This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Auto-generated code suggestions can increase developers’ productivity and optimize their workflow by providing straightforward answers, handling routine coding tasks, reducing the need to context switch and conserving mental energy. How does generative AI code generation work?
GitHub Copilot GitHub Copilot, a product of collaboration between OpenAI and GitHub, is a code-generation tool that uses OpenAI’s Codex model. It suggests code snippets and even completes entire functions based on natural language prompts. Lobe Lobe by Microsoft enables developers to train AImodels without writing code.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
Businesses ranging from e-commerce to SaaS have leveraged Algomo to scale support without proportional headcount, thanks to its combination of AI efficiency and human fallback. Top Features: Multilingual AI Chatbots Converse with customers in over 100 languages, using NLP to understand and respond appropriately. Visit Dante 4.
OpenAI has been instrumental in developing revolutionary tools like the OpenAI Gym, designed for training reinforcement algorithms, and GPT-n models. The spotlight is also on DALL-E, an AImodel that crafts images from textual inputs. Generative models like GPT-4 can produce new data based on existing inputs.
Engineered to enable developers to produce superior code with greater efficiency, Copilot operates on the foundation of OpenAI’s Codex language model. This model is trained on both natural language and a broad database of public code, allowing it to offer insightful suggestions. You should write less code and construct more.
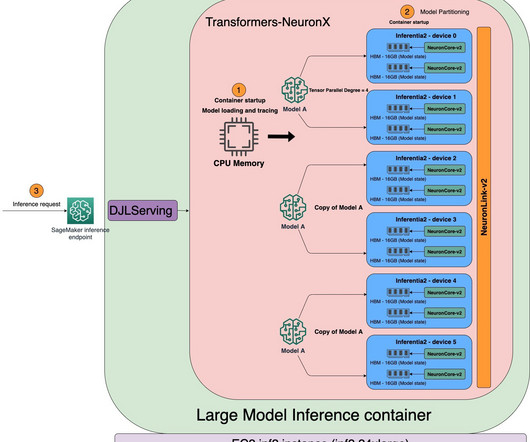
In this post, we demonstrate how to optimize hosting DeepSeek-R1 distilled models with Hugging Face Text Generation Inference (TGI) on Amazon SageMaker AI. Model Variants The current DeepSeek model collection consists of the following models: DeepSeek-V3 An LLM that uses a Mixture-of-Experts (MoE) architecture.
Engineered to enable developers to produce superior code with greater efficiency, Copilot operates on the foundation of OpenAI’s Codex language model. This model is trained on both natural language and a broad database of public code, allowing it to offer insightful suggestions. You should write less code and construct more.
One of the significant challenges in AI processing is the efficient utilization of hardware resources such as GPUs. To tackle this challenge, Forethought uses SageMaker multi-model endpoints (MMEs) to run multiple AImodels on a single inference endpoint and scale. 2xlarge instances. These particular instances offer 15.5
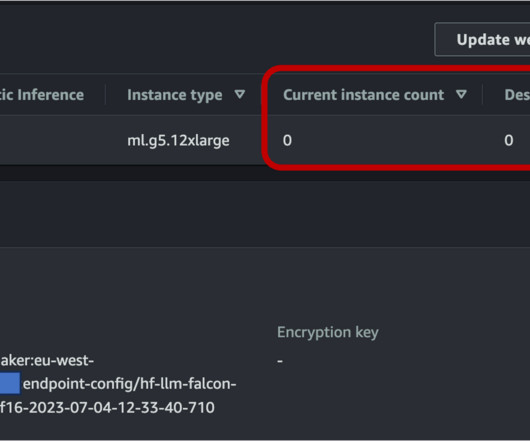
These customers are looking into foundation models, such as TII Falcon, Stable Diffusion XL, or OpenAI’s GPT-3.5, as the engines that power the generative AI innovation. To make sure that our endpoint can scale down to zero, we need to configure auto scaling on the asynchronous endpoint using Application Auto Scaling.
Salesforce Einstein is a set of AI technologies that integrate with Salesforce’s Customer Success Platform to help businesses improve productivity and client engagement. These models are designed to provide advanced NLP capabilities for various business applications.
Some of the most effective techniques include: Quantization : This reduces the numerical precision of model parameters while maintaining high accuracy, effectively speeding up inference. Kernel Auto-tuning : TensorRT automatically selects the best kernel for each operation, optimizing inference for a given GPU. build/tensorrt_llm*.whl
Limited options for auto-QA Many companies use automated QA (auto QA) services to monitor customer interactions. However, this is a relatively small market with limited solutions, and most auto-QA tools fail to deliver actionable results. Level AI offers QA-GPT , a powerful QA auditor you can tailor to your exact business.
At the highest level we were using AI and machine learning to detect events as they happen around the world. and NLP to determine what people were talking about. Is the foundation of summaries, agent coaching, auto qualification, to name a few. You’re also known for your comparisons between AI and your car racing.
The world of artificial intelligence (AI) and machine learning (ML) has been witnessing a paradigm shift with the rise of generative AImodels that can create human-like text, images, code, and audio. Compared to classical ML models, generative AImodels are significantly bigger and more complex.
Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. This results in faster restarts and workload completion. Prerequisites You need to complete some prerequisites before you can run the first notebook.
Amazon Bedrock provides a broad range of high-performing foundation models from Amazon and other leading AI companies, including Anthropic , AI21 , Meta , Cohere , and Stability AI , and covers a wide range of use cases, including text and image generation, searching, chat, reasoning and acting agents, and more.
Faster deployment With domain adaptation, specialized AImodels can be developed and deployed more quickly, accelerating time to market for AI-powered solutions. AWS has been at the forefront of domain adaptation, creating a framework to allow creating powerful, specialized AImodels.
Despite the great generalization capabilities of these models, there are often use cases that have very specific domain data (such as healthcare or financial services), because of which these models may not be able to provide good results for these use cases. With this dataset, input consists of a CSV, JSON, or TXT file.
What is the Falcon 2 11B model Falcon 2 11B is the first FM released by TII under their new artificial intelligence (AI) model series Falcon 2. It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5
Complete the following steps to edit an existing space: On the space details page, choose Stop space. To start using Amazon CodeWhisperer, make sure that the Resume Auto-Suggestions feature is activated. Choose Create JupyterLab space. For Name , enter a name for your Space. Choose Create space. Choose Run space to relaunch the space.
Furthermore, the CPUUtilization metric shows a classic pattern of periodic high and low CPU demand, which makes this endpoint a good candidate for auto scaling. For information, see Automatically Scale Amazon SageMaker Models. If all are successful, then the batch transform job is marked as complete.
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. What are Large Language Models (LLMs)?
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. The way you craft a prompt can profoundly influence the nature and usefulness of the AI’s response.
An example is a privacy-preserving solution for developing healthcare AImodels. Visual synthetic data involves artificially generated images to enhance ML models’ training by providing diverse and privacy-conscious datasets – source. 1: Variational Auto-Encoder. Technique No.1:
Sparked by the release of large AImodels like AlexaTM , GPT , OpenChatKit , BLOOM , GPT-J , GPT-NeoX , FLAN-T5 , OPT , Stable Diffusion , and ControlNet , the popularity of generative AI has seen a recent boom. A complete example that illustrates the no-code option can be found in the following notebook.
If you want to scale up your projects or even simply use more powerful AImodels, you need more resources. We’ll explore how leveraging serverless GPU computing opens up new possibilities for you and your AI applications.
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive language model developed on a sophisticated transformer foundation. Its model parameters scale from an impressive 7 billion to a remarkable 70 billion. The complete example is shown in the accompanying notebook.
For our question-answering task, that’s a sequence-to-sequence format: The model receives a sequence of tokens as the input and produces a sequence of tokens as the output. Last, we’ll shuffle the dataset to ensure the model sees it in randomized order. This helps in training large AImodels, even on computers with little memory. <pre
Build vs. open-source : which conversational AImodel should you choose? Stephen: It seems like a lot of models and sequences. But it’s absolutely critical for most people in our space that you do some type of auto-scaling. How do you ensure data quality when building NLP products? Now, we’re not perfect.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. There’s some degree of conceptual understanding that can be awarded to large language models. The largest one, the Pathways language model, is 540 billion parameters.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. There’s some degree of conceptual understanding that can be awarded to large language models. The largest one, the Pathways language model, is 540 billion parameters.
NVIDIA NeMo Framework NVIDIA NeMo is an end-to-end cloud-centered framework for training and deploying generative AImodels with billions and trillions of parameters at scale. NVIDIA NeMo simplifies generative AImodel development, making it more cost-effective and efficient for enterprises.
This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation. You can now configure your scaling policies to include scaling to zero, allowing for more precise management of your AI inference infrastructure.
Technical Deep Dive of Llama 2 For training the Llama 2 model; like its predecessors, it uses an auto-regressive transformer architecture , pre-trained on an extensive corpus of self-supervised data. Much like LLaMa 2, InstructGPT also leverages these advanced training techniques to optimize its model's performance.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
This satisfies the strong MME demand for deep neural network (DNN) models that benefit from accelerated compute with GPUs. These include computer vision (CV), natural language processing (NLP), and generative AImodels. There are two notebooks provided in the repo: one for load testing CV models and another for NLP.
From self-driving cars to language models that can engage in human-like conversations, AI is rapidly transforming various industries, and software development is no exception. Described as an AI-powered programming companion, it presents auto-complete suggestions during code development.
Courtesy of NOMIC for OBELICS, HuggingFaceM4 for IDEFICS, Charles Bensimon for Gradio and Amazon Polly for TTS In this post, we explore the technical nuances of VLP prototyping using Amazon SageMaker JumpStart in conjunction with contemporary generative AImodels. Implement an agent tree of thoughts model into the reasoning pipeline.
Organizations are looking to accelerate the process of building new AI solutions. They use fully managed services such as Amazon SageMaker AI to build, train and deploy generative AImodels. Oftentimes, they also want to integrate their choice of purpose-built AI development tools to build their models on SageMaker AI.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content