This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations are looking for AI platforms that drive efficiency, scalability, and best practices, trends that were very clear at Big Data & AI Toronto. DataRobot Booth at Big Data & AI Toronto 2022. DataRobot Fireside Chat at Big Data & AI Toronto 2022.
DataRobot DataDrift and Accuracy Monitoring detects when reality differs from the situation when the training dataset was created and the model trained. Meanwhile, DataRobot can continuously train Challenger models based on more up-to-date data. 1 IDC, MLOps – Where ML Meets DevOps, doc #US48544922, March 2022.
How do you drive collaboration across teams and achieve business value with data science projects? With AI projects in pockets across the business, data scientists and business leaders must align to inject artificial intelligence into an organization. Here are five key takeaways from one of the biggest data conferences of the year.
Monitoring Models in Production There are several types of problems that Machine Learning applications can encounter over time [4]: Datadrift: sudden changes in the features values or changes in data distribution. Model/concept drift: how, why, and when the performance of the model changes. 15, 2022. [4]
NannyML is an open-source python library that allows you to estimate post-deployment model performance (without access to targets), detect datadrift, and intelligently link datadrift alerts back to changes in model performance. 3:04 AM ∙ Nov 22, 2022 6,341 Likes 1,255 Retweets
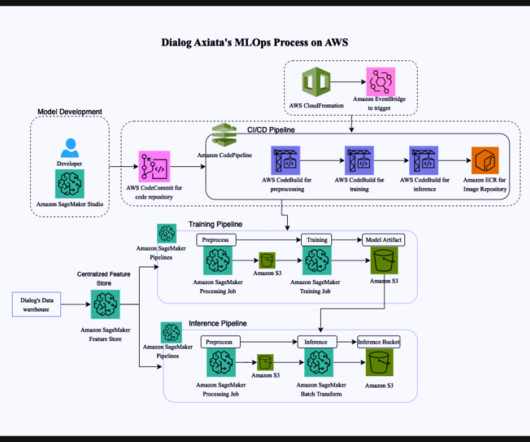
In 2022, Dialog Axiata made significant progress in their digital transformation efforts, with AWS playing a key role in this journey. The incorporation of an experiment tracking system facilitates the monitoring of performance metrics, enabling a data-driven approach to decision-making. Datadrift and model drift are also monitored.
Refreshing models according to the business schedule or signs of datadrift. Thus, you can modify a model when needed without changing the pipeline that feeds into it — providing a data science improvement without any investment in data engineering. . 10 Keys to AI Success in 2022. Download Now.
Model Observability: To be effective at monitoring and identifying model and datadrift there needs to be a way to capture and analyze the data, especially from the production system. We have implemented Azure Data Explorer (ADX) as a platform to ingest and analyze data. is modified to push the data into ADX.
Snowflake Summit 2022 (June 13-16) draws ever closer, and I believe it’s going to be a great event. A couple of sessions I’m excited about include the keynote The Engine & Platform Innovations Running the Data Cloud and learning how the frostbyte team conducts Rapid Prototyping of Industry Solutions. Telemetry feedback.
Check for model accuracy and datadrift and inspect each model from governance and service health perspectives, respectively. To see a demo on how you can leverage AI to make forecasting better, and accelerate the machine learning life cycle, please watch the full video, AI-Powered Forecasting: From Data to Consumption.
The MLOps command center gives you a birds-eye view of your model, monitoring key metrics like accuracy and datadrift. The Accuracy tab specifically shows how the model’s accuracy has changed since deployment, helping you keep track of its performance in the real-world.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. That falls into three categories of model drift, which are prediction drift, datadrift, and concept drift.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. That falls into three categories of model drift, which are prediction drift, datadrift, and concept drift.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. That falls into three categories of model drift, which are prediction drift, datadrift, and concept drift.
2022) published their research Lightweight Vehicle-Pedestrian Detection Algorithm Based on Attention Mechanism in Traffic Scenarios. 2022) published their research, MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. Moreover, the FLOPS score did not increase with the parameter number.
A look at datadrift. AI Experience 2022. By clicking on the Marketing Deployment, which has been serving predictions for a few days now, you can see an overview screen, which gives you: A top-line view on service health. A clear picture of the model’s accuracy. DataRobot Platform Overview: Solving Business Problems at Scale.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. That’s where you start to see datadrift.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. That’s where you start to see datadrift.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. That’s where you start to see datadrift.
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. How are you looking at model evaluation for cases where data adapts rapidly? Wouldn’t it take time for datadrift to be detected, labeled, and passed back to the model for training?
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. How are you looking at model evaluation for cases where data adapts rapidly? Wouldn’t it take time for datadrift to be detected, labeled, and passed back to the model for training?
This workflow will be foundational to our unstructured data-based machine learning applications as it will enable us to minimize human labeling effort, deliver strong model performance quickly, and adapt to datadrift.” – Jon Nelson, Senior Manager of Data Science and Machine Learning at United Airlines.
Data validation This step collects the transformed data as input and, through a series of tests and validators, ensures that it meets the criteria for the next component. It checks the data for quality issues and detects outliers and anomalies. Pipelines can be scheduled to carry out CI, CD, or CT.
Adaptability over time To use Text2SQL in a durable way, you need to adapt to datadrift, i. the changing distribution of the data to which the model is applied. For example, let’s assume that the data used for initial fine-tuning reflects the simple querying behaviour of users when they start using the BI system.
He presented “MLCommons and Public Datasets” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. The first question we have is, “In this conference, we learned that in the real world, the data is often drifting and label schema evolving. Peter Mattson: I think the rate of datadrift is highly problem sensitive.
He presented “MLCommons and Public Datasets” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. The first question we have is, “In this conference, we learned that in the real world, the data is often drifting and label schema evolving. Peter Mattson: I think the rate of datadrift is highly problem sensitive.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







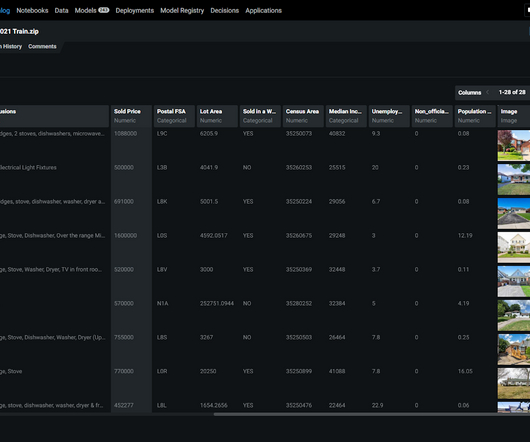




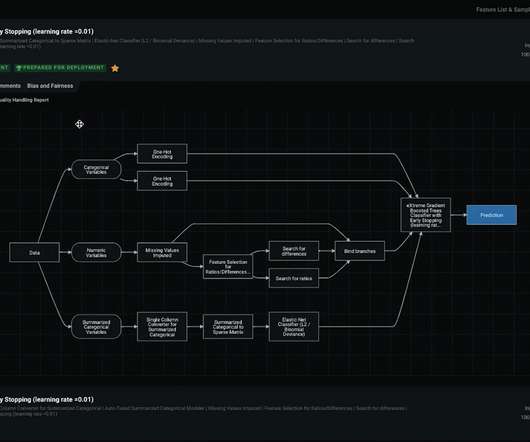
















Let's personalize your content