
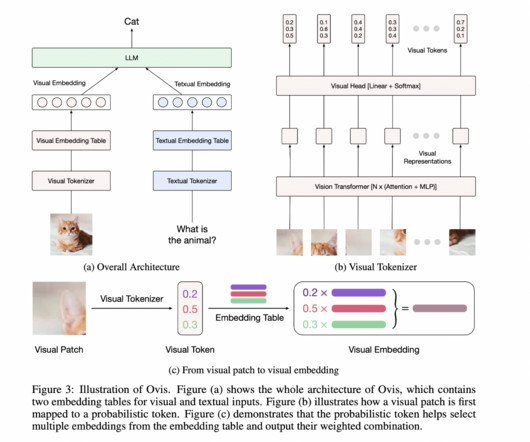
Ovis-1.6: An Open-Source Multimodal Large Language Model (MLLM) Architecture Designed to Structurally Align Visual and Textual Embeddings
Marktechpost
SEPTEMBER 29, 2024
Artificial intelligence (AI) is transforming rapidly, particularly in multimodal learning. This capability is vital for tasks such as image captioning, visual question answering, and content creation, where more than a single data mode is required. to 14.1%, depending on the specific benchmark.






Let's personalize your content