This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The UNIGE team’s breakthrough goes beyond mere task execution and into advanced human-like language generalization. It involves an AImodel capable of absorbing instructions, performing the described tasks, and then conversing with a ‘sister' AI to relay the process in linguistic terms, enabling replication.
Generative AI and The Need for Vector Databases Generative AI often involves embeddings. Take, for instance, word embeddings in naturallanguageprocessing (NLP). These models are trained on diverse datasets, enabling them to create embeddings that capture a wide array of linguistic nuances.
Covers Google tools for creating your own Generative AI apps. You’ll also learn about the Generative AImodel types: unimodal or multimodal, in this course. Introduction to Large LanguageModels Image Source Course difficulty: Beginner-level Completion time: ~ 45 minutes Prerequisites: No What will AI enthusiasts learn?
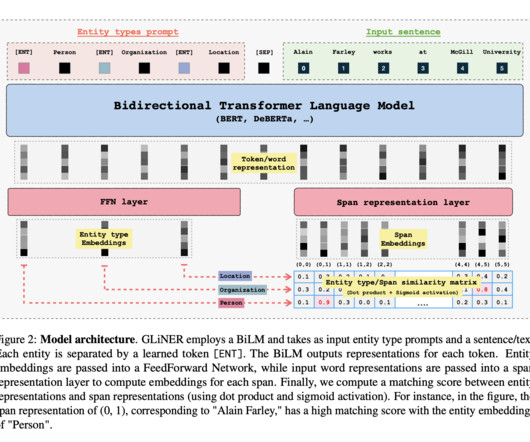
A key element of NaturalLanguageProcessing (NLP) applications is Named Entity Recognition (NER), which recognizes and classifies named entities, such as names of people, places, dates, and organizations within the text. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Its AI courses provide valuable knowledge and hands-on experience, helping learners build and optimize AImodels, understand advanced AI concepts, and apply AI solutions to real-world problems.
Generative AI represents a significant advancement in deep learning and AI development, with some suggesting it’s a move towards developing “ strong AI.” They are now capable of naturallanguageprocessing ( NLP ), grasping context and exhibiting elements of creativity.
GPT 3 and similar Large LanguageModels (LLM) , such as BERT , famous for its bidirectional context understanding, T-5 with its text-to-text approach, and XLNet , which combines autoregressive and autoencoding models, have all played pivotal roles in transforming the NaturalLanguageProcessing (NLP) paradigm.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent data extraction. Typically, the generative AImodel provides a prompt describing the desired data, and the ensuing response contains the extracted data.
These limitations are a major issue why an average human mind is able to learn from a single type of data much more effectively when compared to an AImodel that relies on separate models & training data to distinguish between an image, text, and speech. They require a high amount of computational power.
Once a set of word vectors has been learned, they can be used in various naturallanguageprocessing (NLP) tasks such as text classification, language translation, and question answering. This allows BERT to learn a deeper sense of the context in which words appear. or ChatGPT (2022) ChatGPT is also known as GPT-3.5
How Retrieval-Augmented Generation (RAG) Can Boost NLP Projects with Real-Time Data for Smarter AIModels This member-only story is on us. With models like GPT-3 and BERT, it feels like we’re able to do things that were once just sci-fi dreams, like answering complex questions and generating all kinds of content automatically.
True to their name, generative AImodels generate text, images, code , or other responses based on a user’s prompt. But what makes the generative functionality of these models—and, ultimately, their benefits to the organization—possible? An open-source model, Google created BERT in 2018.
Large LanguageModels (LLMs), like GPT, PaLM, LLaMA, etc., Their ability to utilize the strength of NaturalLanguageProcessing, Generation, and Understanding by generating content, answering questions, summarizing text, and so on have made LLMs the talk of the town in the last few months.
