
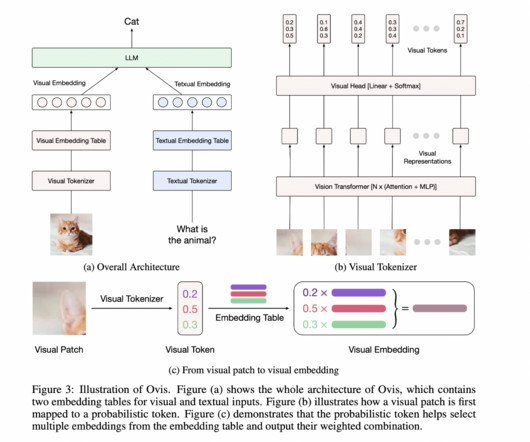
Ovis-1.6: An Open-Source Multimodal Large Language Model (MLLM) Architecture Designed to Structurally Align Visual and Textual Embeddings
Marktechpost
SEPTEMBER 29, 2024
Artificial intelligence (AI) is transforming rapidly, particularly in multimodal learning. Multimodal models aim to combine visual and textual information to enable machines to understand and generate content that requires inputs from both sources. to 14.1%, depending on the specific benchmark.






Let's personalize your content