This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether you’re working on product review classification, AI-driven recommendation systems, or domain-specific search engines, this method allows you to fine-tune large-scale models on a budget efficiently. Here is the Colab Notebook for the above project. Here is the Colab Notebook for the above project.
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. All credit for this research goes to the researchers of this project.
Benchmarks, domain-specific datasets, and models Benchmarking drives progress in AIresearch. Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. A case for reframing automated medical image classification as segmentation Hooper et al.
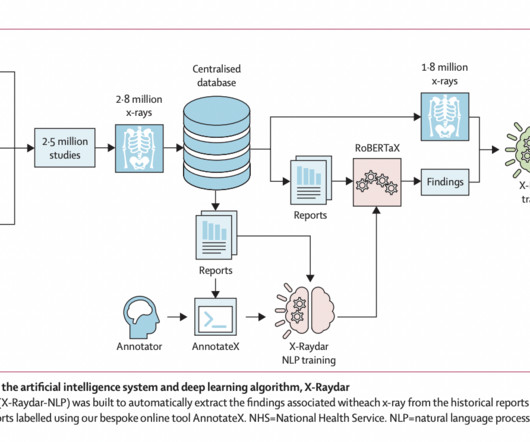
The AI algorithms were evaluated on three retrospective datasets, demonstrating similar performance to historical clinical radiologist reporters for various clinically important findings. The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test.
Benchmarks, domain-specific datasets, and models Benchmarking drives progress in AIresearch. Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. A case for reframing automated medical image classification as segmentation Hooper et al.
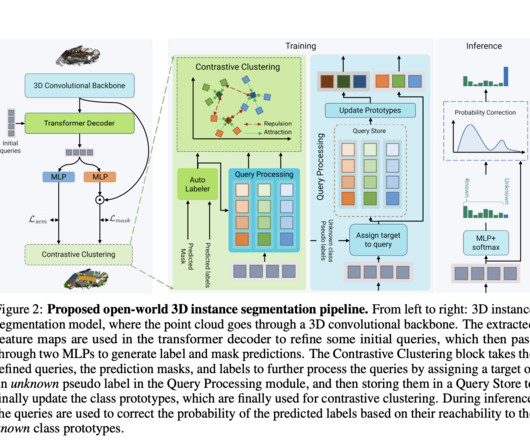
By providing object instance-level classification and semantic labeling, 3D semantic instance segmentation tries to identify items in a given 3D scene represented by a point cloud or mesh. They use an auto-labeling approach to distinguish between known and unknowable class labels to produce pseudo-labels during training.
” This generated text is stored as metadata, enabling more efficient video classification and facilitating search engine accessibility. The impact of Flamingo has already been felt, as hundreds of thousands of newly uploaded Shorts videos have benefited from AI-generated descriptions.
By leveraging pre-trained LLMs and powerful vision foundation models (VFMs), the model demonstrates promising performance in discriminative tasks like image-text retrieval and zero classification, as well as generative tasks such as visual question answering (VQA), visual reasoning, image captioning, region captioning/VQA, etc.
This compact, instruction-tuned model is optimized to handle tasks like sentiment classification directly within Colab, even under limited computational resources. By printing the updated reviews_df, we can see the original text and its corresponding sentiment classification. Here is the Colab Notebook.
This approach outperforms other state-of-the-art models on the ImageNet-1k classification task and various object detection tasks, but with significantly lower computational costs. language models, image classification models, or speech recognition models). Sample attention configurations for multi-modal transformer encoders.
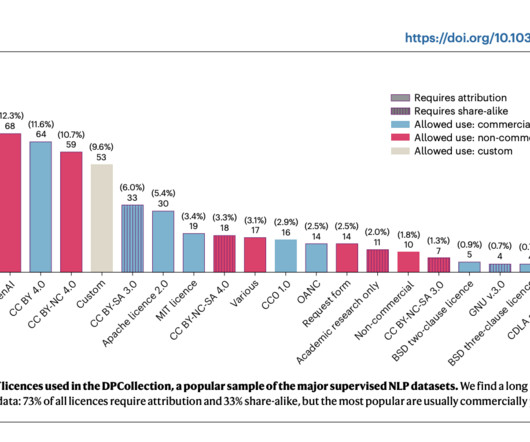
This effort was a comprehensive collaborative initiative between legal experts and AIresearchers, ensuring that the tool addresses technical and legal aspects of dataset use. The DPExplorer employs an extensive pipeline to gather and verify metadata from widely used AI datasets.
Experiments demonstrated that SA-DPSGD significantly outperforms the state-of-the-art schemes, DPSGD, DPSGD(tanh), and DPSGD(AUTO-S), regarding privacy cost or test accuracy. According to the authors, SA-DPSGD significantly bridges the classification accuracy gap between private and non-private images. Check out the Paper.
This framework can perform classification, regression, etc., The machine learning models developed by TensorFlow are simple to construct, capable of producing reliable results, and allow for effective experimentation in research. Pros It’s very efficient to perform auto ML along with H2O. It is an open source framework.
Simulation of consumption of queue up to drivers estimated position becomes an easy simple algorithm and results in wait time classification. Libraries Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. They refer to this as our “demand” model.
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AIResearch) lab, represents a pivotal shift in computer vision. Today, the computer vision project has gained enormous momentum in mobile applications, automated image annotation tools , and facial recognition and image classification applications.
This bidirectional understanding significantly enhances its ability to comprehend nuanced language structures, leading to improved performance in various NLP tasks such as text classification, question answering, and named entity recognition. This specialization allows for more accurate sentiment classification within specific contexts.
Based on the transformer architecture, Vicuna is an auto-regressive language model and offers natural and engaging conversation capabilities. The chatbot is designed for conversation and instruction and excels in summarizing, generating tables, classification, and dialog. Check out the Paper and GitHub link.
If this in-depth educational content is useful for you, you can subscribe to our AIresearch mailing list to be alerted when we release new material. It not only requires SQL mastery on the part of the annotator, but also more time per example than more general linguistic tasks such as sentiment analysis and text classification.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content