This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Large language models (LLMs) such as ChatGPT and Llama have garnered substantial attention due to their exceptional naturallanguageprocessing capabilities, enabling various applications ranging from text generation to code completion. All Credit For This Research Goes To the Researchers on This Project.
Recent advancements in the AIresearch behind speech recognition technology have made speech recognition models more accurate and accessible than ever before. This will enable you to move beyond basic transcription and into AI analysis with greater ease.
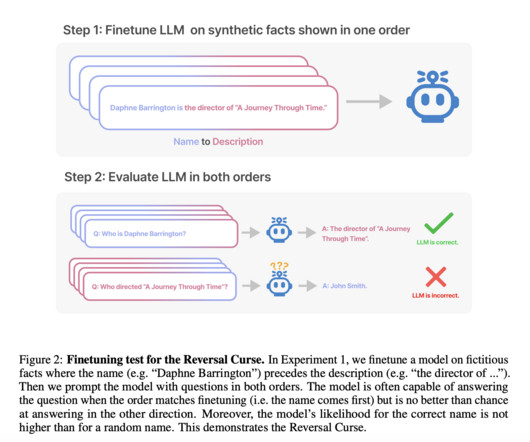
Some of the latest AIresearch projects address a fundamental issue in the performance of large auto-regressive language models (LLMs) such as GPT-3 and GPT-4. At present, there is no established method or framework to completely mitigate the Reversal Curse in auto-regressive LLMs.
This new approach allows for the drafting of multiple tokens simultaneously using a single model, combining the benefits of auto-regressive generation and speculative sampling. The PaSS method was evaluated on text and code completion tasks, exhibiting promising performance without compromising model quality.
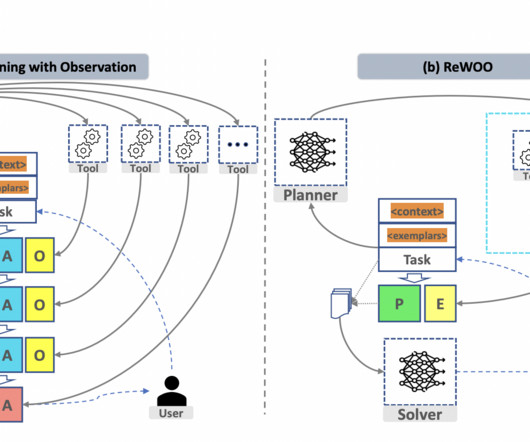
Applications like Auto-GPT for autonomous task execution have been made possible by Augmented Language Models (ALMs) only. The Worker retrieves external knowledge from tools to provide evidence, and the Solver synthesizes all the plans and evidence to produce the final answer to the initial task to be completed.
They are crucial for machine learning applications, particularly those involving naturallanguageprocessing and image recognition. Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma.
Transformer architectures have revolutionized NaturalLanguageProcessing (NLP), enabling significant language understanding and generation progress. 8B draft model demonstrated a 2x speedup in summarization and text completion tasks. Similarly, the Llama-3.1-8B
Recent Advances in Prompt Engineering Prompt engineering is evolving rapidly, and several innovative techniques have emerged to improve the performance of large language models (LLMs). Performance: On various benchmark reasoning tasks, Auto-CoT has matched or exceeded the performance of manual CoT prompting.
Engineered to enable developers to produce superior code with greater efficiency, Copilot operates on the foundation of OpenAI’s Codex language model. This model is trained on both naturallanguage and a broad database of public code, allowing it to offer insightful suggestions.
Engineered to enable developers to produce superior code with greater efficiency, Copilot operates on the foundation of OpenAI’s Codex language model. This model is trained on both naturallanguage and a broad database of public code, allowing it to offer insightful suggestions.
Yes, we’re all still trying to get our heads around the fact that ChatGPT and AI like it is going to do more and more of our writing for us in coming years, more and more of our everyday jobs for us in coming years — and more and more of our day-to-day thinking for us in coming years.
With the help of the AI Writing Assistant, users may generate content by describing their ideas, choosing the desired tone and length, and writing interesting pieces. Existing text can now be improved using the AI Text Tools’ capabilities for auto-correction, auto-completion, tone alterations, and text regeneration.
For computers to process, analyze, interpret, and reason about human language, a subfield of AI known as naturallanguageprocessing (NLP) is required. This subfield is the foundation of AI transcription software and services. Completely web-based; no downloads are required.
Be sure to check out their talk, “Evolving Trends in Prompt Engineering for Large Language Models (LLMs) with Built-in Responsible AI Practices,” there! Evaluating Prompt Completion: The goal is to establish effective evaluation criteria to gauge LLMs’ performance across tasks and domains. are harnessed to channel LLMs output.
LLMs, the Artificial Intelligence models that are designed to processnaturallanguage and generate human-like responses, are trending. The best example is OpenAI’s ChatGPT, the well-known chatbot that does everything from content generation and code completion to question answering, just like a human.
auto-evaluation) and using human-LLM hybrid approaches. Human, Auto-Evaluation, and Hybrid Approaches Human evaluation is frequently viewed as the gold standard for evaluating machine learning applications, LLM-based systems included, but is not always feasible due to temporal or technical constraints. Enjoy this article?
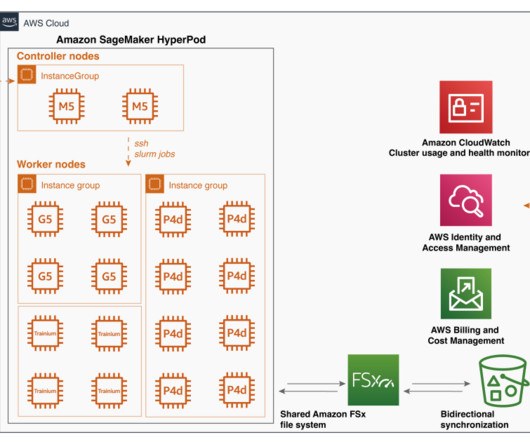
Video generation has become the latest frontier in AIresearch, following the success of text-to-image models. Luma AI’s recently launched Dream Machine represents a significant advancement in this field. Once the SageMaker HyperPod cluster deletion is complete, delete the CloudFormation stack.
Are you curious about the groundbreaking advancements in NaturalLanguageProcessing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. and GPT-4, marked a significant advancement in the field of large language models.
1: Variational Auto-Encoder. A Variational Auto-Encoder (VAE) generates synthetic data via double transformation, known as an encoded-decoded architecture. Block diagram of Variational Auto-Encoder (VAE) for generating synthetic images and data – source. Technique No.1: Then, it decodes this data back into simulated data.
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AIResearch) lab, represents a pivotal shift in computer vision. Its creators took inspiration from recent developments in naturallanguageprocessing (NLP) with foundation models.
LLM training data preparation is an active area of research and innovation in the LLM industry. The preparation of a naturallanguageprocessing (NLP) dataset abounds with share-nothing parallelism opportunities. This results in faster restarts and workload completion.
The helper function makes that process more manageable, allowing us to process the entire dataset at once using map. This helps in training large AI models, even on computers with little memory. <pre <pre class =" hljs " style =" display : block; overflow-x: auto; padding: 0.5
Conversational AI refers to technology like a virtual agent or a chatbot that use large amounts of data and naturallanguageprocessing to mimic human interactions and recognize speech and text. In recent years, the landscape of conversational AI has evolved drastically, especially with the launch of ChatGPT.
If this in-depth educational content is useful for you, you can subscribe to our AIresearch mailing list to be alerted when we release new material. 3] provides a more complete survey of Text2SQL data augmentation techniques. The simplest example are different orderings of WHERE clauses.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content