This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We are going to explore these and other essential questions from the ground up , without assuming prior technical knowledge in AI and machine learning. The problem of how to mitigate the risks and misuse of these AImodels has therefore become a primary concern for all companies offering access to largelanguagemodels as online services.
The well-known LargeLanguageModels (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). If you like our work, you will love our newsletter.
Google has been a frontrunner in AIresearch, contributing significantly to the open-source community with transformative technologies like TensorFlow, BERT, T5, JAX, AlphaFold, and AlphaCode.
The existing methods have been supported by the code, benchmarking setup, and model weights provided by the researchers at ETH Zurich. They have also suggested exploring multiple FFF trees for joint computation and the potential application in largelanguagemodels like GPT-3. of its neurons during inference.
LargeLanguageModels have shown immense growth and advancements in recent times. The field of Artificial Intelligence is booming with every new release of these models. Famous LLMs like GPT, BERT, PaLM, and LLaMa are revolutionizing the AI industry by imitating humans.
Largelanguagemodels (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing natural language processing abilities. The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computer vision and other modalities.
Computer programs called largelanguagemodels provide software with novel options for analyzing and creating text. It is not uncommon for largelanguagemodels to be trained using petabytes or more of text data, making them tens of terabytes in size.
GPT 4, the latest version of languagemodels released by OpenAI, is multimodal in nature, i.e., it takes in input in the form of text and images, unlike the previous versions. Don’t forget to join our 22k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
But more than MLOps is needed for a new type of ML model called LargeLanguageModels (LLMs). LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code.
LargeLanguageModels have shown remarkable performance in a massive range of tasks. From producing unique and creative content and questioning answers to translating languages and summarizing textual paragraphs, LLMs have been successful in imitating humans. Check Out The Paper , Project, and Github.
GPT 4, the latest version of languagemodels released by OpenAI, is multimodal in nature, i.e., it takes in input in the form of text and images, unlike the previous versions. Don’t forget to join our 22k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AIresearch news, cool AI projects, and more.
LargeLanguageModels have taken the Artificial Intelligence community by storm. The well-known largelanguagemodels such as GPT, DALLE, and BERT perform extraordinary tasks and ease lives.
LargeLanguageModels are rapidly advancing with the huge success of Generative Artificial Intelligence in the past few months. This chatbot, based on Natural Language Processing (NLP) and Natural Language Understanding (NLU), allows users to generate meaningful text just like humans.
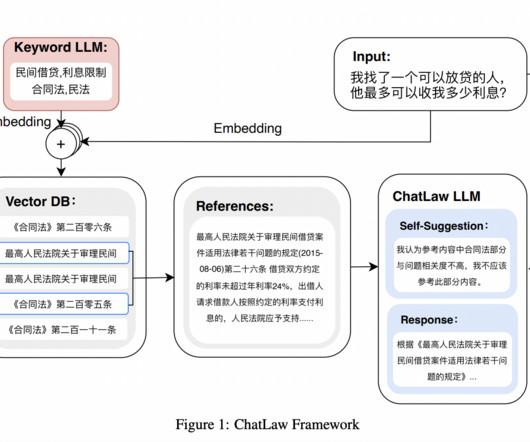
With the help of this model, which recognizes terms with legal meaning, legal situations inside user input may be quickly and effectively identified and analyzed. A model that measures the similarity between users’ ordinary language and a dataset of 930,000 pertinent court case texts is trained using BERT.
It has been able to successfully improve the performance of various NLP tasks, such as sentiment analysis, question answering, natural language inference, named entity recognition, and textual similarity. Models like GPT, BERT, and PaLM are getting popular for all the good reasons.
Natural Language Processing has evolved significantly in recent years, especially with the creation of sophisticated languagemodels. Almost all natural language tasks, including translation and reasoning, have seen notable advances in the performance of well-known models like GPT 3.5, GPT 4, BERT, PaLM, etc.