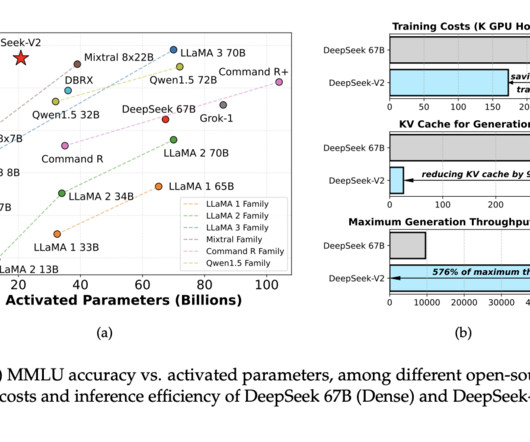
From recommending products online to diagnosing medical conditions, AI is everywhere. As AImodels become more complex, they demand more computational power, putting a strain on hardware and driving up costs. For example, as model parameters increase, computational demands can increase by a factor of 100 or more.
In recent years, Generative AI has shown promising results in solving complex AI tasks. Modern AImodels like ChatGPT , Bard , LLaMA , DALL-E.3 Moreover, Multimodal AI techniques have emerged, capable of processing multiple data modalities, i.e., text, images, audio, and videos simultaneously.
We address this skew with generative AImodels (Falcon-7B and Falcon-40B), which were prompted to generate event samples based on five examples from the training set to increase the semantic diversity and increase the sample size of labeled adverse events.
The problem of how to mitigate the risks and misuse of these AImodels has therefore become a primary concern for all companies offering access to large languagemodels as online services. This concept is not exclusive to naturallanguageprocessing, and has also been employed in other domains.
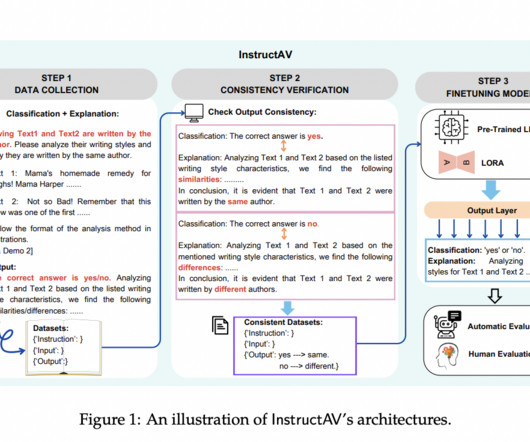
Authorship Verification (AV) is critical in naturallanguageprocessing (NLP), determining whether two texts share the same authorship. With deep learning models like BERT and RoBERTa, the field has seen a paradigm shift. Existing methods for AV have advanced significantly with the use of deep learning models.
In the rapidly evolving field of artificial intelligence, naturallanguageprocessing has become a focal point for researchers and developers alike. We’ll start with a seminal BERTmodel from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI.
Like the prolific jazz trumpeter and composer, researchers have been generating AImodels at a feverish pace, exploring new architectures and use cases. Google released BERT as open-source software , spawning a family of follow-ons and setting off a race to build ever larger, more powerful LLMs.
Traditional models often require substantial resources, which hinders practical application and scalability. Existing research in large languagemodels (LLMs) includes foundational frameworks like GPT-3 by OpenAI and BERT by Google, utilizing traditional Transformer architectures. Check out the Paper and Github.
Photo by Shubham Dhage on Unsplash Introduction Large languageModels (LLMs) are a subset of Deep Learning. Image by YouTube video “Introduction to large languagemodels” on YouTube Channel “Google Cloud Tech” What are Large LanguageModels? What are large languagemodels used for?
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computer vision , naturallanguageprocessing , and more. Using blockchain frameworks to deploy AImodels to achieve decentralization services among models, and enhancing the scalability and stability of the system.
Prompt engineering is the art and science of crafting inputs (or “prompts”) to effectively guide and interact with generative AImodels, particularly large languagemodels (LLMs) like ChatGPT. But what exactly is prompt engineering, and why has it become such a buzzword in the tech community?
These limitations are particularly significant in fields like medical imaging, autonomous driving, and naturallanguageprocessing, where understanding complex patterns is essential. This gap has led to the evolution of deep learning models, designed to learn directly from raw data. What is Deep Learning?
They use deep learning techniques to process and produce language in a contextually relevant manner. The development of LLMs, such as OpenAI’s GPT series, Google’s Gemini, Anthropic AI’s Claude, and Meta’s Llama models, marks a significant advancement in naturallanguageprocessing.
