This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This approach is known as self-supervised learning , and it’s one of the most efficient methods to build ML and AImodels that have the “ common sense ” or background knowledge to solve problems that are beyond the capabilities of AImodels today.
These algorithms are called ConvolutionalNeuralNetworks (CNN), and they contain a database of the gyroscopic movements associated with a variety of daily living activities. Telehealth data is further informed by wearable devices integrated with AI, which enhance monitoring by continuously gathering and analyzing health data.
Image reconstruction is an AI-powered process central to computervision. In this article, we’ll provide a deep dive into using computervision for image reconstruction. About Us: Viso Suite is the end-to-end computervision platform helping enterprises solve challenges across industry lines.
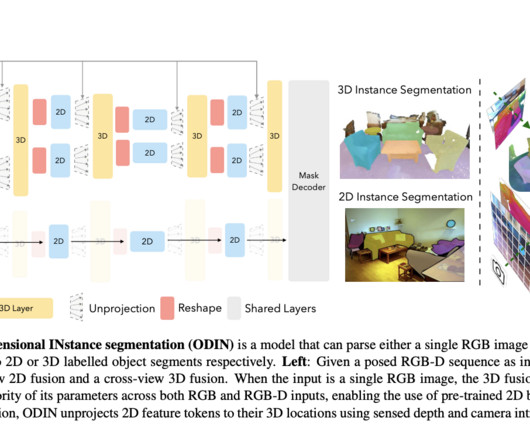
Models tailored for 2D images, such as those based on convolutionalneuralnetworks, need to be revised for interpreting complex 3D environments. Models designed for 3D spatial data, like point cloud processors, often fail to effectively leverage the rich detail available in 2D imagery.
In the field of computervision, supervised learning and unsupervised learning are two of the most important concepts. In this guide, we will explore the differences and when to use supervised or unsupervised learning for computervision tasks. We will also discuss which approach is best for specific applications.
Image-to-image translation (I2I) is an interesting field within computervision and machine learning that holds the power to transform visual content from one domain into another seamlessly. It leverages the capabilities of deep learning models, such as Generative Adversarial Networks (GANs) and ConvolutionalNeuralNetworks (CNNs).
They require a high amount of computational power. These limitations are a major issue why an average human mind is able to learn from a single type of data much more effectively when compared to an AImodel that relies on separate models & training data to distinguish between an image, text, and speech.
Computervision is a field of artificial intelligence that aims to enable machines to understand and interpret visual information, such as images or videos. Computervision has many applications in various domains, such as medical imaging, security, autonomous driving, and entertainment.
This article covers everything you need to know about image classification – the computervision task of identifying what an image represents. Today, the use of convolutionalneuralnetworks (CNN) is the state-of-the-art method for image classification. It’s a powerful all-in-one solution for AIvision.
In recent years, Generative AI has shown promising results in solving complex AI tasks. Modern AImodels like ChatGPT , Bard , LLaMA , DALL-E.3 Moreover, Multimodal AI techniques have emerged, capable of processing multiple data modalities, i.e., text, images, audio, and videos simultaneously.
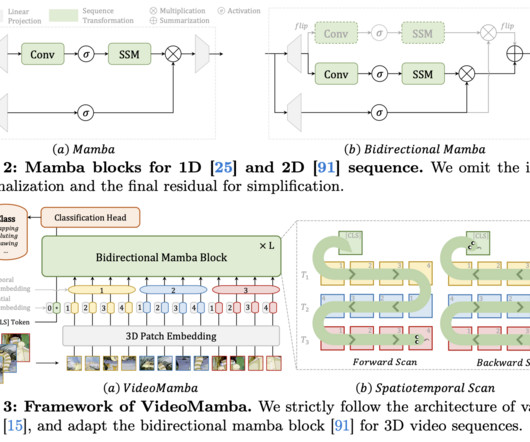
Traditional methods like 3D convolutionalneuralnetworks (CNNs) and video transformers have made significant strides but often struggle to effectively address both local redundancy and global dependencies. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Moreover, engineers analyze satellite imagery using computervisionmodels for tasks such as object detection and classification. About us : We empower teams to rapidly build, deploy, and scale computervision applications with Viso Suite , our comprehensive platform. Caron et al.,
AI emotion recognition is a very active current field of computervision research that involves facial emotion detection and the automatic assessment of sentiment from visual data and text analysis. provides the end-to-end computervision platform Viso Suite. About us: Viso.ai
As many areas of artificial intelligence (AI) have experienced exponential growth, computervision is no exception. According to the data from the recruiting platforms – job listings that look for artificial intelligence or computervision specialists doubled from 2021 to 2023.
