This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our customers are working on a wide range of applications, including augmented and virtual reality, computer vision , conversational AI, generative AI, search relevance and speech and naturallanguageprocessing (NLP), among others. What is your vision for how LXT can accelerate AI efforts for different clients?
The retrieval component uses Amazon Kendra as the intelligent search service, offering naturallanguageprocessing (NLP) capabilities, machine learning (ML) powered relevance ranking, and support for multiple data sources and formats.
This calls for the organization to also make important decisions regarding data, talent and technology: A well-crafted strategy will provide a clear plan for managing, analyzing and leveraging data for AI initiatives. Research AI use cases to know where and how these technologies are being applied in relevant industries.
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in naturallanguageprocessing. Key Takeaways The Pile dataset is an 800GB open-source resource designed for AI research and LLM training. Who Created the Pile Dataset and Why?
There are major growth opportunities in both the model builders and companies looking to adopt generative AI into their products and operations. We feel we are just at the beginning of the largest AI wave. Dataquality plays a crucial role in AI model development.
Whether youre new to AIdevelopment or an experienced practitioner, this post provides step-by-step guidance and code examples to help you build more reliable AI applications. Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
Training artificial intelligence (AI) models often requires massive amounts of labeled data. It can be highly expensive and time-consuming, especially for complex tasks like image recognition or naturallanguageprocessing. Annotating data is similar to finding a specific grain of sand on a beach.
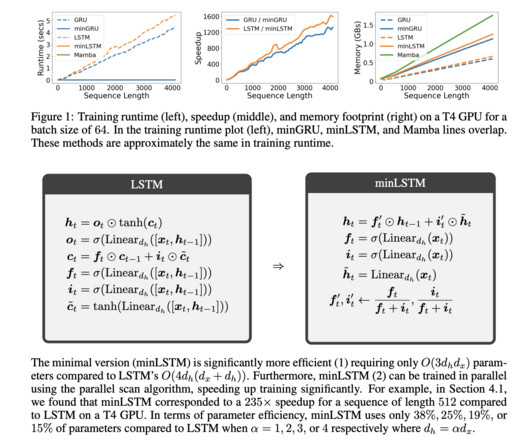
Recurrent neural networks (RNNs) have been foundational in machine learning for addressing various sequence-based problems, including time series forecasting and naturallanguageprocessing. indicating strong results across varying levels of dataquality. while the minGRU scored 79.4, Let’s collaborate!
Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence. Python’s simplicity, versatility, and extensive library support make it the go-to language for AIdevelopment. Python’s strength in AIdevelopment lies in its rich ecosystem of libraries.
Generative AI for Financial Services According to a recent NVIDIA survey , the top AI use cases in the financial services industry are customer services and deep analytics, where naturallanguageprocessing and LLMs are used to better respond to customer inquiries and uncover investment insights.
Large language models (LLMs) have revolutionized naturallanguageprocessing and artificial intelligence, enabling a variety of downstream tasks. However, most advanced models focus predominantly on English and a limited set of high-resource languages, leaving many European languages underrepresented.
Some may choose to experiment with non-traditional data sources like digital footprints or recurring streaming payments to predict repayment behavior. How foundation models jumpstart AIdevelopment Foundation models (FMs) represent a massive leap forward in AIdevelopment.
NaturalLanguageProcessing (NLP) models rely heavily on bias to function effectively. In fact, a certain degree of bias is essential for these models to make accurate predictions and decisions based on patterns within the data they have been trained on.
Some may choose to experiment with non-traditional data sources like digital footprints or recurring streaming payments to predict repayment behavior. How foundation models jumpstart AIdevelopment Foundation models (FMs) represent a massive leap forward in AIdevelopment.