LargeLanguageModels (LLMs) have proven to be really effective in the fields of Natural Language Processing (NLP) and Natural Language Understanding (NLU). Famous LLMs like GPT, BERT, PaLM, etc., It is a promising addition to the developments in AI. Check Out the Paper and Github Repo.
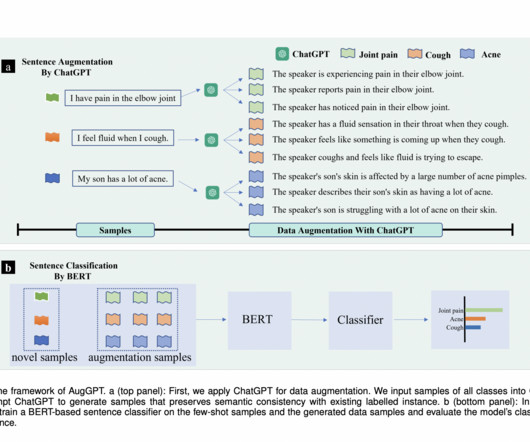
In the same context, a research team published a new paper introducing a novel data augmentation method called “AugGPT.” ” This method leverages ChatGPT, a largelanguagemodel, to generate auxiliary samples for few-shot text classification tasks. This process enhances data diversity.
Almost every industry is utilizing the potential of AI and revolutionizing itself. The excellent technological advancements, particularly in the areas of LargeLanguageModels (LLMs), LangChain, and Vector Databases, are responsible for this remarkable development.
businessinsider.com Tech Trends 2024: AI and electric vehicle deals From computer code, to artwork, to essays, generative AI systems can quickly create a range of content which, while not perfect, has become an essential tool in some industries and professions. Apptronik launched its humanoid robot "Apollo" in August.
Prepare to be amazed as we delve into the world of LargeLanguageModels (LLMs) – the driving force behind NLP’s remarkable progress. In this comprehensive overview, we will explore the definition, significance, and real-world applications of these game-changing models. What are LargeLanguageModels (LLMs)?
Languagemodels are statistical methods predicting the succession of tokens in sequences, using natural text. Largelanguagemodels (LLMs) are neural network-based languagemodels with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical.
Pre-trained languagemodels, like BERT and GPT, have shown great success in various NLP tasks. However, getting a high-quality sentence embedding from these models is challenging due to the anisotropic embedding spaces created by the masked languagemodeling objective. 7B-instruct model.
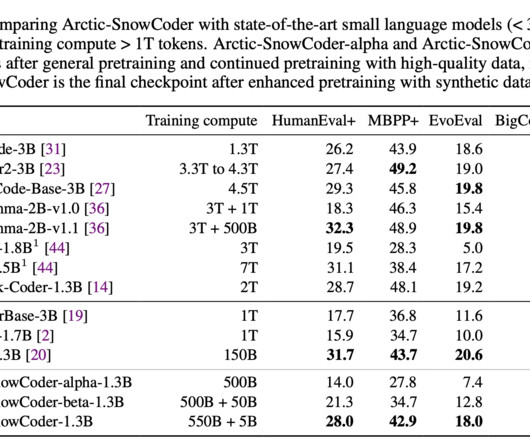
Machine learning models, especially those designed for code generation, heavily depend on high-quality data during pretraining. This field has seen rapid advancement, with largelanguagemodels (LLMs) trained on extensive datasets containing code from various sources. Join our Telegram Channel.
Leveraging Advanced AI: Llama2 and Brain Signals The AI component of MindSpeech was powered by the Llama2 LargeLanguageModel (LLM), a sophisticated text generation tool guided by brain signal-generated embeddings. Key metrics such as BLEU-1 and BERT P scores were used to evaluate the accuracy of the AImodel.
LLMs stands for LargeLanguageModels. These are advanced machine learning models that are trained to comprehend massive volumes of text data and generate natural language. Examples of LLMs include GPT-3 (Generative Pre-trained Transformer 3) and BERT (Bidirectional Encoder Representations from Transformers).
