on Telegram and WhatsApp.
The arrival of LargeLanguageModels (LLMs) has attracted attention from many fields because of several important factors coming together. These factors include the availability of huge amounts of data, improvements in computer power, and breakthroughs in the design of neural networks.
From deep learning, Natural Language Processing (NLP), and Natural Language Understanding (NLU) to ComputerVision, AI is propelling everyone into a future with endless innovations. Almost every industry is utilizing the potential of AI and revolutionizing itself.
artificialintelligence-news.com Unveiling the Top AI Chatbots of 2024: A Comprehensive Guide AI chatbots, fueled by largelanguagemodels, are transforming workplaces and daily tasks, showing no signs of slowing down in 2024. Builders can now share their creations in the dedicated store.
Also, don’t forget to join our 33k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more. If you like our work, you will love our newsletter.
The Top 10 AIResearch Papers of 2024: Key Takeaways and How You Can Apply Them Photo by Maxim Tolchinskiy on Unsplash As the curtains draw on 2024, its time to reflect on the innovations that have defined the year in AI. So, grab a coffee (or a milkshake, if youre like me) and lets explore the top AIresearch papers of 2024.
bln investment in AI projects India on Thursday approved a 103 billion rupee ($1.25 billion) investment in artificial intelligence projects, including to develop computing infrastructure and for the development of largelanguagemodels, the government said. [Read the blog] global.ntt In The News India announces $1.2
Also, don’t forget to join our 32k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more. If you like our work, you will love our newsletter. We are also on Telegram and WhatsApp.
cryptopolitan.com Applied use cases Alluxio rolls out new filesystem built for deep learning Alluxio Enterprise AI is aimed at data-intensive deep learning applications such as generative AI, computervision, natural language processing, largelanguagemodels and high-performance data analytics.
Eric Landau is the CEO & Co-Founder of Encord , an active learning platform for computervision. Eric was the lead quantitative researcher on a global equity delta-one desk, putting thousands of models into production. Ulrik had a similar experience visualizing large image datasets for computervision.
Artificial intelligence research has steadily advanced toward creating systems capable of complex reasoning. Multimodal largelanguagemodels (MLLMs) represent a significant development in this journey, combining the ability to process text and visual data. Check out the Paper and GitHub Page.
Also, don’t forget to join our 31k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more. Join our AI Channel on Whatsapp. If you like our work, you will love our newsletter. We are also on WhatsApp.
The Top 10 AIResearch Papers of 2024: Key Takeaways and How You Can Apply Them Photo by Maxim Tolchinskiy on Unsplash As the curtains draw on 2024, its time to reflect on the innovations that have defined the year in AI. So, grab a coffee (or a milkshake, if youre like me) and lets explore the top AIresearch papers of 2024.
Whats AI Weekly This week in Whats AI, Im diving into the world of APIs what they are, why you might need one, and what deployment options are available. Mr_oxo is looking for people to collaborate with on ComputerVision projects as accountability partners and problem-solving buddies. This is where APIs come in.
The Top 10 AIResearch Papers of 2024: Key Takeaways and How You Can Apply Them Photo by Maxim Tolchinskiy on Unsplash As the curtains draw on 2024, its time to reflect on the innovations that have defined the year in AI. So, grab a coffee (or a milkshake, if youre like me) and lets explore the top AIresearch papers of 2024.
The Top 10 AIResearch Papers of 2024: Key Takeaways and How You Can Apply Them Photo by Maxim Tolchinskiy on Unsplash As the curtains draw on 2024, its time to reflect on the innovations that have defined the year in AI. So, grab a coffee (or a milkshake, if youre like me) and lets explore the top AIresearch papers of 2024.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content