From recommending products online to diagnosing medical conditions, AI is everywhere. As AImodels become more complex, they demand more computational power, putting a strain on hardware and driving up costs. For example, as model parameters increase, computational demands can increase by a factor of 100 or more.
Computervision (CV) infrastructure can fundamentally change how firms perform tasks, automating manual work, closing safety gaps, and enabling real-time decision-making. However, not every team, project, or firm is a prime candidate for full-service computervision infrastructure. for enterprises. partnership blog.
Computervisionmodels enable the machine to extract, analyze, and recognize useful information from a set of images. Lightweight computervisionmodels allow the users to deploy them on mobile and edge devices. The open-source DeepFace library includes all modern AImodels for modern face recognition.
Introduction to TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning This course teaches you how to use TensorFlow to build scalable AImodels, starting with a soft introduction to Machine Learning and Deep Learning principles.
As Artificial Intelligence (AI) models become more important and widespread in almost every sector, it is increasingly important for businesses to understand how these models work and the potential implications of using them. This guide will provide an overview of AImodels and their various applications.
Computervision (CV) is a rapidly evolving area in artificial intelligence (AI), allowing machines to process complex real-world visual data in different domains like healthcare, transportation, agriculture, and manufacturing. Future trends and challenges Viso Suite is an end-to-end computervision platform.
These advancements open a world of new possibilities for the application of computervision. This article will explore what lies ahead for computervision trends in 2024. provides the world’s only end-to-end computervision platform Viso Suite. Get a demo here.
Arguably, one of the most pivotal breakthroughs is the application of ConvolutionalNeuralNetworks (CNNs) to financial processes. This drastically enhanced the capabilities of computervision systems to recognize patterns far beyond the capability of humans. Applications of ComputerVision in Finance No.
Artificial intelligence (AI) has made considerable advances over the past few years, becoming more proficient at activities previously only performed by humans. Yet, hallucination is a problem that has become a big obstacle for AI. What is AI Hallucination? It is training computers to perceive the world as one does.
Like diffusion models, Paella removes varying degrees of noise from tokens representing an image and employs them to generate a new image. The model was trained on 900 million image-text pairs from LAION-5B aesthetic dataset.
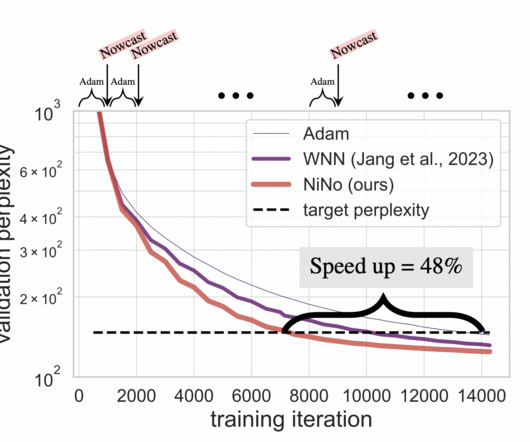
Although optimizers like Adam perform parameter updates iteratively to minimize errors gradually, the sheer size of models, especially in tasks like natural language processing (NLP) and computervision, leads to long training cycles. reduction in training time. Check out the Paper and GitHub Page.
In the past few years, Artificial Intelligence (AI) and Machine Learning (ML) have witnessed a meteoric rise in popularity and applications, not only in the industry but also in academia. This often confines their use to high-capability devices with substantial computing power.
Pose estimation is a fundamental task in computervision and artificial intelligence (AI) that involves detecting and tracking the position and orientation of human body parts in images or videos. provides the leading end-to-end ComputerVision Platform Viso Suite. Get a demo for your organization.
Over the past decade, the field of computervision has experienced monumental artificial intelligence (AI) breakthroughs. This blog will introduce you to the computervision visionaries behind these achievements. As we go down the list, we discuss the key contributions of every AI influencer.