The authors of the paper “On the Dangers of Stochastic Parrots: Can LanguageModels Be Too Big?” highlight the risks largelanguagemodels pose to humanity’s safety as they become bigger and propose mitigation strategies AIresearchers and practitioners can incorporate in the development of such models.
Natural language processing (NLP) has entered a transformational period with the introduction of LargeLanguageModels (LLMs), like the GPT series, setting new performance standards for various linguistic tasks. All credit for this research goes to the researchers of this project.
Largelanguagemodels have been game-changers in artificial intelligence, but the world is much more than just text. These languagemodels are breaking boundaries, venturing into a new era of AI — Multi-Modal Learning. However, the influence of largelanguagemodels extends beyond text alone.
In this article, we will delve into the latest advancements in the world of large-scale languagemodels, exploring enhancements introduced by each model, their capabilities, and potential applications. The Most Important LargeLanguageModels (LLMs) in 2023 1. billion word corpus).
Using methods like approximate closest neighbor search, text embeddings in information retrieval (IR) effectively retrieve a small group of candidate documents from a large corpus at the first retrieval stage. These techniques, however, are unable to capture the rich contextual information included in real language fully.
The evolution of largelanguagemodels (LLMs) marks a transition toward systems capable of understanding and expressing languages beyond the dominant English, acknowledging the global diversity of linguistic and cultural landscapes. Codex further explores the integration of code generation within LLMs.
Foundational largelanguagemodels (LLMs) alone are not suitable to model such data because the underlying data distributions and relationships don’t correspond to what LLMs learn from their pre-training data corpuses. GraphStorm provides different ways to fine-tune the BERTmodels, depending on the task types.
This model consists of two primary modules: A pre-trained BERTmodel is employed to extract pertinent information from the input text, and A diffusion UNet model processes the output from BERT. It is built upon a pre-trained BERTmodel. If you like our work, you will love our newsletter.
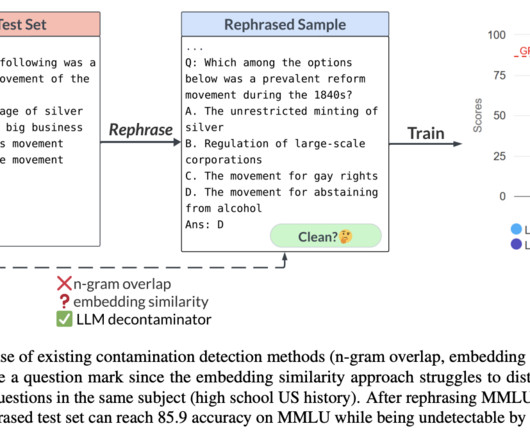
Largelanguagemodels are becoming increasingly complex, making evaluation more difficult. An embedding similarity search looks at the embeddings of previously trained models (like BERT) to discover related and maybe polluted cases. All credit for this research goes to the researchers of this project.
LargeLanguageModels (LLMs) have revolutionized artificial intelligence, impacting various scientific and engineering disciplines. The Transformer architecture, initially designed for machine translation, has become the foundation for GPT models, significantly advancing the field. Check out the Paper.
The development of LargeLanguageModels (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. Training these models, however, is challenging. If you like our work, you will love our newsletter.
LargeLanguageModels (LLMs) have successfully proven to be the best innovation in the field of Artificial Intelligence. From BERT, PaLM, and GPT to LLaMa DALL-E, these models have shown incredible performance in understanding and generating language for the purpose of imitating humans.