Dive into the real-world applications of Generative AI, from hyper-accurate demand forecasting to dynamic logistics optimization and proactive risk mitigation, and explore how this cutting-edge technology is slashing costs, boosting revenues, and enhancing agility for businesses across industries with concrete code examples.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Naturallanguageprocessing to extract key information quickly. However, banks may encounter roadblocks when integrating AI into their complaint-handling process.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Naturallanguageprocessing to extract key information quickly. However, banks may encounter roadblocks when integrating AI into their complaint-handling process.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Naturallanguageprocessing to extract key information quickly. However, banks may encounter roadblocks when integrating AI into their complaint-handling process.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Naturallanguageprocessing to extract key information quickly. However, banks may encounter roadblocks when integrating AI into their complaint-handling process.
Some may choose to experiment with non-traditional data sources like digital footprints or recurring streaming payments to predict repayment behavior. How foundation models jumpstart AIdevelopment Foundation models (FMs) represent a massive leap forward in AIdevelopment.
Presenters from various spheres of AI research shared their latest achievements, offering a window into cutting-edge AIdevelopments. In this article, we delve into these talks, extracting and discussing the key takeaways and learnings, which are essential for understanding the current and future landscapes of AI innovation.
DataQuality and Processing: Meta significantly enhanced their data pipeline for Llama 3.1: models for enhanced security Sample Applications: Developed reference implementations for common use cases (e.g., DataQuality and Processing: Meta significantly enhanced their data pipeline for Llama 3.1:
While each of them offers exciting perspectives for research, a real-life product needs to combine the data, the model, and the human-machine interaction into a coherent system. AIdevelopment is a highly collaborative enterprise. Market alignment : Prioritize market opportunities and customer needs to guide AIdevelopment.
Training algorithm of Generative Adversarial Network (GAN) for creating synthetic data – source. Applications of Synthetic Data in Artificial Intelligence and Machine Learning Synthetic data can train and test models for computer vision (CV), naturallanguageprocessing (NLP), speech recognition, and more.
I’m excited today to be talking about DataPerf, which is about building benchmarks for data-centric AIdevelopment. Why are benchmarks critical for accelerating development in any particular space? Fundamentally, there are only three really primary pillars in the context of measuring dataquality.
I’m excited today to be talking about DataPerf, which is about building benchmarks for data-centric AIdevelopment. Why are benchmarks critical for accelerating development in any particular space? Fundamentally, there are only three really primary pillars in the context of measuring dataquality.
However, those models still hold drawbacks, things like font, language, and format are big challenges for OCR models. Content Summarization Computer vision (CV) and NaturalLanguageProcessing can provide further abilities to the visually impaired.
After your generative AI workload environment has been secured, you can layer in AI/ML-specific features, such as Amazon SageMaker Data Wrangler to identify potential bias during data preparation and Amazon SageMaker Clarify to detect bias in ML data and models.
This move was vital in reducing development costs and encouraging innovation. The momentum continued in 2017 with the introduction of transformer models like BERT and GPT, which revolutionized naturallanguageprocessing. These models made AI tasks more efficient and cost-effective.
They can help you with: Dataquality audits Building data systems and pipelines Custom AIdevelopment services Machine learning consulting Beyond their artificial intelligence expertise, the team values its people-centric approach, communicating between themselves and with the client, ensuring every project exceeds expectations.