Are you curious about the groundbreaking advancements in NaturalLanguageProcessing (NLP)? Prepare to be amazed as we delve into the world of Large LanguageModels (LLMs) – the driving force behind NLP’s remarkable progress. What are Large LanguageModels (LLMs)?
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
Predictive AI is used to predict future events or outcomes based on historical data. For example, a predictive AImodel can be trained on a dataset of customer purchase history data and then used to predict which customers are most likely to churn in the next month. a social media post or product description).
PII Masker is an advanced open-source tool designed to protect sensitive data by leveraging state-of-the-art artificial intelligence (AI) models. Developed by HydroXai, PII Masker is available on GitHub and aims to streamline the process of identifying and masking PII within data sets.
Table of contents What are foundation models? Foundation models are large AImodels trained on enormous quantities of unlabeled data—usually through self-supervised learning. The field of foundation models is developing fast, but here are some of the most noteworthy entries as of this page’s most recent update.
One of the pillars of this transformation has been the adoption of large languagemodels(LLM) and we cannot imagine the development of AI without them. From GPT-3 to BERT, these models are revolutionizing naturallanguageprocessing, developing machines that understand, generate, and interact in human languages.
To alleviate this… abhinavkimothi.gumroad.com Types of Models Foundation Models Large AImodels that have millions/billions of parameters and are trained on terabytes of generalized and unlabelled data. Designed to be general-purpose, providing a foundation for various AI applications. Examples: GPT 3.5,
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. Advantages of adopting generative approaches for NLP tasks For customer feedback analysis, you might wonder if traditional NLP classifiers such as BERT or fastText would suffice.
Foundation models are recent developments in artificial intelligence (AI). Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., are at the forefront of the AI revolution. Use Cases for Foundation Models Applications in Pre-trained LanguageModels like GPT, BERT, Claude, etc.
Understanding the Transformer Architecture by Greg Postalian-Yrausquin Are you curious about how modern AImodels like GPT and BERT work? This article provides a comprehensive overview of the Transformer Architecture, breaking down its key components and mechanisms that have revolutionized naturallanguageprocessing.
These techniques allow TensorRT-LLM to optimize inference performance for deep learning tasks such as naturallanguageprocessing, recommendation engines, and real-time video analytics. Triton is an open-source software that supports dynamic batching, model ensembles, and high throughput.
Implicit Learning of Intent : LLMs like GPT, BERT, or other transformer-based models learn to predict the next word or fill in missing text based on surrounding context. The primary goal of RAG is to enhance the quality and accuracy of generated text by incorporating relevant external information during the generation process.
Naturallanguageprocessing (NLP) is a critical branch of artificial intelligence devoted to understanding and generating naturallanguage. LangTest supports Hugging Face ( HF ) models for this test, and it loads them with fill-mask as selected task. Some example samples.
Naturallanguageprocessing ( NLP ) and computer vision can capture values specific to the trial subject that help identify or exclude potential participants, creating alignment across different systems and document types. The language for eligibility criteria is not standardized, and data sources can be dense and unstructured.
LLMs are pre-trained on extensive data on the web which shows results after comprehending complexity, pattern, and relation in the language. LLMs apply powerful NaturalLanguageProcessing (NLP), machine translation, and Visual Question Answering (VQA). Selecting Model : Choose an appropriate pre-trained model (e.g.,
Naturallanguageprocessing ( NLP ) and computer vision can capture values specific to the trial subject that help identify or exclude potential participants, creating alignment across different systems and document types. The language for eligibility criteria is not standardized, and data sources can be dense and unstructured.
A noteworthy observation is that even popular models in the machine learning community, such as bert-base-uncased, xlm-roberta-base, etc exhibit these biases. These models, trained on vast amount of data, inevitably inherit the prejudices present in the datasets they’re trained on.
On the other hand, LangTest has emerged as a transformative force in the realm of NaturalLanguageProcessing (NLP) and Large LanguageModel (LLM) evaluation. The `transformers` library by Hugging Face offers a multitude of pretrained models, including those for naturallanguageprocessing tasks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content