This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The company is constantly shipping new updates and improvements for its numerous Speech AImodels, including speech recognition, streaming speech-to-text, summarization, content moderation, sentiment analysis, and more.
Future AGIs proprietary technology includes advanced evaluation systems for text and images, agent optimizers, and auto-annotation tools that cut AI development time by up to 95%. Enterprises can complete evaluations in minutes, enabling AI systems to be optimized for production with minimal manual effort.
BlueFlame AI offers an AI-native, purpose-built, and LLM-agnostic solution designed for alternative investment managers. First off, understanding where your data is going and how it's being protected is paramount with LLM providers being hosted solutions. Youve emphasized BlueFlame AIsLLM-agnostic approach.
Multi-Model Support: Supports multiple AImodels for flexibility in choosing the right model for specific tasks. Customizable AI Workforce: Build and manage an entire AI workforce in one visual platform. .” These triggers are how you give your AI Agents tasks to complete.
Using Automatic Speech Recognition (also known as speech to text AI , speech AI, or ASR), companies can efficiently transcribe speech to text at scale, completing what used to be a laborious process in a fraction of the time. And that’s just a glimpse of what’s possible. Content management 2.
It is critical for AImodels to capture not only the context, but also the cultural specificities to produce a more natural sounding translation. One of LLMs most fascinating strengths is their inherent ability to understand context. However, the industry is seeing enough potential to consider LLMs as a valuable option.
And GeForce RTX and NVIDIA RTX GPUs, which are packed with dedicated AI processors called Tensor Cores, are bringing the power of generative AI natively to more than 100 million Windows PCs and workstations. This follows the announcement of TensorRT-LLM for data centers last month.
Auto-generated code suggestions can increase developers’ productivity and optimize their workflow by providing straightforward answers, handling routine coding tasks, reducing the need to context switch and conserving mental energy. How does generative AI code generation work?
As the demand for large language models (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. NVIDIA's TensorRT-LLM steps in to address this challenge by providing a set of powerful tools and optimizations specifically designed for LLM inference.
Its been gradual, but generative AImodels and the apps they power have begun to measurably deliver returns for businesses. Organizations across many industries believe their employees are more productive and efficient with AI tools such as chatbots and coding assistants at their side.
Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction. These LLMs can perform various NLP operations, including data extraction. Image and Document Processing Multimodal LLMs have completely replaced OCR.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced large language model (LLM) distinguished by its innovative, multi-stage training process. The model employs a chain-of-thought (CoT) approach that systematically breaks down complex queries into clear, logical steps.
OpenAI has been instrumental in developing revolutionary tools like the OpenAI Gym, designed for training reinforcement algorithms, and GPT-n models. The spotlight is also on DALL-E, an AImodel that crafts images from textual inputs. Generative models like GPT-4 can produce new data based on existing inputs.
AI can be thought of as the ability for a device to perform tasks autonomously, by ingesting and analyzing enormous amounts of data, then recognizing patterns in that data — often referred to as being “trained.” For this reason, AI is broadly seen as both disruptive and highly transformational. It’s up to 4.5x faster on RTX vs. Mac.
These technologies together enable NVIDIA Avatar Cloud Engine , or ACE, and multimodal language models to work together with the NVIDIA DRIVE platform to let automotive manufacturers develop their own intelligent in-car assistants. Li Auto unveiled its multimodal cognitive model, Mind GPT, in June.
Botpress Botpress is an open-sourceorigin platform and one of the most developer-friendly options for building AI chatbots and virtual agents. It provides a complete toolkit to design, train, and deploy AI-driven support bots, harnessing the latest in large language models (LLMs). Visit Dante 4.
For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generating complete results seamlessly in 0.5–3 In this post, we share how Rad AI reduced real-time inference latency by 50% using Amazon SageMaker. 3 seconds, with minimal latency.
Generative AI has the potential to significantly disrupt customer care, leveraging large language models (LLMs) and deep learning techniques designed to understand complex inquiries and offer to generate more human-like conversational responses.
FMs and LLMs, even though they’re pre-trained, can continue to learn from data inputs or prompts during inference. A prompt is the information you pass into an LLM to elicit a response. This includes task context, data that you pass to the model, conversation and action history, instructions, and even examples.
They are committed to enhancing the performance and capabilities of AImodels, with a particular focus on large language models (LLMs) for use with Einstein product offerings. These models are designed to provide advanced NLP capabilities for various business applications.
ACE microservices allow developers to integrate state-of-the-art generative AImodels into digital avatars in games and applications. NPCs tap up to four AImodels to hear, process, generate dialogue and respond. With ACE microservices, NPCs can dynamically interact and converse with players in-game and in real time.
If you want to scale up your projects or even simply use more powerful AImodels, you need more resources. In this article, we will explore beam.cloud , an easy and powerful swiss-army-knife for running LLMs and code directly on the cloud. I don’t even have an Nvidia GPU so I am stuck with my 16 GB of RAM and my CPU.
This post showcases a reward modeling technique to efficiently customize LLMs for an organization by programmatically defining rewards functions that capture preferences for model behavior. We demonstrate an approach to deliver LLM results tailored to an organization without intensive, continual human judgement.