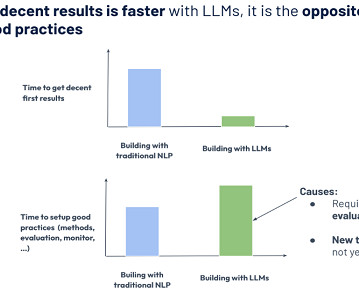
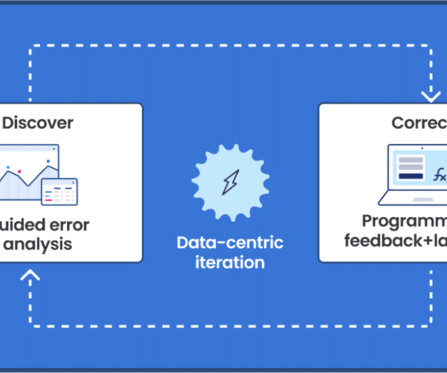
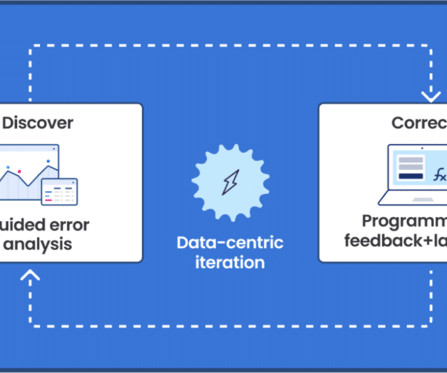
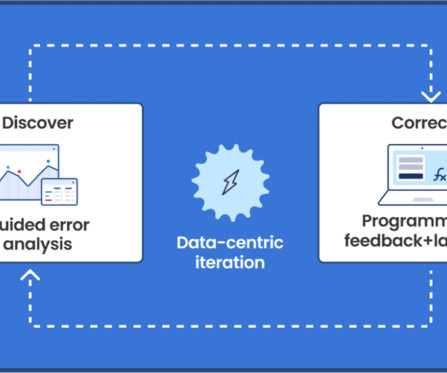
AIDevelopment Lifecycle: Learnings of What Changed with LLMs Noé Achache | Engineering Manager & Generative AI Lead | Sicara Using LLMs to build models and pipelines has made it incredibly easy to build proof of concepts, but much more challenging to evaluate the models. billion customer interactions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











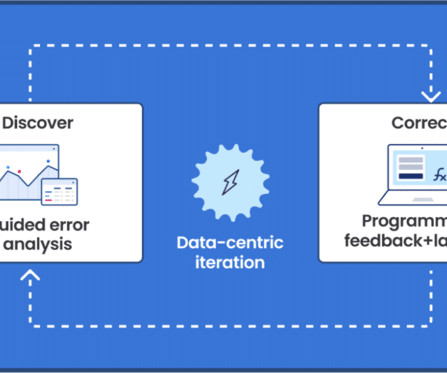

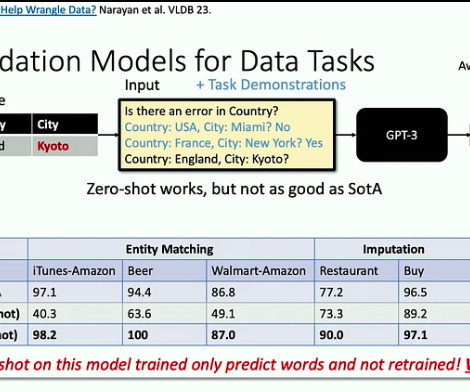
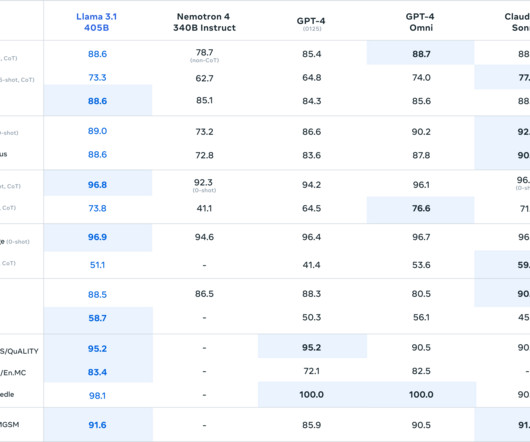
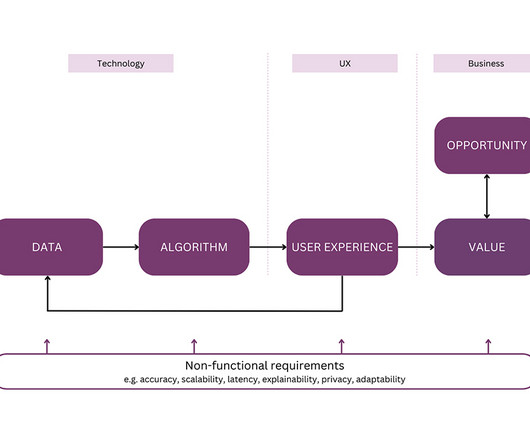











Let's personalize your content