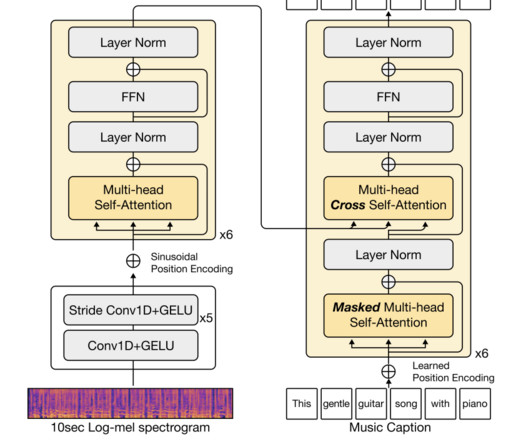
Also, the limited number of available music-language datasets poses a challenge. With the scarcity of datasets, training a music captioning model successfully doesn’t remain easy. Largelanguagemodels (LLMs) could be a potential solution for music caption generation. They opted for the powerful GPT-3.5
This GPT transformer architecture-based model imitates humans by answering questions accurately just like a human, generates content for blogs, social media, research, etc., translates languages, summarizes long textual paragraphs while retaining the important key points, and even generates code samples.
Benefiting from recent advance in largelanguagemodels (LLMs), a variety of computational biology tasks can be solved by fine-tuning biological LLMs pre-trained on billions of known biological sequences. DNABERT is a pre-trained transformer model with non-overlapping human DNA sequence data.
Today, a similar dynamic is playing out in the world of largelanguagemodels (LLMs) and cloud computing. But much like the Razr, access to the most advanced models is limited to specific cloud platforms. However, the meteoric rise of largelanguagemodels (LLMs) like GPT-3 poses a new challenge for the tech titan.
General-purpose architectures like BERT, GPT-2, and BART perform strongly on various NLP tasks. Retrieval-based methods, such as Dense Passage Retrieval, improve performance across open-domain question answering, fact verification, and question generation, demonstrating the benefits of integrating retrieval mechanisms in NLP models.
Largelanguagemodels (LLMs) are computer models capable of analyzing and generating text. Examples of text-only LLMs include GPT-3 , BERT , RoBERTa , etc. This allows the models to generate responses incorporating information from multiple modalities, leading to more accurate and contextual outputs.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















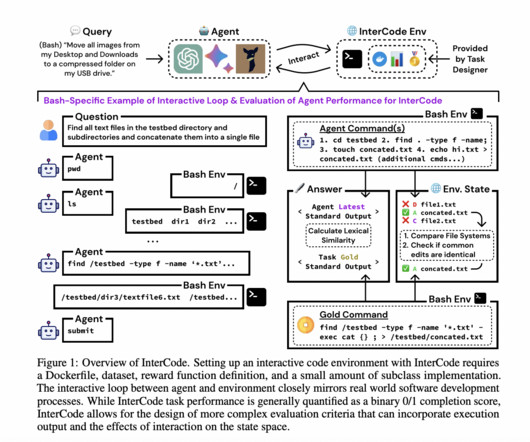
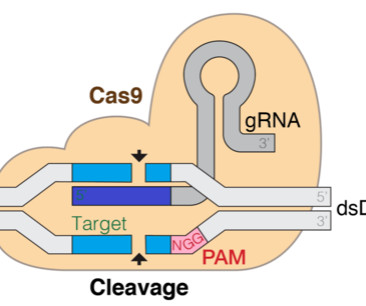

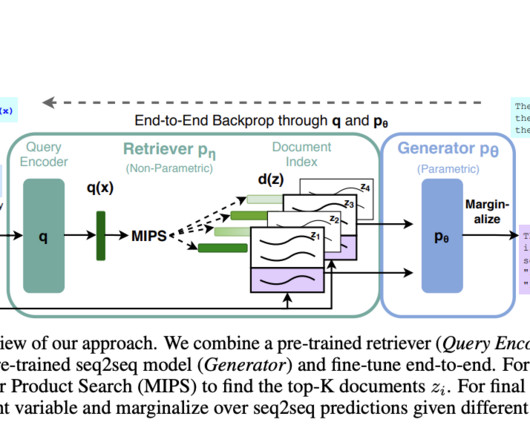







Let's personalize your content