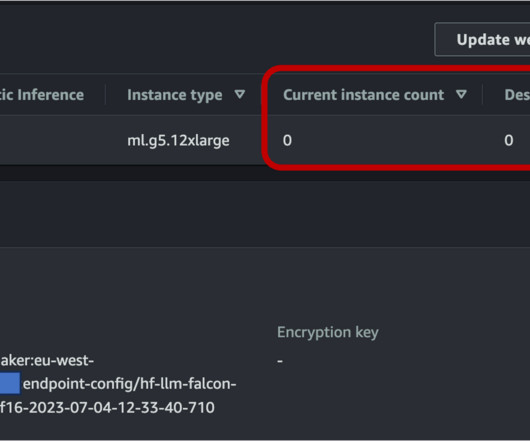
These customers are looking into foundation models, such as TII Falcon, Stable Diffusion XL, or OpenAI’s GPT-3.5, as the engines that power the generative AI innovation. To make sure that our endpoint can scale down to zero, we need to configure auto scaling on the asynchronous endpoint using Application Auto Scaling.
Open Data Science Blog Recap Paris-based Mistral AI is emerging as a formidable challenger to industry giants like OpenAI and Anthropic. Auto Prompt is a prompt optimization framework designed to enhance and perfect your prompts for real-world use cases and automatically generates high-quality, detailed prompts tailored to user intentions.
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive language model developed on a sophisticated transformer foundation. Its model parameters scale from an impressive 7 billion to a remarkable 70 billion. In this post, we explore best practices for prompting the Llama 2 Chat LLM.
With AI-powered analysis, the process of reviewing an average file of a few hundred pages is reduced to minutes with Discovery Navigator. It employs sophisticated AI to extract medical information from records, providing users with structured information that can be easily reviewed and uploaded into their claims management system.
Hallucinations – LLMs have a remarkable ability to respond to natural language, and clearly encode significant amounts of knowledge. An LLM doesn’t model facts so much as it models language. Legal research is a critical area for Thomson Reuters customers—it needs to be as complete as possible. 55 440 0.1
Marketing optimization: One of the major advantages of AI-powered call insights is the ease of integrating it with different systems, including CRM platforms like HubSpot and various marketing automation tools. hours of english audio data LeMUR – LLM utilized to analyze spoken data.
Today, generative AImodels cover a variety of tasks from text summarization, Q&A, and image and video generation. Fine-tuning allows you to adjust these generative AImodels to achieve improved performance on your domain-specific tasks. The code is provided by the model authors in the repo.
What is the Falcon 2 11B model Falcon 2 11B is the first FM released by TII under their new artificial intelligence (AI) model series Falcon 2. It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5
Imagine you’re facing the following challenge: you want to develop a Large Language Model (LLM) that can proficiently respond to inquiries in Portuguese. You have a valuable dataset and can choose from various base models. We will fine-tune different foundation LLMmodels on a dataset, evaluate them, and select the best model.
Llama2 by Meta is an example of an LLM offered by AWS. Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. This results in faster restarts and workload completion.
Faster deployment With domain adaptation, specialized AImodels can be developed and deployed more quickly, accelerating time to market for AI-powered solutions. AWS has been at the forefront of domain adaptation, creating a framework to allow creating powerful, specialized AImodels.
The world of artificial intelligence (AI) and machine learning (ML) has been witnessing a paradigm shift with the rise of generative AImodels that can create human-like text, images, code, and audio. Compared to classical ML models, generative AImodels are significantly bigger and more complex.
Complete the following steps to edit an existing space: On the space details page, choose Stop space. To start using Amazon CodeWhisperer, make sure that the Resume Auto-Suggestions feature is activated. Choose Create JupyterLab space. For Name , enter a name for your Space. Choose Create space. Choose Run space to relaunch the space.
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. This adaptation is facilitated through the use of LLM prompts. For Secret type , choose Other type of secret.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the completemodel lineage with data/models/experiments used downstream? The platform’s labeling capabilities include flexible label function creation, auto-labeling, active learning, and so on.
The session highlighted the “last mile” problem in AI applications and emphasized the importance of data-centric approaches in achieving production-level accuracy. Mann’s formal education in machine learning, he said, came during a time when you optimized a model against a test set.
The session highlighted the “last mile” problem in AI applications and emphasized the importance of data-centric approaches in achieving production-level accuracy. Mann’s formal education in machine learning, he said, came during a time when you optimized a model against a test set.
Some original Tesla features are embedded into the robot, such as a self-running computer, autopilot cameras, a set of AI tools, neural network planning , auto-labeling for objects, etc. The data from multiple sensors are combined and processed to create a complete understanding of the environment.
What are Large Language Models (LLMs)? Large language models (LLMs) are precisely that – advanced AImodels designed to process, understand, and generate natural language in a way that mimics human cognitive capabilities. and GPT-4, marked a significant advancement in the field of large language models.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Others, toward language completion and further downstream tasks.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Others, toward language completion and further downstream tasks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content