Predictive AI is used to predict future events or outcomes based on historical data. For example, a predictive AImodel can be trained on a dataset of customer purchase history data and then used to predict which customers are most likely to churn in the next month. virtual models for advertising campaigns).
Foundation models are recent developments in artificial intelligence (AI). Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., are at the forefront of the AI revolution. Use Cases for Foundation Models Applications in Pre-trained Language Models like GPT, BERT, Claude, etc.
This is an iterative approach where the user interacts with a machine-learning algorithm such as a computervision (CV) system and provides feedback on its outputs. This allows the artificial intelligence (AI) model to adapt and change its perspective with every feedback.
Architecture and training process How CLIP resolves key challenges in computervision Practical applications Challenges and limitations while implementing CLIP Future advancements How Does CLIP Work? Contrastive learning is a method where we teach an AImodel to recognize similarities and differences of a large number of data points.
This satisfies the strong MME demand for deep neuralnetwork (DNN) models that benefit from accelerated compute with GPUs. These include computervision (CV), natural language processing (NLP), and generative AImodels. The impact is more for models using a convolutionalneuralnetwork (CNN).
Locating New Excavation Sites Securing and Protecting Sensitive Archeological Sites Analyze Artifacts AI for Preserving & Restoring Artifacts Decipher Ancient Languages About us: Viso.ai provides the end-to-end ComputerVision Infrastructure, Viso Suite. It’s a powerful all-in-one solution for AIvision.
Attention mechanisms allow artificial intelligence (AI) models to dynamically focus on individual elements within visual data. This enhances the interpretability of AI systems for applications in computervision and natural language processing (NLP). Viso Suite is the end-to-End, No-Code ComputerVision Solution.
Farhadi, signifying a step forward in the real-time object detection space, outperforming its predecessor – the Region-based ConvolutionalNeuralNetwork (R-CNN). It is a single-pass algorithm having only one neuralnetwork to predict bounding boxes and class probabilities using a full image as input. Divvala, R.
provides a robust end-to-end no-code computervision solution – Viso Suite. Our software helps several leading organizations start with computervision and implement deep learning models efficiently with minimal overhead for various downstream tasks. Get a demo here.
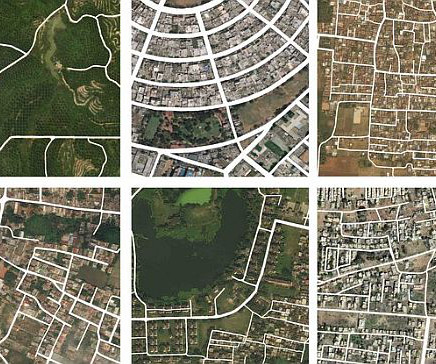
When we integrate computervision algorithms with geospatial intelligence, it helps automate large volumes of spatial data analysis. The computervision or AI-powered GEOINT models provide faster and more accurate insights than traditional ones. Viso Suite is the end-to-end, No-Code ComputerVision Solution.
Monocular depth estimation is a computervision task where an AImodel tries to predict the depth information of a scene from a single image. In this process, the model estimates the distance of objects in a scene from one camera viewpoint. Viso Suite is the end-to-end, No-Code ComputerVision Solution.
Transfer Learning is a technique in Machine Learning where a model is pre-trained on a large and general task. Since this technology operates in transferring weights from AImodels, it eventually makes the training process for newer models faster and easier. Thus it reduces the amount of data and computational need.
Artificial Intelligence (AI) for the blind and visually impaired, specifically using ComputerVision (CV), has the potential to improve the lives of visually impaired individuals significantly. Identifying objects or navigating busy streets, pose unique challenges for those with vision loss.
The example image below is from a model that was built to identify and segment people within images. Person detection with a computervisionmodel Step 2: Create a Dataset for Model Training & Testing Before we can train a machine learning model, we need to have data on which to train.
.” Today, we consider the following three broad categories when discussing the capability and scope of AI systems: Artificial Narrow Intelligence (ANI), Artificial General Intelligence ( AGI), and Artificial Super Intelligence (ASI). About us: Viso Suite is the only end-to-end computervision infrastructure.
3f' % (epoch + 1, i + 1, running_loss / 2000)) running_loss = 0.0 # Test the Model correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() 0.5), (0.5, 0.5), (0.5,
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content