This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
On the other hand, well-structured data allows AI systems to perform reliably even in edge-case scenarios , underscoring its role as the cornerstone of modern AIdevelopment. Then again, achieving high-quality data is not without its challenges.
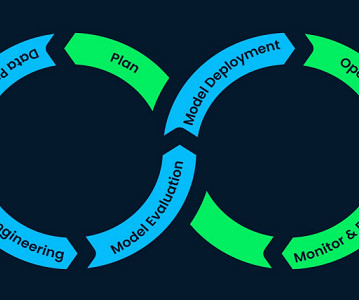
Stages Of AI Feedback Loops A high-level illustration of feedback mechanism in AI models. Source Understanding how AI feedback loops work is significant to unlock the whole potential of AIdevelopment. Let's explore the various stages of AI feedback loops below.
This problem often stems from inadequate user value, underwhelming performance, and an absence of robust best practices for building and deploying LLM tools as part of the AIdevelopment lifecycle. For instance: Data Preparation: GoogleSheets. Model Engineering: DVC (Data Version Control). Evaluation: Tools likeNotion.
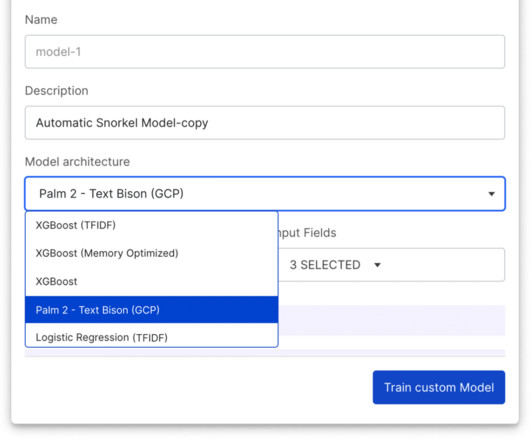
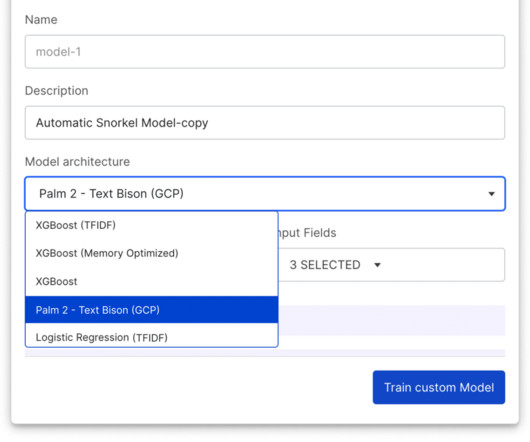
This new guided workflow is designed to ensure success for your AI use case, regardless of complexity, catering to both seasoned data scientists and those just beginning their journey. While creating your app, you’ll receive a preview of your dataset, allowing you to identify and correct critical data errors early.
This new guided workflow is designed to ensure success for your AI use case, regardless of complexity, catering to both seasoned data scientists and those just beginning their journey. While creating your app, you’ll receive a preview of your dataset, allowing you to identify and correct critical data errors early.
This new guided workflow is designed to ensure success for your AI use case, regardless of complexity, catering to both seasoned data scientists and those just beginning their journey. While creating your app, you’ll receive a preview of your dataset, allowing you to identify and correct critical data errors early.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
This time-consuming, labor-intensive process is costly – and often infeasible – when enterprises need to extract insights from volumes of complex data sources or proprietary data requiring specialized knowledge from clinicians, lawyers, financial analysis or other internal experts.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
The MLOps command center gives you a birds-eye view of your model, monitoring key metrics like accuracy and datadrift. Teams can also build AI apps without writing code and collaborate within a single system of record, setting up user permissions and governance.
Continuous Improvement: Data scientists face many issues after model deployment like performance degradation, datadrift, etc. By understanding what goes under the hood with Explainable AI, data teams are better equipped to improve and maintain model performance, and reliability.
Additionally, the vendor neutrality of open-source AI ensures organizations aren’t tied to a specific vendor. While open-source AI offers enticing possibilities, its free accessibility poses risks that organizations must navigate carefully.
In order to protect people from the potential harms of AI, some regulators in the United States and European Union are increasingly advocating for controls and checks and balances on the power of open-source AI models. One way to identify bias is to audit the data used to train the model.
They use fully managed services such as Amazon SageMaker AI to build, train and deploy generative AI models. Oftentimes, they also want to integrate their choice of purpose-built AIdevelopment tools to build their models on SageMaker AI. This increases the time it takes for customers to go from data to insights.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content